 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeILSGAN: Independent Layer Synthesis for Unsupervised Foreground-Background Segmentation
Nov 28, 2022



Unsupervised foreground-background segmentation aims at extracting salient objects from cluttered backgrounds, where Generative Adversarial Network (GAN) approaches, especially layered GANs, show great promise. However, without human annotations, they are typically prone to produce foreground and background layers with non-negligible semantic and visual confusion, dubbed "information leakage", resulting in notable degeneration of the generated segmentation mask. To alleviate this issue, we propose a simple-yet-effective explicit layer independence modeling approach, termed Independent Layer Synthesis GAN (ILSGAN), pursuing independent foreground-background layer generation by encouraging their discrepancy. Specifically, it targets minimizing the mutual information between visible and invisible regions of the foreground and background to spur interlayer independence. Through in-depth theoretical and experimental analyses, we justify that explicit layer independence modeling is critical to suppressing information leakage and contributes to impressive segmentation performance gains. Also, our ILSGAN achieves strong state-of-the-art generation quality and segmentation performance on complex real-world data.
Local Manifold Augmentation for Multiview Semantic Consistency
Nov 05, 2022



Multiview self-supervised representation learning roots in exploring semantic consistency across data of complex intra-class variation. Such variation is not directly accessible and therefore simulated by data augmentations. However, commonly adopted augmentations are handcrafted and limited to simple geometrical and color changes, which are unable to cover the abundant intra-class variation. In this paper, we propose to extract the underlying data variation from datasets and construct a novel augmentation operator, named local manifold augmentation (LMA). LMA is achieved by training an instance-conditioned generator to fit the distribution on the local manifold of data and sampling multiview data using it. LMA shows the ability to create an infinite number of data views, preserve semantics, and simulate complicated variations in object pose, viewpoint, lighting condition, background etc. Experiments show that with LMA integrated, self-supervised learning methods such as MoCov2 and SimSiam gain consistent improvement on prevalent benchmarks including CIFAR10, CIFAR100, STL10, ImageNet100, and ImageNet. Furthermore, LMA leads to representations that obtain more significant invariance to the viewpoint, object pose, and illumination changes and stronger robustness to various real distribution shifts reflected by ImageNet-V2, ImageNet-R, ImageNet Sketch etc.
Unsupervised Foreground-Background Segmentation with Equivariant Layered GANs
Apr 01, 2021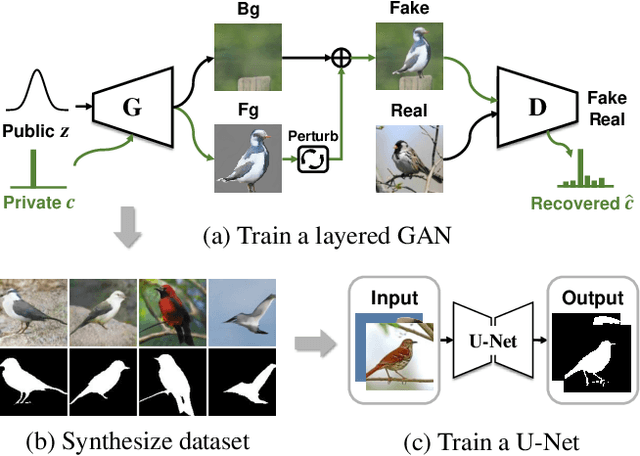
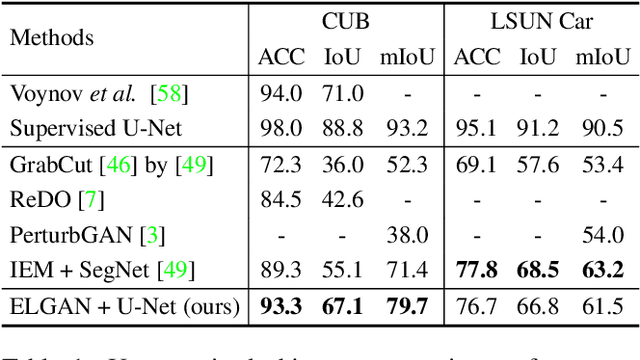
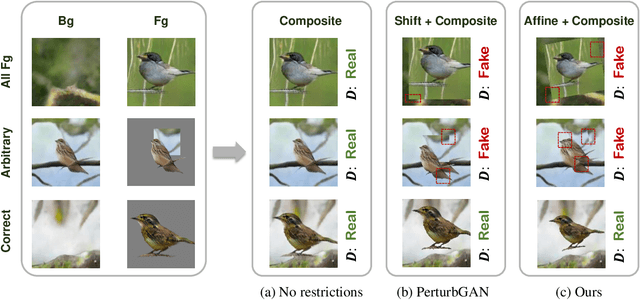
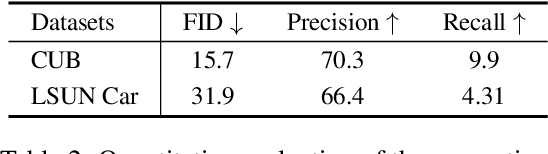
We propose an unsupervised foreground-background segmentation method via training a segmentation network on the synthetic pseudo segmentation dataset generated from GANs, which are trained from a collection of images without annotations to explicitly disentangle foreground and background. To efficiently generate foreground and background layers and overlay them to compose novel images, the construction of such GANs is fulfilled by our proposed Equivariant Layered GAN, whose improvement, compared to the precedented layered GAN, is embodied in the following two aspects. (1) The disentanglement of foreground and background is improved by extending the previous perturbation strategy and introducing private code recovery that reconstructs the private code of foreground from the composite image. (2) The latent space of the layered GANs is regularized by minimizing our proposed equivariance loss, resulting in interpretable latent codes and better disentanglement of foreground and background. Our methods are evaluated on unsupervised object segmentation datasets including Caltech-UCSD Birds and LSUN Car, achieving state-of-the-art performance.