 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLGAN: An Efficient High-Order Graph Neural Network via the Line Graph Aggregation
Dec 11, 2025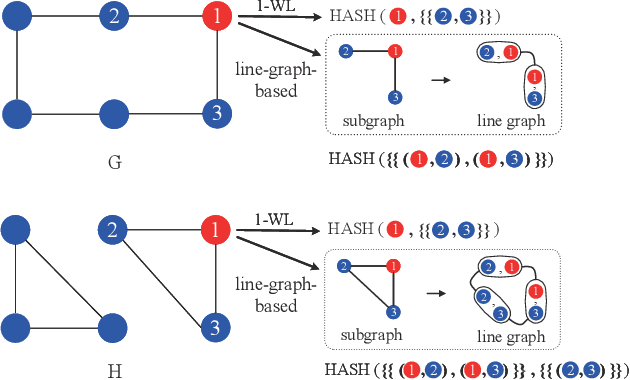
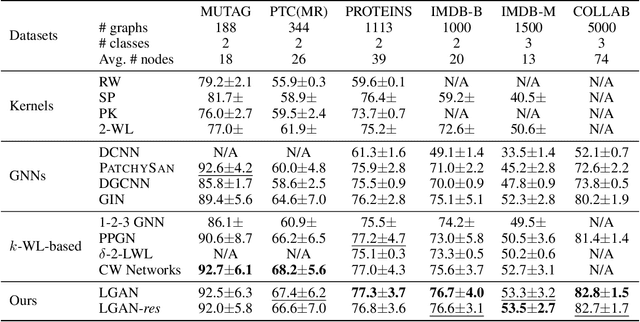
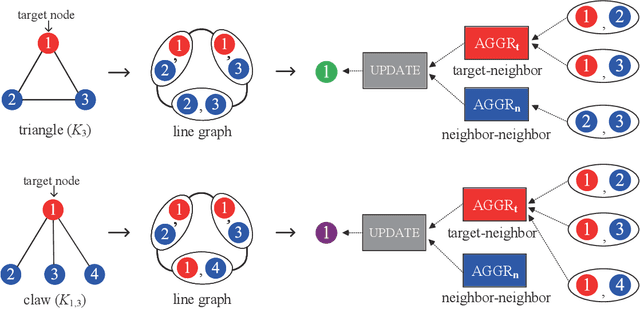
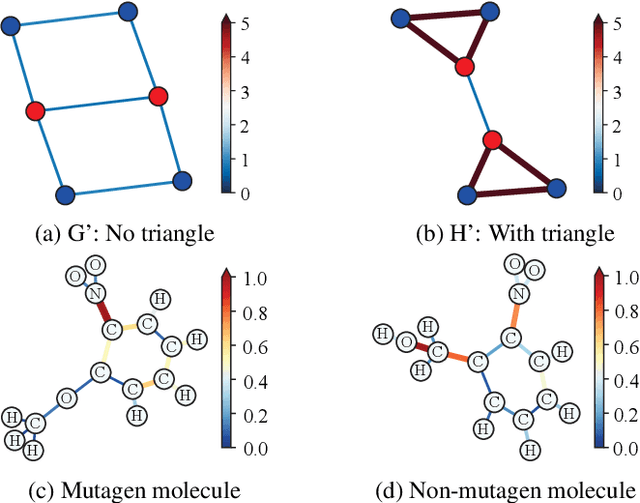
Graph Neural Networks (GNNs) have emerged as a dominant paradigm for graph classification. Specifically, most existing GNNs mainly rely on the message passing strategy between neighbor nodes, where the expressivity is limited by the 1-dimensional Weisfeiler-Lehman (1-WL) test. Although a number of k-WL-based GNNs have been proposed to overcome this limitation, their computational cost increases rapidly with k, significantly restricting the practical applicability. Moreover, since the k-WL models mainly operate on node tuples, these k-WL-based GNNs cannot retain fine-grained node- or edge-level semantics required by attribution methods (e.g., Integrated Gradients), leading to the less interpretable problem. To overcome the above shortcomings, in this paper, we propose a novel Line Graph Aggregation Network (LGAN), that constructs a line graph from the induced subgraph centered at each node to perform the higher-order aggregation. We theoretically prove that the LGAN not only possesses the greater expressive power than the 2-WL under injective aggregation assumptions, but also has lower time complexity. Empirical evaluations on benchmarks demonstrate that the LGAN outperforms state-of-the-art k-WL-based GNNs, while offering better interpretability.
Bi-directional Object-context Prioritization Learning for Saliency Ranking
Mar 22, 2022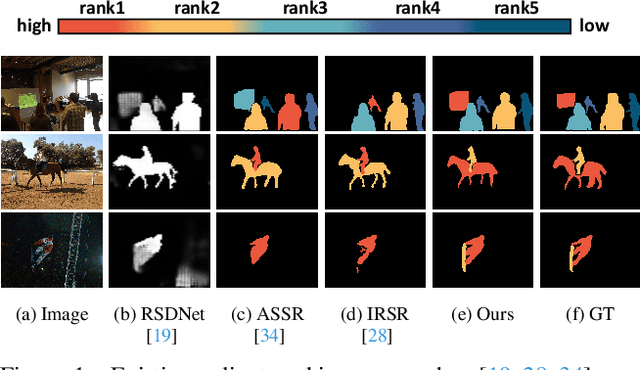
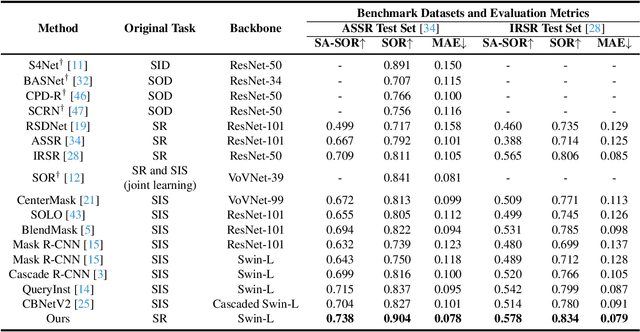


