 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExcision Score: Evaluating Edits with Surgical Precision
Oct 24, 2025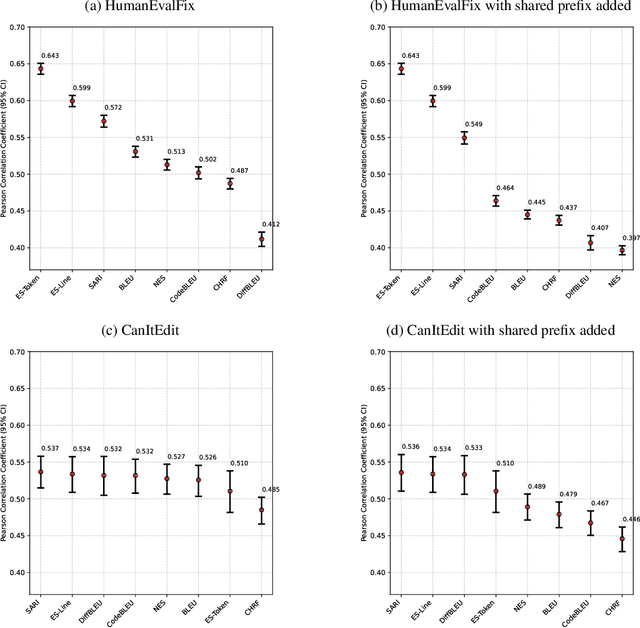
Many tasks revolve around editing a document, whether code or text. We formulate the revision similarity problem to unify a wide range of machine learning evaluation problems whose goal is to assess a revision to an existing document. We observe that revisions usually change only a small portion of an existing document, so the existing document and its immediate revisions share a majority of their content. We formulate five adequacy criteria for revision similarity measures, designed to align them with human judgement. We show that popular pairwise measures, like BLEU, fail to meet these criteria, because their scores are dominated by the shared content. They report high similarity between two revisions when humans would assess them as quite different. This is a fundamental flaw we address. We propose a novel static measure, Excision Score (ES), which computes longest common subsequence (LCS) to remove content shared by an existing document with the ground truth and predicted revisions, before comparing only the remaining divergent regions. This is analogous to a surgeon creating a sterile field to focus on the work area. We use approximation to speed the standard cubic LCS computation to quadratic. In code-editing evaluation, where static measures are often used as a cheap proxy for passing tests, we demonstrate that ES surpasses existing measures. When aligned with test execution on HumanEvalFix, ES improves over its nearest competitor, SARI, by 12% Pearson correlation and by >21% over standard measures like BLEU. The key criterion is invariance to shared context; when we perturb HumanEvalFix with increased shared context, ES' improvement over SARI increases to 20% and >30% over standard measures. ES also handles other corner cases that other measures do not, such as correctly aligning moved code blocks, and appropriately rewarding matching insertions or deletions.
Bayesian-LoRA: LoRA based Parameter Efficient Fine-Tuning using Optimal Quantization levels and Rank Values trough Differentiable Bayesian Gates
Jun 18, 2024



It is a common practice in natural language processing to pre-train a single model on a general domain and then fine-tune it for downstream tasks. However, when it comes to Large Language Models, fine-tuning the entire model can be computationally expensive, resulting in very intensive energy consumption. As a result, several Parameter efficient fine-tuning (PEFT) approaches were recently proposed. One of the most popular approaches is low-rank adaptation (LoRA), where the key insight is decomposing the update weights of the pre-trained model into two low-rank matrices. However, the proposed approaches either use the same rank value across all different weight matrices or do not use any quantization technique, which has been shown to be one of the most important factors when it comes to a model's energy consumption. In this work, we propose Bayesian-LoRA (B-LoRA) which approaches matrix decomposition and quantization from a Bayesian perspective by employing a prior distribution on both quantization levels and rank values of the learned low-rank matrices. As a result, B-LoRA is able to fine-tune a pre-trained model on a specific downstream task, finding the optimal rank values and quantization levels for every low-rank matrix. We validate the proposed model fine-tuning a pre-trained DeBERTaV3 on the GLUE benchmark. Moreover, we compare it to relevant baselines and present both qualitative and quantitative results, showing how the proposed approach is able to learn optimal-rank quantized matrices. B-LoRA performs on par or better than baselines while reducing the total amount of bit operations of roughly 70% with respect to the baselines ones.