 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDataset Clustering for Improved Offline Policy Learning
Feb 14, 2024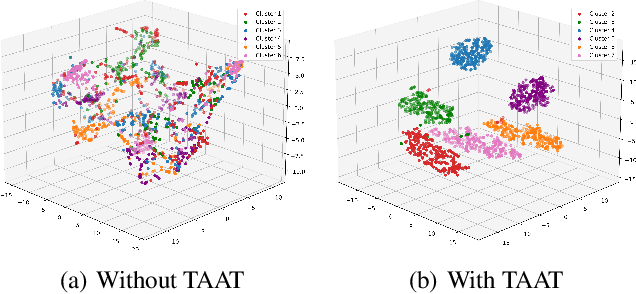
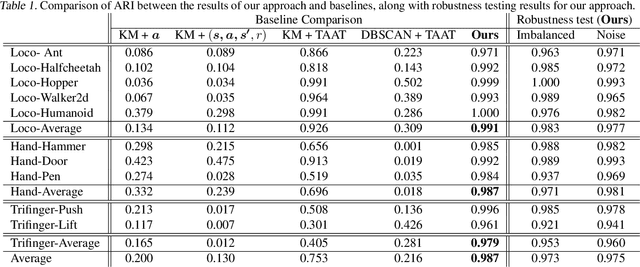
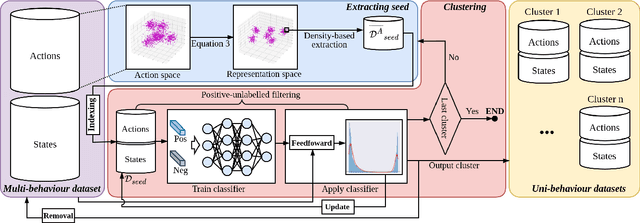

Offline policy learning aims to discover decision-making policies from previously-collected datasets without additional online interactions with the environment. As the training dataset is fixed, its quality becomes a crucial determining factor in the performance of the learned policy. This paper studies a dataset characteristic that we refer to as multi-behavior, indicating that the dataset is collected using multiple policies that exhibit distinct behaviors. In contrast, a uni-behavior dataset would be collected solely using one policy. We observed that policies learned from a uni-behavior dataset typically outperform those learned from multi-behavior datasets, despite the uni-behavior dataset having fewer examples and less diversity. Therefore, we propose a behavior-aware deep clustering approach that partitions multi-behavior datasets into several uni-behavior subsets, thereby benefiting downstream policy learning. Our approach is flexible and effective; it can adaptively estimate the number of clusters while demonstrating high clustering accuracy, achieving an average Adjusted Rand Index of 0.987 across various continuous control task datasets. Finally, we present improved policy learning examples using dataset clustering and discuss several potential scenarios where our approach might benefit the offline policy learning community.
Learning and reusing primitive behaviours to improve Hindsight Experience Replay sample efficiency
Oct 03, 2023
Hindsight Experience Replay (HER) is a technique used in reinforcement learning (RL) that has proven to be very efficient for training off-policy RL-based agents to solve goal-based robotic manipulation tasks using sparse rewards. Even though HER improves the sample efficiency of RL-based agents by learning from mistakes made in past experiences, it does not provide any guidance while exploring the environment. This leads to very large training times due to the volume of experience required to train an agent using this replay strategy. In this paper, we propose a method that uses primitive behaviours that have been previously learned to solve simple tasks in order to guide the agent toward more rewarding actions during exploration while learning other more complex tasks. This guidance, however, is not executed by a manually designed curriculum, but rather using a critic network to decide at each timestep whether or not to use the actions proposed by the previously-learned primitive policies. We evaluate our method by comparing its performance against HER and other more efficient variations of this algorithm in several block manipulation tasks. We demonstrate the agents can learn a successful policy faster when using our proposed method, both in terms of sample efficiency and computation time. Code is available at https://github.com/franroldans/qmp-her.
Behaviour Discriminator: A Simple Data Filtering Method to Improve Offline Policy Learning
Jan 27, 2023This paper studies the problem of learning a control policy without the need for interactions with the environment; instead, learning purely from an existing dataset. Prior work has demonstrated that offline learning algorithms (e.g., behavioural cloning and offline reinforcement learning) are more likely to discover a satisfactory policy when trained using high-quality expert data. However, many real-world/practical datasets can contain significant proportions of examples generated using low-skilled agents. Therefore, we propose a behaviour discriminator (BD) concept, a novel and simple data filtering approach based on semi-supervised learning, which can accurately discern expert data from a mixed-quality dataset. Our BD approach was used to pre-process the mixed-skill-level datasets from the Real Robot Challenge (RRC) III, an open competition requiring participants to solve several dexterous robotic manipulation tasks using offline learning methods; the new BD method allowed a standard behavioural cloning algorithm to outperform other more sophisticated offline learning algorithms. Moreover, we demonstrate that the new BD pre-processing method can be applied to a number of D4RL benchmark problems, improving the performance of multiple state-of-the-art offline reinforcement learning algorithms.
Hierarchical reinforcement learning for in-hand robotic manipulation using Davenport chained rotations
Oct 03, 2022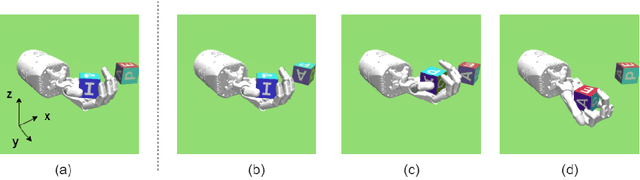
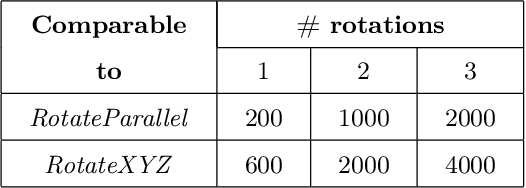
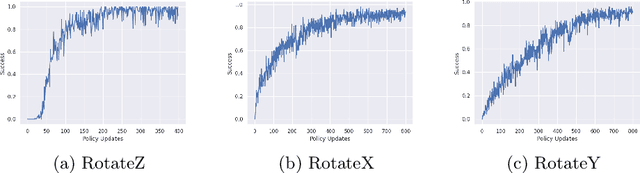

