 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBOSS: A Benchmark for Human Belief Prediction in Object-context Scenarios
Paper and Code
Jun 21, 2022

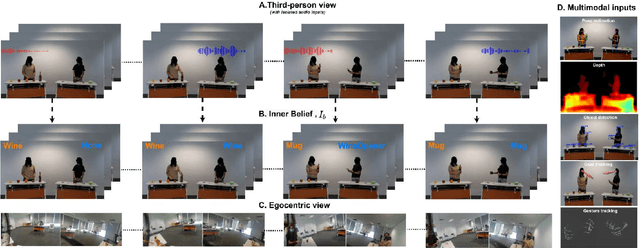

Humans with an average level of social cognition can infer the beliefs of others based solely on the nonverbal communication signals (e.g. gaze, gesture, pose and contextual information) exhibited during social interactions. This social cognitive ability to predict human beliefs and intentions is more important than ever for ensuring safe human-robot interaction and collaboration. This paper uses the combined knowledge of Theory of Mind (ToM) and Object-Context Relations to investigate methods for enhancing collaboration between humans and autonomous systems in environments where verbal communication is prohibited. We propose a novel and challenging multimodal video dataset for assessing the capability of artificial intelligence (AI) systems in predicting human belief states in an object-context scenario. The proposed dataset consists of precise labelling of human belief state ground-truth and multimodal inputs replicating all nonverbal communication inputs captured by human perception. We further evaluate our dataset with existing deep learning models and provide new insights into the effects of the various input modalities and object-context relations on the performance of the baseline models.