 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredictions of short-term driving intention using recurrent neural network on sequential data
Mar 28, 2018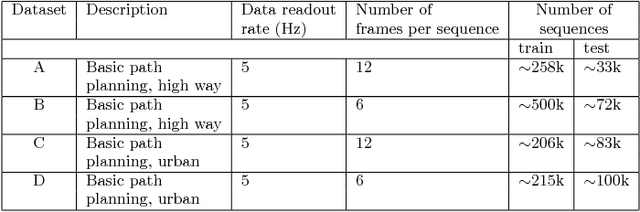



Predictions of driver's intentions and their behaviors using the road is of great importance for planning and decision making processes of autonomous driving vehicles. In particular, relatively short-term driving intentions are the fundamental units that constitute more sophisticated driving goals, behaviors, such as overtaking the slow vehicle in front, exit or merge onto a high way, etc. While it is not uncommon that most of the time human driver can rationalize, in advance, various on-road behaviors, intentions, as well as the associated risks, aggressiveness, reciprocity characteristics, etc., such reasoning skills can be challenging and difficult for an autonomous driving system to learn. In this article, we demonstrate a disciplined methodology that can be used to build and train a predictive drive system, therefore to learn the on-road characteristics aforementioned.
Modeling of the Latent Embedding of Music using Deep Neural Network
May 12, 2017
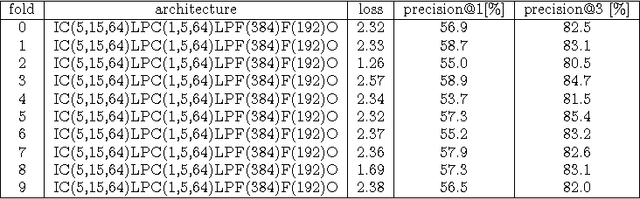


While both the data volume and heterogeneity of the digital music content is huge, it has become increasingly important and convenient to build a recommendation or search system to facilitate surfacing these content to the user or consumer community. Most of the recommendation models fall into two primary species, collaborative filtering based and content based approaches. Variants of instantiations of collaborative filtering approach suffer from the common issues of so called "cold start" and "long tail" problems where there is not much user interaction data to reveal user opinions or affinities on the content and also the distortion towards the popular content. Content-based approaches are sometimes limited by the richness of the available content data resulting in a heavily biased and coarse recommendation result. In recent years, the deep neural network has enjoyed a great success in large-scale image and video recognitions. In this paper, we propose and experiment using deep convolutional neural network to imitate how human brain processes hierarchical structures in the auditory signals, such as music, speech, etc., at various timescales. This approach can be used to discover the latent factor models of the music based upon acoustic hyper-images that are extracted from the raw audio waves of music. These latent embeddings can be used either as features to feed to subsequent models, such as collaborative filtering, or to build similarity metrics between songs, or to classify music based on the labels for training such as genre, mood, sentiment, etc.