 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHandwritten Mathematical Expression Recognition with Bidirectionally Trained Transformer
Paper and Code
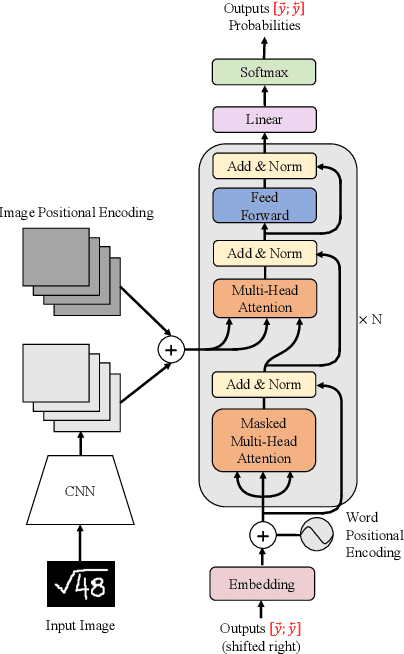



Encoder-decoder models have made great progress on handwritten mathematical expression recognition recently. However, it is still a challenge for existing methods to assign attention to image features accurately. Moreover, those encoder-decoder models usually adopt RNN-based models in their decoder part, which makes them inefficient in processing long $\LaTeX{}$ sequences. In this paper, a transformer-based decoder is employed to replace RNN-based ones, which makes the whole model architecture very concise. Furthermore, a novel training strategy is introduced to fully exploit the potential of the transformer in bidirectional language modeling. Compared to several methods that do not use data augmentation, experiments demonstrate that our model improves the ExpRate of current state-of-the-art methods on CROHME 2014 by 2.23%. Similarly, on CROHME 2016 and CROHME 2019, we improve the ExpRate by 1.92% and 2.28% respectively.