 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoMER: Modeling Coverage for Transformer-based Handwritten Mathematical Expression Recognition
Paper and Code

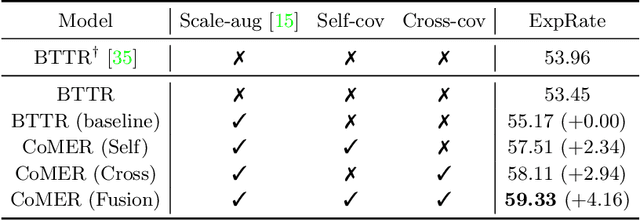
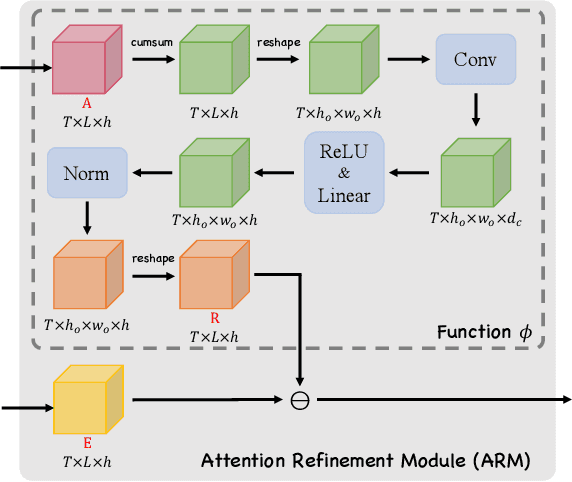
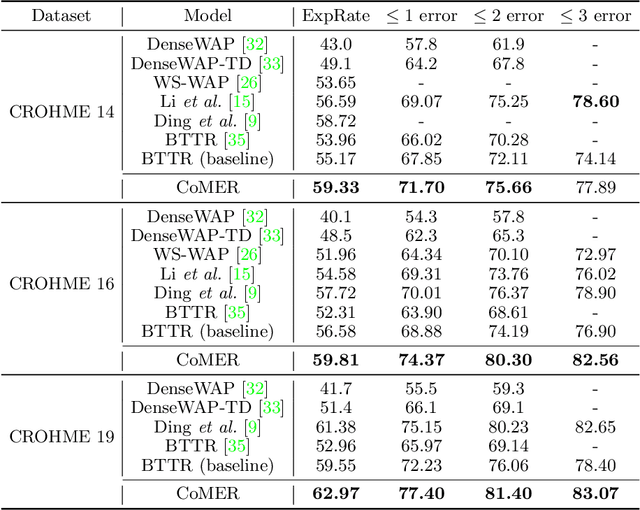
The Transformer-based encoder-decoder architecture has recently made significant advances in recognizing handwritten mathematical expressions. However, the transformer model still suffers from the lack of coverage problem, making its expression recognition rate (ExpRate) inferior to its RNN counterpart. Coverage information, which records the alignment information of the past steps, has proven effective in the RNN models. In this paper, we propose CoMER, a model that adopts the coverage information in the transformer decoder. Specifically, we propose a novel Attention Refinement Module (ARM) to refine the attention weights with past alignment information without hurting its parallelism. Furthermore, we take coverage information to the extreme by proposing self-coverage and cross-coverage, which utilize the past alignment information from the current and previous layers. Experiments show that CoMER improves the ExpRate by 0.61%/2.09%/1.59% compared to the current state-of-the-art model, and reaches 59.33%/59.81%/62.97% on the CROHME 2014/2016/2019 test sets.