 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEarly Quantization Shrinks Codebook: A Simple Fix for Diversity-Preserving Tokenization
Mar 17, 2026Vector quantization is a technique in machine learning that discretizes continuous representations into a set of discrete vectors. It is widely employed in tokenizing data representations for large language models, diffusion models, and other generative models. Despite its prevalence, the characteristics and behaviors of vector quantization in generative models remain largely underexplored. In this study, we systematically investigate the issue of collapses in vector quantization, where collapsed representations are observed across discrete codebook tokens and continuous latent embeddings. By leveraging both synthetic and real datasets, we identify the severity of each type of collapses and triggering conditions. Our analysis reveals that random initialization and limited encoder capacity result in tokens collapse and embeddings collapse. Building on these findings, we propose potential solutions aimed at mitigating each collapse. To the best of our knowledge, this is the first comprehensive study examining representation collapsing problems in vector quantization.
Representation Collapsing Problems in Vector Quantization
Nov 25, 2024Vector quantization is a technique in machine learning that discretizes continuous representations into a set of discrete vectors. It is widely employed in tokenizing data representations for large language models, diffusion models, and other generative models. Despite its prevalence, the characteristics and behaviors of vector quantization in generative models remain largely underexplored. In this study, we investigate representation collapse in vector quantization - a critical degradation where codebook tokens or latent embeddings lose their discriminative power by converging to a limited subset of values. This collapse fundamentally compromises the model's ability to capture diverse data patterns. By leveraging both synthetic and real datasets, we identify the severity of each type of collapses and triggering conditions. Our analysis reveals that restricted initialization and limited encoder capacity result in tokens collapse and embeddings collapse. Building on these findings, we propose potential solutions aimed at mitigating each collapse. To the best of our knowledge, this is the first comprehensive study examining representation collapsing problems in vector quantization.
ParCo: Part-Coordinating Text-to-Motion Synthesis
Mar 27, 2024



We study a challenging task: text-to-motion synthesis, aiming to generate motions that align with textual descriptions and exhibit coordinated movements. Currently, the part-based methods introduce part partition into the motion synthesis process to achieve finer-grained generation. However, these methods encounter challenges such as the lack of coordination between different part motions and difficulties for networks to understand part concepts. Moreover, introducing finer-grained part concepts poses computational complexity challenges. In this paper, we propose Part-Coordinating Text-to-Motion Synthesis (ParCo), endowed with enhanced capabilities for understanding part motions and communication among different part motion generators, ensuring a coordinated and fined-grained motion synthesis. Specifically, we discretize whole-body motion into multiple part motions to establish the prior concept of different parts. Afterward, we employ multiple lightweight generators designed to synthesize different part motions and coordinate them through our part coordination module. Our approach demonstrates superior performance on common benchmarks with economic computations, including HumanML3D and KIT-ML, providing substantial evidence of its effectiveness. Code is available at https://github.com/qrzou/ParCo .
ILSGAN: Independent Layer Synthesis for Unsupervised Foreground-Background Segmentation
Nov 28, 2022



Unsupervised foreground-background segmentation aims at extracting salient objects from cluttered backgrounds, where Generative Adversarial Network (GAN) approaches, especially layered GANs, show great promise. However, without human annotations, they are typically prone to produce foreground and background layers with non-negligible semantic and visual confusion, dubbed "information leakage", resulting in notable degeneration of the generated segmentation mask. To alleviate this issue, we propose a simple-yet-effective explicit layer independence modeling approach, termed Independent Layer Synthesis GAN (ILSGAN), pursuing independent foreground-background layer generation by encouraging their discrepancy. Specifically, it targets minimizing the mutual information between visible and invisible regions of the foreground and background to spur interlayer independence. Through in-depth theoretical and experimental analyses, we justify that explicit layer independence modeling is critical to suppressing information leakage and contributes to impressive segmentation performance gains. Also, our ILSGAN achieves strong state-of-the-art generation quality and segmentation performance on complex real-world data.
Unsupervised Foreground-Background Segmentation with Equivariant Layered GANs
Apr 01, 2021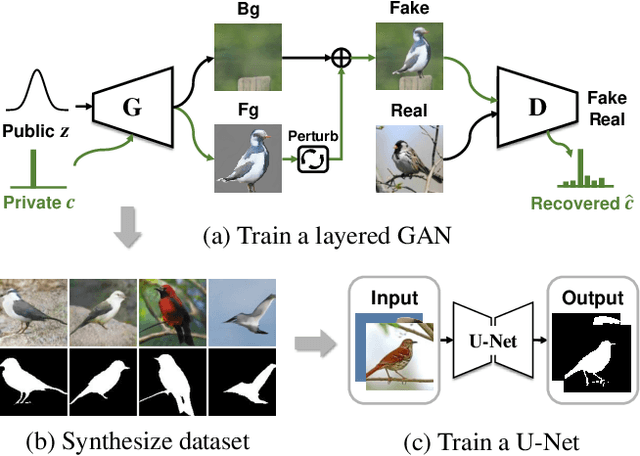
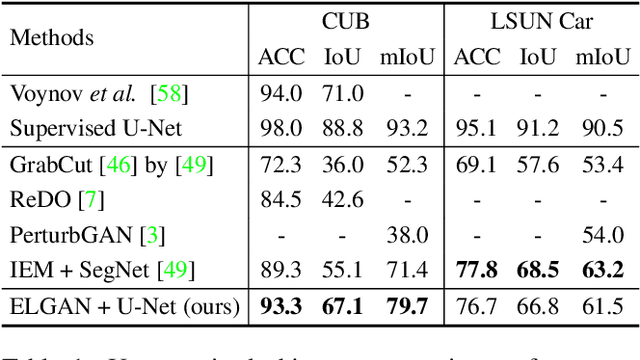
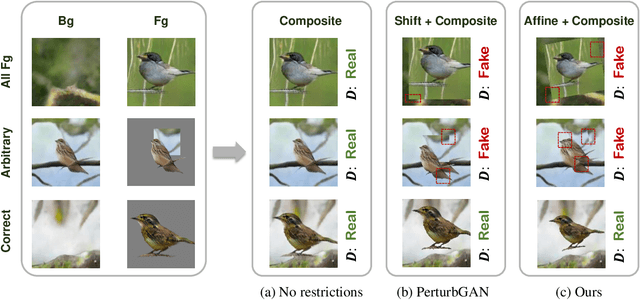
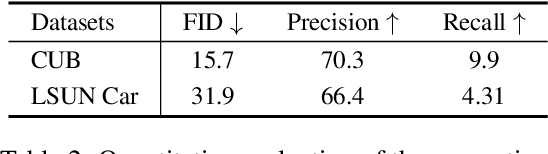
We propose an unsupervised foreground-background segmentation method via training a segmentation network on the synthetic pseudo segmentation dataset generated from GANs, which are trained from a collection of images without annotations to explicitly disentangle foreground and background. To efficiently generate foreground and background layers and overlay them to compose novel images, the construction of such GANs is fulfilled by our proposed Equivariant Layered GAN, whose improvement, compared to the precedented layered GAN, is embodied in the following two aspects. (1) The disentanglement of foreground and background is improved by extending the previous perturbation strategy and introducing private code recovery that reconstructs the private code of foreground from the composite image. (2) The latent space of the layered GANs is regularized by minimizing our proposed equivariance loss, resulting in interpretable latent codes and better disentanglement of foreground and background. Our methods are evaluated on unsupervised object segmentation datasets including Caltech-UCSD Birds and LSUN Car, achieving state-of-the-art performance.