 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting the Success of Domain Adaptation in Text Similarity
Jun 23, 2021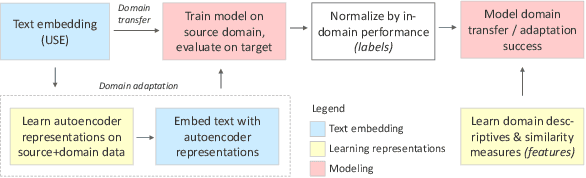
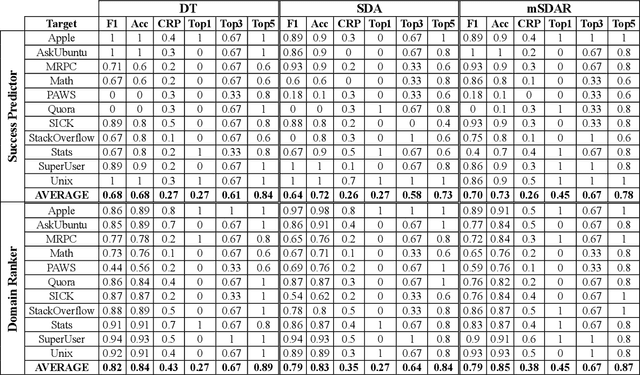

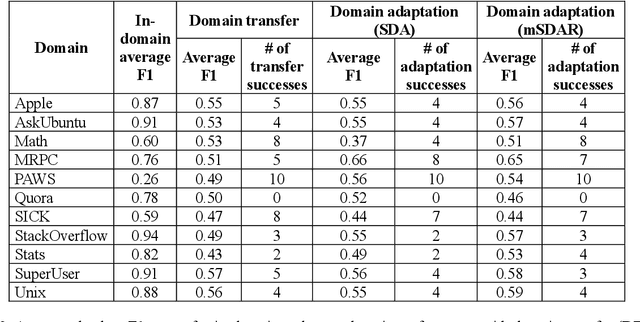
Transfer learning methods, and in particular domain adaptation, help exploit labeled data in one domain to improve the performance of a certain task in another domain. However, it is still not clear what factors affect the success of domain adaptation. This paper models adaptation success and selection of the most suitable source domains among several candidates in text similarity. We use descriptive domain information and cross-domain similarity metrics as predictive features. While mostly positive, the results also point to some domains where adaptation success was difficult to predict.
Customizing Contextualized Language Models forLegal Document Reviews
Feb 10, 2021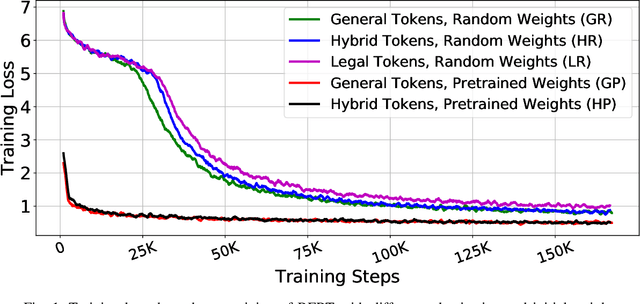


Inspired by the inductive transfer learning on computer vision, many efforts have been made to train contextualized language models that boost the performance of natural language processing tasks. These models are mostly trained on large general-domain corpora such as news, books, or Wikipedia.Although these pre-trained generic language models well perceive the semantic and syntactic essence of a language structure, exploiting them in a real-world domain-specific scenario still needs some practical considerations to be taken into account such as token distribution shifts, inference time, memory, and their simultaneous proficiency in multiple tasks. In this paper, we focus on the legal domain and present how different language model strained on general-domain corpora can be best customized for multiple legal document reviewing tasks. We compare their efficiencies with respect to task performances and present practical considerations.
Unsupervised domain-agnostic identification of product names in social media posts
Dec 11, 2018