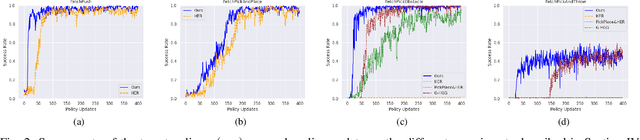
End-to-end reinforcement learning techniques are among the most successful methods for robotic manipulation tasks. However, the training time required to find a good policy capable of solving complex tasks is prohibitively large. Therefore, depending on the computing resources available, it might not be feasible to use such techniques. The use of domain knowledge to decompose manipulation tasks into primitive skills, to be performed in sequence, could reduce the overall complexity of the learning problem, and hence reduce the amount of training required to achieve dexterity. In this paper, we propose the use of Davenport chained rotations to decompose complex 3D rotation goals into a concatenation of a smaller set of more simple rotation skills. State-of-the-art reinforcement-learning-based methods can then be trained using less overall simulated experience. We compare its performance with the popular Hindsight Experience Replay method, trained in an end-to-end fashion using the same amount of experience in a simulated robotic hand environment. Despite a general decrease in performance of the primitive skills when being sequentially executed, we find that decomposing arbitrary 3D rotations into elementary rotations is beneficial when computing resources are limited, obtaining increases of success rates of approximately 10% on the most complex 3D rotations with respect to the success rates obtained by HER trained in an end-to-end fashion, and increases of success rates between 20% and 40% on the most simple rotations.
Towards advanced robotic manipulation
Sep 26, 2022
Robotic manipulation and control has increased in importance in recent years. However, state of the art techniques still have limitations when required to operate in real world applications. This paper explores Hindsight Experience Replay both in simulated and real environments, highlighting its weaknesses and proposing reinforcement-learning based alternatives based on reward and goal shaping. Additionally, several research questions are identified along with potential research directions that could be explored to tackle those questions.
Dexterous Robotic Manipulation using Deep Reinforcement Learning and Knowledge Transfer for Complex Sparse Reward-based Tasks
May 19, 2022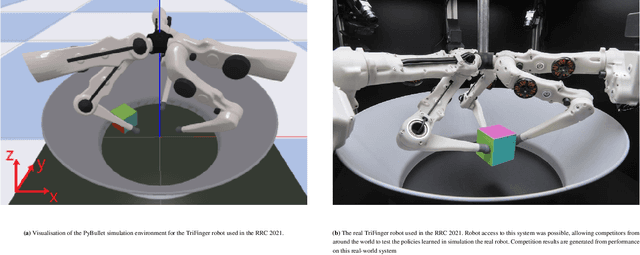

