 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual Branch Network Towards Accurate Printed Mathematical Expression Recognition
Dec 14, 2023Over the past years, Printed Mathematical Expression Recognition (PMER) has progressed rapidly. However, due to the insufficient context information captured by Convolutional Neural Networks, some mathematical symbols might be incorrectly recognized or missed. To tackle this problem, in this paper, a Dual Branch transformer-based Network (DBN) is proposed to learn both local and global context information for accurate PMER. In our DBN, local and global features are extracted simultaneously, and a Context Coupling Module (CCM) is developed to complement the features between the global and local contexts. CCM adopts an interactive manner so that the coupled context clues are highly correlated to each expression symbol. Additionally, we design a Dynamic Soft Target (DST) strategy to utilize the similarities among symbol categories for reasonable label generation. Our experimental results have demonstrated that DBN can accurately recognize mathematical expressions and has achieved state-of-the-art performance.
Team PKU-WICT-MIPL PIC Makeup Temporal Video Grounding Challenge 2022 Technical Report
Jul 06, 2022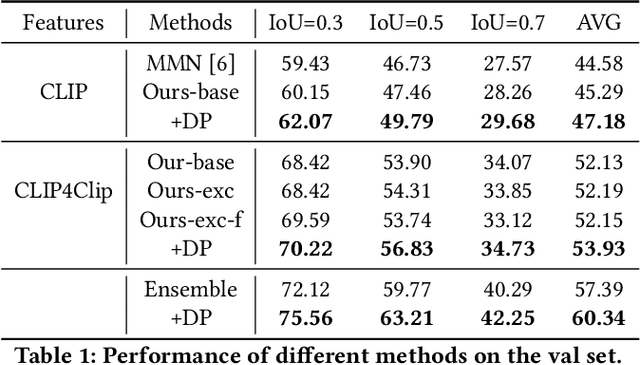
In this technical report, we briefly introduce the solutions of our team `PKU-WICT-MIPL' for the PIC Makeup Temporal Video Grounding (MTVG) Challenge in ACM-MM 2022. Given an untrimmed makeup video and a step query, the MTVG aims to localize a temporal moment of the target makeup step in the video. To tackle this task, we propose a phrase relationship mining framework to exploit the temporal localization relationship relevant to the fine-grained phrase and the whole sentence. Besides, we propose to constrain the localization results of different step sentence queries to not overlap with each other through a dynamic programming algorithm. The experimental results demonstrate the effectiveness of our method. Our final submission ranked 2nd on the leaderboard, with only a 0.55\% gap from the first.
RaDur: A Reference-aware and Duration-robust Network for Target Sound Detection