The saliency ranking task is recently proposed to study the visual behavior that humans would typically shift their attention over different objects of a scene based on their degrees of saliency. Existing approaches focus on learning either object-object or object-scene relations. Such a strategy follows the idea of object-based attention in Psychology, but it tends to favor those objects with strong semantics (e.g., humans), resulting in unrealistic saliency ranking. We observe that spatial attention works concurrently with object-based attention in the human visual recognition system. During the recognition process, the human spatial attention mechanism would move, engage, and disengage from region to region (i.e., context to context). This inspires us to model the region-level interactions, in addition to the object-level reasoning, for saliency ranking. To this end, we propose a novel bi-directional method to unify spatial attention and object-based attention for saliency ranking. Our model includes two novel modules: (1) a selective object saliency (SOS) module that models objectbased attention via inferring the semantic representation of the salient object, and (2) an object-context-object relation (OCOR) module that allocates saliency ranks to objects by jointly modeling the object-context and context-object interactions of the salient objects. Extensive experiments show that our approach outperforms existing state-of-theart methods. Our code and pretrained model are available at https://github.com/GrassBro/OCOR.
Amplitude-Phase Recombination: Rethinking Robustness of Convolutional Neural Networks in Frequency Domain
Aug 19, 2021



Recently, the generalization behavior of Convolutional Neural Networks (CNN) is gradually transparent through explanation techniques with the frequency components decomposition. However, the importance of the phase spectrum of the image for a robust vision system is still ignored. In this paper, we notice that the CNN tends to converge at the local optimum which is closely related to the high-frequency components of the training images, while the amplitude spectrum is easily disturbed such as noises or common corruptions. In contrast, more empirical studies found that humans rely on more phase components to achieve robust recognition. This observation leads to more explanations of the CNN's generalization behaviors in both robustness to common perturbations and out-of-distribution detection, and motivates a new perspective on data augmentation designed by re-combing the phase spectrum of the current image and the amplitude spectrum of the distracter image. That is, the generated samples force the CNN to pay more attention to the structured information from phase components and keep robust to the variation of the amplitude. Experiments on several image datasets indicate that the proposed method achieves state-of-the-art performances on multiple generalizations and calibration tasks, including adaptability for common corruptions and surface variations, out-of-distribution detection, and adversarial attack.
Handwritten Mathematical Expression Recognition with Bidirectionally Trained Transformer
May 16, 2021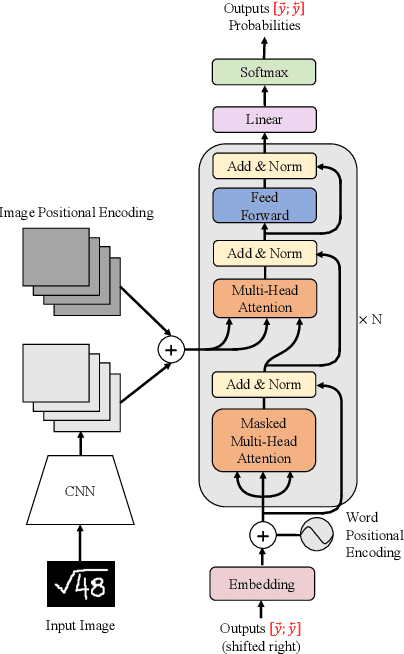



Encoder-decoder models have made great progress on handwritten mathematical expression recognition recently. However, it is still a challenge for existing methods to assign attention to image features accurately. Moreover, those encoder-decoder models usually adopt RNN-based models in their decoder part, which makes them inefficient in processing long $\LaTeX{}$ sequences. In this paper, a transformer-based decoder is employed to replace RNN-based ones, which makes the whole model architecture very concise. Furthermore, a novel training strategy is introduced to fully exploit the potential of the transformer in bidirectional language modeling. Compared to several methods that do not use data augmentation, experiments demonstrate that our model improves the ExpRate of current state-of-the-art methods on CROHME 2014 by 2.23%. Similarly, on CROHME 2016 and CROHME 2019, we improve the ExpRate by 1.92% and 2.28% respectively.