Product name recognition is a significant practical problem, spurred by the greater availability of platforms for discussing products such as social media and product review functionalities of online marketplaces. Customers, product manufacturers and online marketplaces may want to identify product names in unstructured text to extract important insights, such as sentiment, surrounding a product. Much extant research on product name identification has been domain-specific (e.g., identifying mobile phone models) and used supervised or semi-supervised methods. With massive numbers of new products released to the market every year such methods may require retraining on updated labeled data to stay relevant, and may transfer poorly across domains. This research addresses this challenge and develops a domain-agnostic, unsupervised algorithm for identifying product names based on Facebook posts. The algorithm consists of two general steps: (a) candidate product name identification using an off-the-shelf pretrained conditional random fields (CRF) model, part-of-speech tagging and a set of simple patterns; and (b) filtering of candidate names to remove spurious entries using clustering and word embeddings generated from the data.
Identifying emergency stages in Facebook posts of police departments with convolutional and recurrent neural networks and support vector machines
Jan 24, 2018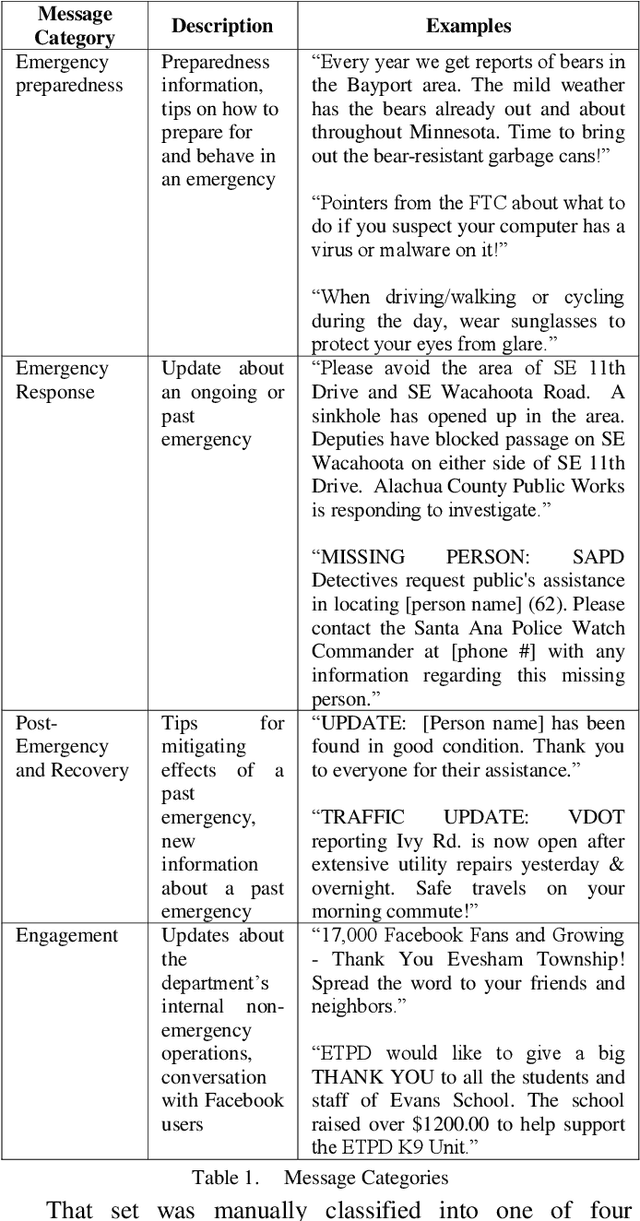
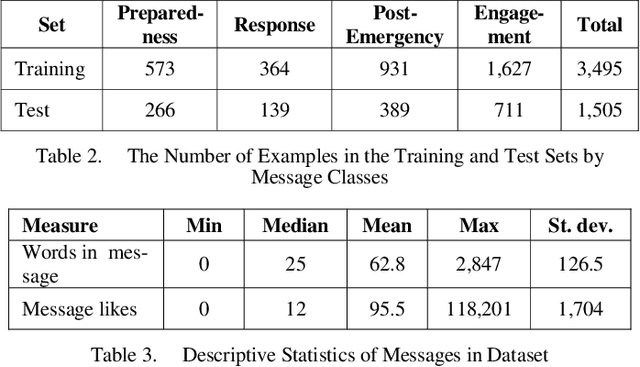
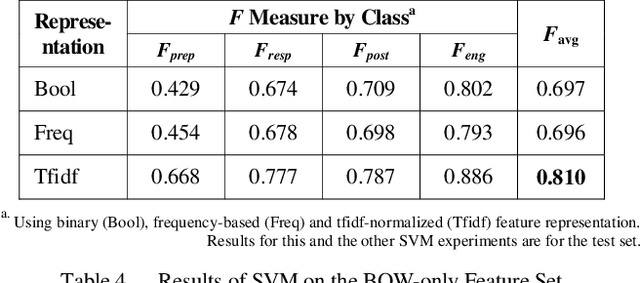
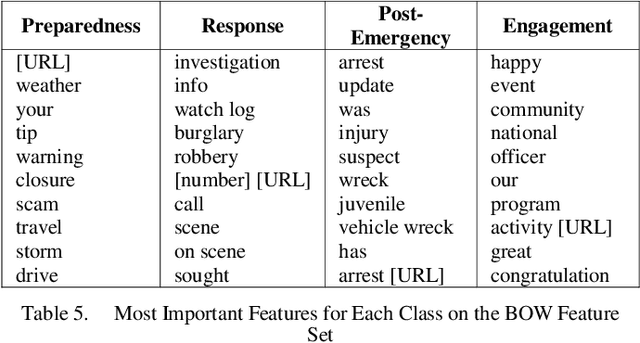
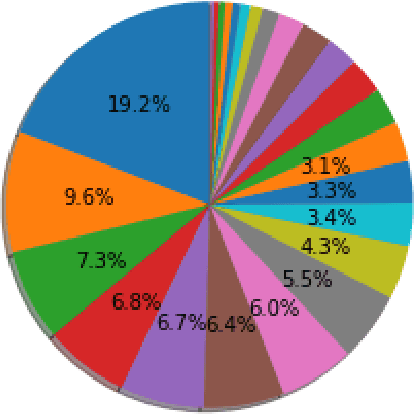
Classification of social media posts in emergency response is an important practical problem: accurate classification can help automate processing of such messages and help other responders and the public react to emergencies in a timely fashion. This research focused on classifying Facebook messages of US police departments. Randomly selected 5,000 messages were used to train classifiers that distinguished between four categories of messages: emergency preparedness, response and recovery, as well as general engagement messages. Features were represented with bag-of-words and word2vec, and models were constructed using support vector machines (SVMs) and convolutional (CNNs) and recurrent neural networks (RNNs). The best performing classifier was an RNN with a custom-trained word2vec model to represent features, which achieved the F1 measure of 0.839.