Apr 05, 2022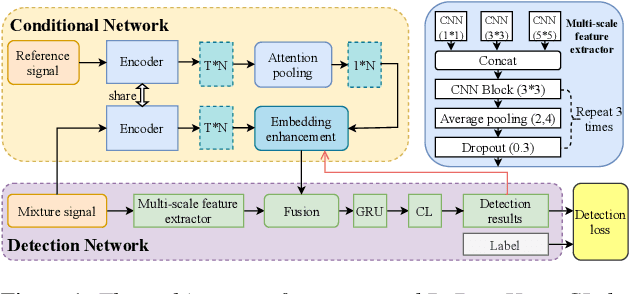
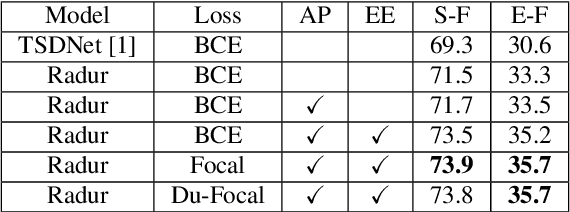
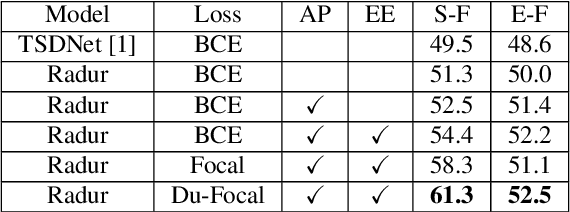
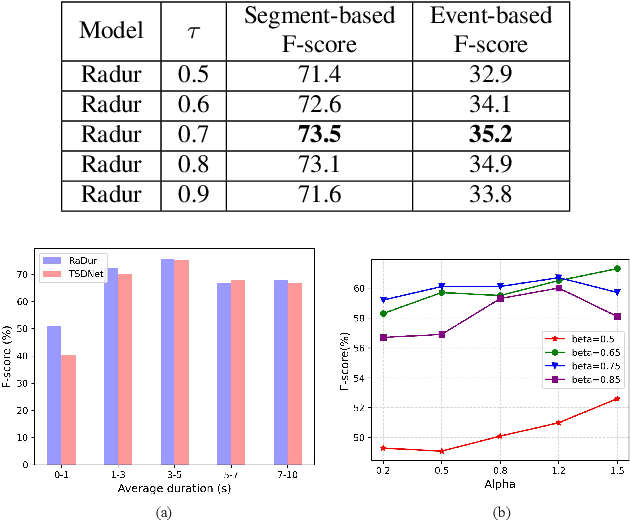
Target sound detection (TSD) aims to detect the target sound from a mixture audio given the reference information. Previous methods use a conditional network to extract a sound-discriminative embedding from the reference audio, and then use it to detect the target sound from the mixture audio. However, the network performs much differently when using different reference audios (e.g. performs poorly for noisy and short-duration reference audios), and tends to make wrong decisions for transient events (i.e. shorter than $1$ second). To overcome these problems, in this paper, we present a reference-aware and duration-robust network (RaDur) for TSD. More specifically, in order to make the network more aware of the reference information, we propose an embedding enhancement module to take into account the mixture audio while generating the embedding, and apply the attention pooling to enhance the features of target sound-related frames and weaken the features of noisy frames. In addition, a duration-robust focal loss is proposed to help model different-duration events. To evaluate our method, we build two TSD datasets based on UrbanSound and Audioset. Extensive experiments show the effectiveness of our methods.
Improving the Performance of Automated Audio Captioning via Integrating the Acoustic and Semantic Information
Oct 12, 2021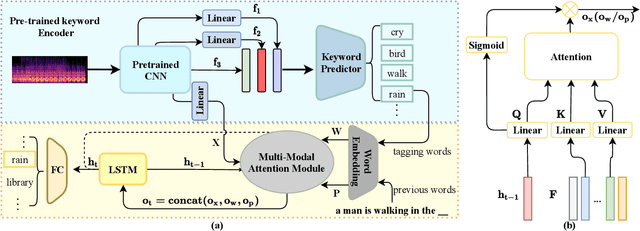
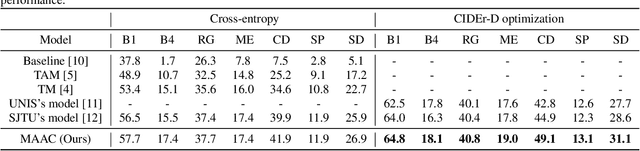
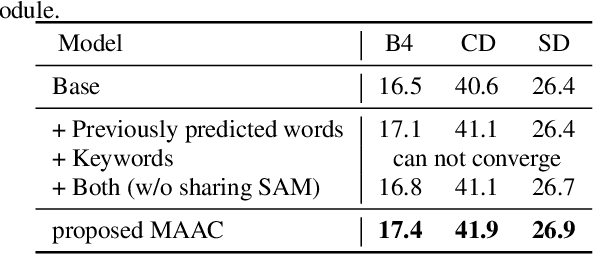
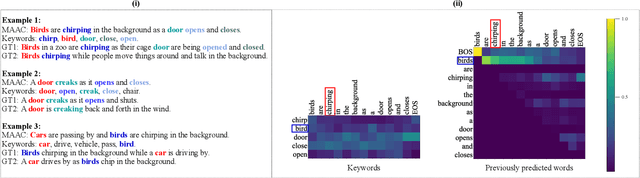
Automated audio captioning (AAC) has developed rapidly in recent years, involving acoustic signal processing and natural language processing to generate human-readable sentences for audio clips. The current models are generally based on the neural encoder-decoder architecture, and their decoder mainly uses acoustic information that is extracted from the CNN-based encoder. However, they have ignored semantic information that could help the AAC model to