 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking Next-Generation Reasoning-Focused Large Language Models in Ophthalmology: A Head-to-Head Evaluation on 5,888 Items
Apr 15, 2025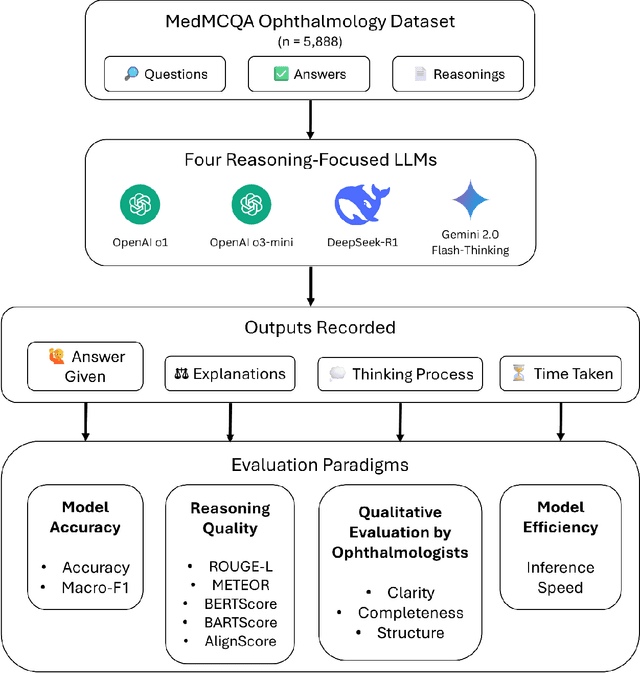
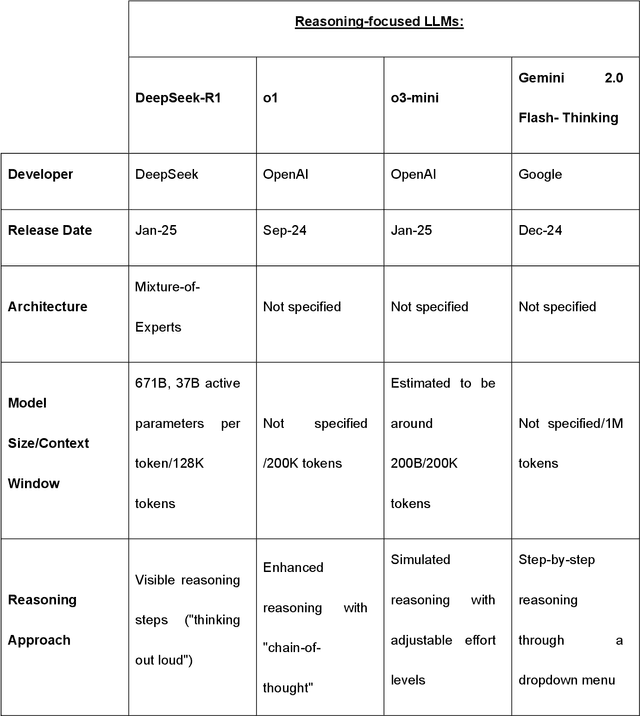
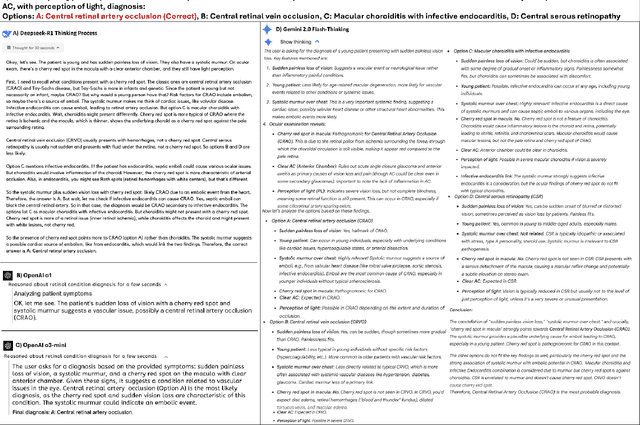
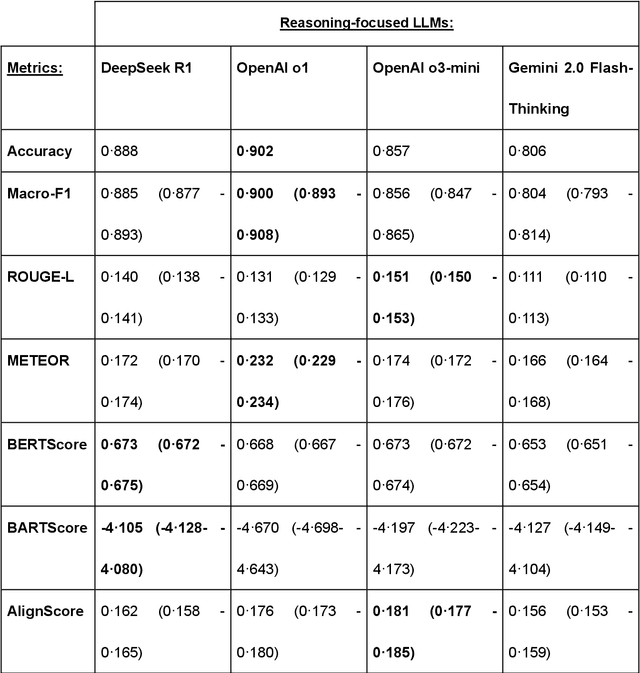
Recent advances in reasoning-focused large language models (LLMs) mark a shift from general LLMs toward models designed for complex decision-making, a crucial aspect in medicine. However, their performance in specialized domains like ophthalmology remains underexplored. This study comprehensively evaluated and compared the accuracy and reasoning capabilities of four newly developed reasoning-focused LLMs, namely DeepSeek-R1, OpenAI o1, o3-mini, and Gemini 2.0 Flash-Thinking. Each model was assessed using 5,888 multiple-choice ophthalmology exam questions from the MedMCQA dataset in zero-shot setting. Quantitative evaluation included accuracy, Macro-F1, and five text-generation metrics (ROUGE-L, METEOR, BERTScore, BARTScore, and AlignScore), computed against ground-truth reasonings. Average inference time was recorded for a subset of 100 randomly selected questions. Additionally, two board-certified ophthalmologists qualitatively assessed clarity, completeness, and reasoning structure of responses to differential diagnosis questions.O1 (0.902) and DeepSeek-R1 (0.888) achieved the highest accuracy, with o1 also leading in Macro-F1 (0.900). The performance of models across the text-generation metrics varied: O3-mini excelled in ROUGE-L (0.151), o1 in METEOR (0.232), DeepSeek-R1 and o3-mini tied for BERTScore (0.673), DeepSeek-R1 (-4.105) and Gemini 2.0 Flash-Thinking (-4.127) performed best in BARTScore, while o3-mini (0.181) and o1 (0.176) led AlignScore. Inference time across the models varied, with DeepSeek-R1 being slowest (40.4 seconds) and Gemini 2.0 Flash-Thinking fastest (6.7 seconds). Qualitative evaluation revealed that DeepSeek-R1 and Gemini 2.0 Flash-Thinking tended to provide detailed and comprehensive intermediate reasoning, whereas o1 and o3-mini displayed concise and summarized justifications.
