 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRaDur: A Reference-aware and Duration-robust Network for Target Sound Detection
Paper and Code
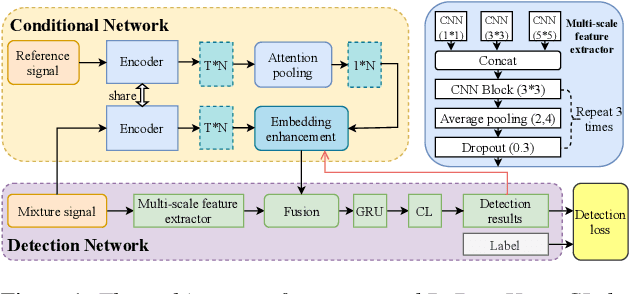
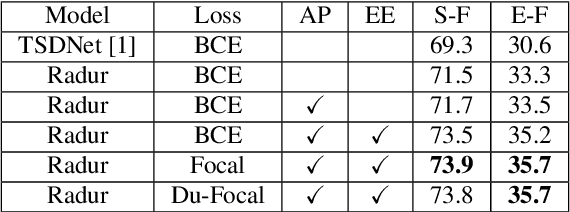
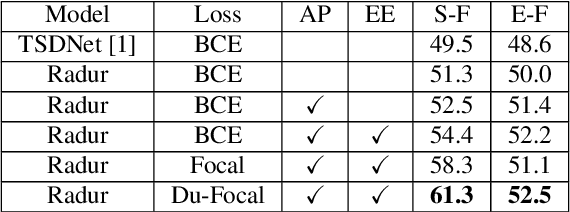
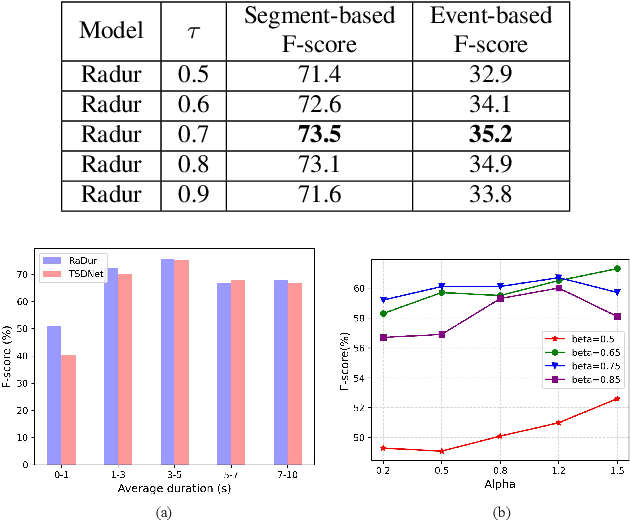
Target sound detection (TSD) aims to detect the target sound from a mixture audio given the reference information. Previous methods use a conditional network to extract a sound-discriminative embedding from the reference audio, and then use it to detect the target sound from the mixture audio. However, the network performs much differently when using different reference audios (e.g. performs poorly for noisy and short-duration reference audios), and tends to make wrong decisions for transient events (i.e. shorter than $1$ second). To overcome these problems, in this paper, we present a reference-aware and duration-robust network (RaDur) for TSD. More specifically, in order to make the network more aware of the reference information, we propose an embedding enhancement module to take into account the mixture audio while generating the embedding, and apply the attention pooling to enhance the features of target sound-related frames and weaken the features of noisy frames. In addition, a duration-robust focal loss is proposed to help model different-duration events. To evaluate our method, we build two TSD datasets based on UrbanSound and Audioset. Extensive experiments show the effectiveness of our methods.