generate meaningful descriptions. This paper proposes a novel approach for automated audio captioning based on incorporating semantic and acoustic information. Specifically, our audio captioning model consists of two sub-modules. (1) The pre-trained keyword encoder utilizes pre-trained ResNet38 to initialize its parameters, and then it is trained by extracted keywords as labels. (2) The multi-modal attention decoder adopts an LSTM-based decoder that contains semantic and acoustic attention modules. Experiments demonstrate that our proposed model achieves state-of-the-art performance on the Clotho dataset. Our code can be found at https://github.com/WangHelin1997/DCASE2021_Task6_PKU
A Mutual learning framework for Few-shot Sound Event Detection
Oct 09, 2021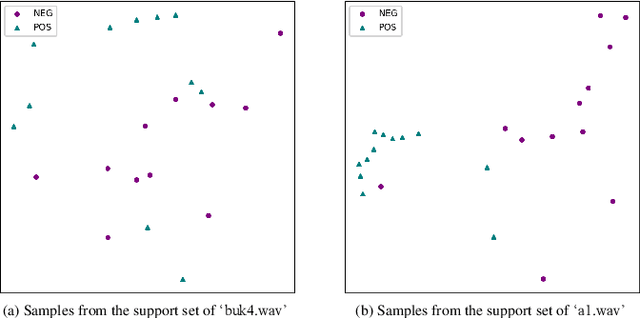
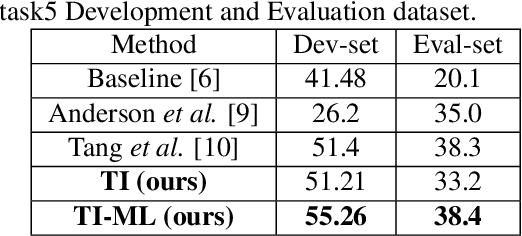
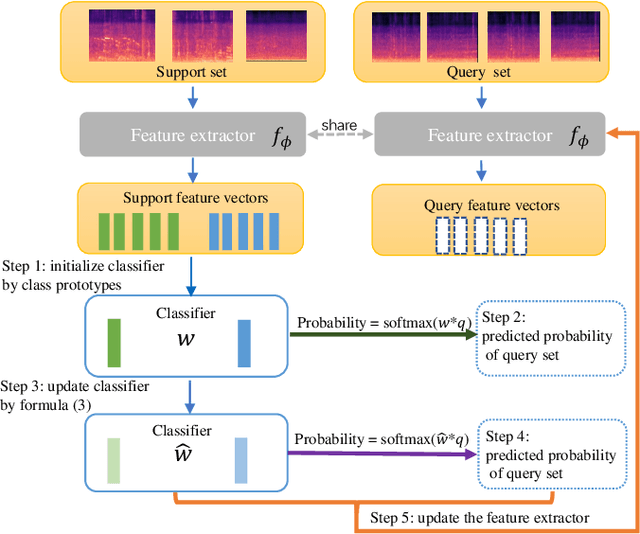
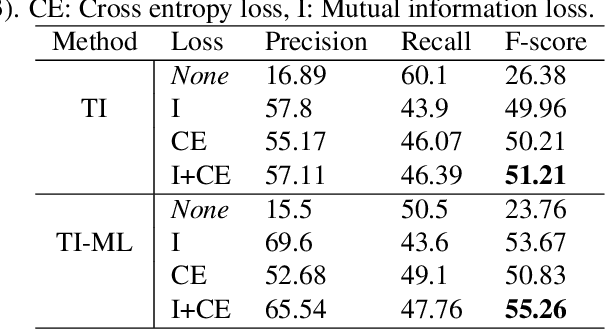
Although prototypical network (ProtoNet) has proved to be an effective method for few-shot sound event detection, two problems still exist. Firstly, the small-scaled support set is insufficient so that the class prototypes may not represent the class center accurately. Secondly, the feature extractor is task-agnostic (or class-agnostic): the feature extractor is trained with base-class data and directly applied to unseen-class data. To address these issues, we present a novel mutual learning framework with transductive learning, which aims at iteratively updating the class prototypes and feature extractor. More specifically, we propose to update class prototypes with transductive inference to make the class prototypes as close to the true class center as possible. To make the feature extractor to be task-specific, we propose to use the updated class prototypes to fine-tune the feature extractor. After that, a fine-tuned feature extractor further helps produce better class prototypes. Our method achieves the F-score of 38.4$\%$ on the DCASE 2021 Task 5 evaluation set, which won the first place in the few-shot bioacoustic event detection task of Detection and Classification of Acoustic Scenes and Events (DCASE) 2021 Challenge.