Enhancing Large Language Models with Domain-specific Retrieval Augment Generation: A Case Study on Long-form Consumer Health Question Answering in Ophthalmology
Sep 20, 2024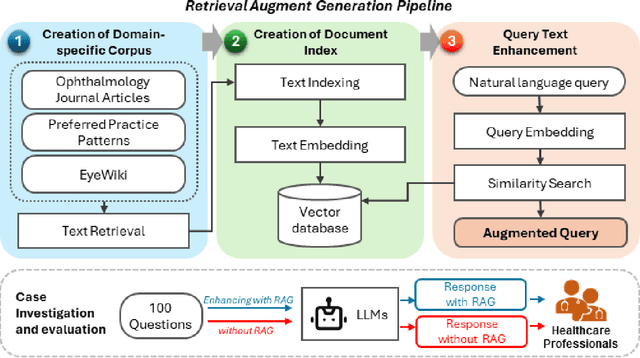

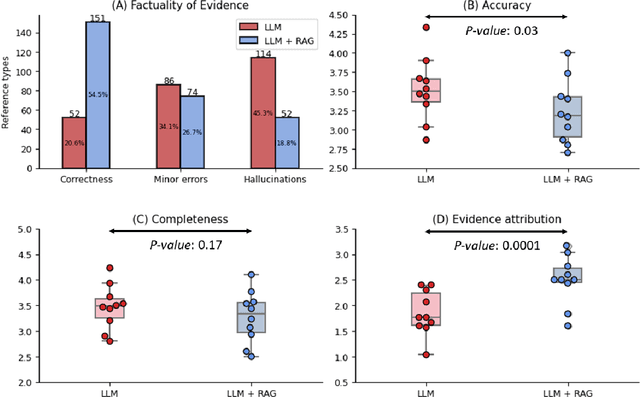

Despite the potential of Large Language Models (LLMs) in medicine, they may generate responses lacking supporting evidence or based on hallucinated evidence. While Retrieval Augment Generation (RAG) is popular to address this issue, few studies implemented and evaluated RAG in downstream domain-specific applications. We developed a RAG pipeline with 70,000 ophthalmology-specific documents that retrieve relevant documents to augment LLMs during inference time. In a case study on long-form consumer health questions, we systematically evaluated the responses including over 500 references of LLMs with and without RAG on 100 questions with 10 healthcare professionals. The evaluation focuses on factuality of evidence, selection and ranking of evidence, attribution of evidence, and answer accuracy and completeness. LLMs without RAG provided 252 references in total. Of which, 45.3% hallucinated, 34.1% consisted of minor errors, and 20.6% were correct. In contrast, LLMs with RAG significantly improved accuracy (54.5% being correct) and reduced error rates (18.8% with minor hallucinations and 26.7% with errors). 62.5% of the top 10 documents retrieved by RAG were selected as the top references in the LLM response, with an average ranking of 4.9. The use of RAG also improved evidence attribution (increasing from 1.85 to 2.49 on a 5-point scale, P<0.001), albeit with slight decreases in accuracy (from 3.52 to 3.23, P=0.03) and completeness (from 3.47 to 3.27, P=0.17). The results demonstrate that LLMs frequently exhibited hallucinated and erroneous evidence in the responses, raising concerns for downstream applications in the medical domain. RAG substantially reduced the proportion of such evidence but encountered challenges.