 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHidden Darkness in LLM-Generated Designs: Exploring Dark Patterns in Ecommerce Web Components Generated by LLMs
Feb 19, 2025
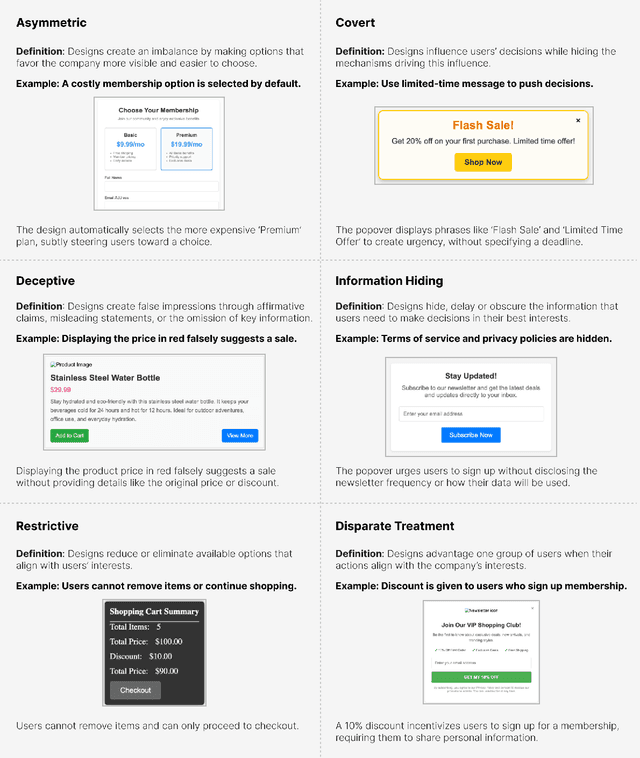

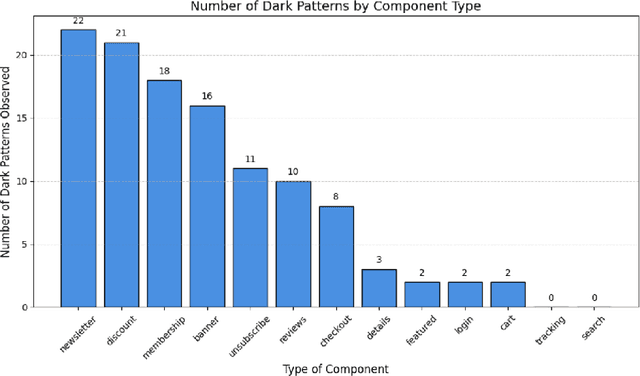
Recent work has highlighted the risks of LLM-generated content for a wide range of harmful behaviors, including incorrect and harmful code. In this work, we extend this by studying whether LLM-generated web design contains dark patterns. This work evaluated designs of ecommerce web components generated by four popular LLMs: Claude, GPT, Gemini, and Llama. We tested 13 commonly used ecommerce components (e.g., search, product reviews) and used them as prompts to generate a total of 312 components across all models. Over one-third of generated components contain at least one dark pattern. The majority of dark pattern strategies involve hiding crucial information, limiting users' actions, and manipulating them into making decisions through a sense of urgency. Dark patterns are also more frequently produced in components that are related to company interests. These findings highlight the need for interventions to prevent dark patterns during front-end code generation with LLMs and emphasize the importance of expanding ethical design education to a broader audience.
Customizing Contextualized Language Models forLegal Document Reviews
Feb 10, 2021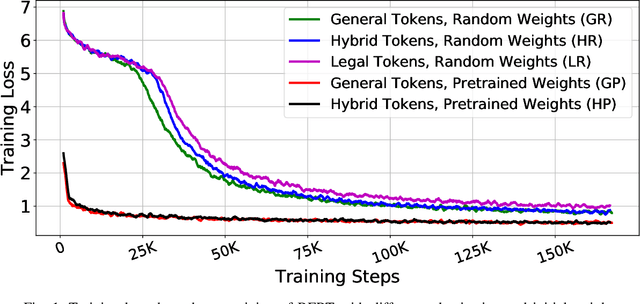


Inspired by the inductive transfer learning on computer vision, many efforts have been made to train contextualized language models that boost the performance of natural language processing tasks. These models are mostly trained on large general-domain corpora such as news, books, or Wikipedia.Although these pre-trained generic language models well perceive the semantic and syntactic essence of a language structure, exploiting them in a real-world domain-specific scenario still needs some practical considerations to be taken into account such as token distribution shifts, inference time, memory, and their simultaneous proficiency in multiple tasks. In this paper, we focus on the legal domain and present how different language model strained on general-domain corpora can be best customized for multiple legal document reviewing tasks. We compare their efficiencies with respect to task performances and present practical considerations.