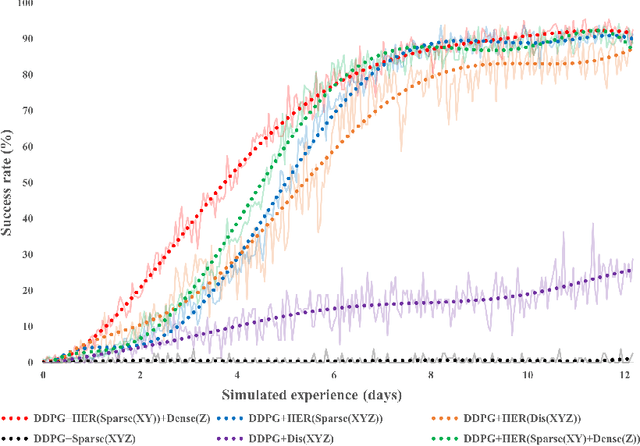

This paper describes a deep reinforcement learning (DRL) approach that won Phase 1 of the Real Robot Challenge (RRC) 2021, and then extends this method to a more difficult manipulation task. The RRC consisted of using a TriFinger robot to manipulate a cube along a specified positional trajectory, but with no requirement for the cube to have any specific orientation. We used a relatively simple reward function, a combination of goal-based sparse reward and distance reward, in conjunction with Hindsight Experience Replay (HER) to guide the learning of the DRL agent (Deep Deterministic Policy Gradient (DDPG)). Our approach allowed our agents to acquire dexterous robotic manipulation strategies in simulation. These strategies were then applied to the real robot and outperformed all other competition submissions, including those using more traditional robotic control techniques, in the final evaluation stage of the RRC. Here we extend this method, by modifying the task of Phase 1 of the RRC to require the robot to maintain the cube in a particular orientation, while the cube is moved along the required positional trajectory. The requirement to also orient the cube makes the agent unable to learn the task through blind exploration due to increased problem complexity. To circumvent this issue, we make novel use of a Knowledge Transfer (KT) technique that allows the strategies learned by the agent in the original task (which was agnostic to cube orientation) to be transferred to this task (where orientation matters). KT allowed the agent to learn and perform the extended task in the simulator, which improved the average positional deviation from 0.134 m to 0.02 m, and average orientation deviation from 142{\deg} to 76{\deg} during evaluation. This KT concept shows good generalisation properties and could be applied to any actor-critic learning algorithm.
Real Robot Challenge using Deep Reinforcement Learning
Sep 30, 2021


This paper details our winning submission to Phase 1 of the 2021 Real Robot Challenge, a challenge in which a three fingered robot must carry a cube along specified goal trajectories. To solve Phase 1, we use a pure reinforcement learning approach which requires minimal expert knowledge of the robotic system or of robotic grasping in general. A sparse goal-based reward is employed in conjunction with Hindsight Experience Replay to teach the control policy to move the cube to the desired x and y coordinates. Simultaneously, a dense distance-based reward is employed to teach the policy to lift the cube to the desired z coordinate. The policy is trained in simulation with domain randomization before being transferred to the real robot for evaluation. Although performance tends to worsen after this transfer, our best trained policy can successfully lift the real cube along goal trajectories via the use of an effective pinching grasp. Our approach outperforms all other submissions, including those leveraging more traditional robotic control techniques, and is the first learning-based approach to solve this challenge.