 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Neuromorphic Incipient Slip Detection System using Papillae Morphology
Sep 11, 2025Detecting incipient slip enables early intervention to prevent object slippage and enhance robotic manipulation safety. However, deploying such systems on edge platforms remains challenging, particularly due to energy constraints. This work presents a neuromorphic tactile sensing system based on the NeuroTac sensor with an extruding papillae-based skin and a spiking convolutional neural network (SCNN) for slip-state classification. The SCNN model achieves 94.33% classification accuracy across three classes (no slip, incipient slip, and gross slip) in slip conditions induced by sensor motion. Under the dynamic gravity-induced slip validation conditions, after temporal smoothing of the SCNN's final-layer spike counts, the system detects incipient slip at least 360 ms prior to gross slip across all trials, consistently identifying incipient slip before gross slip occurs. These results demonstrate that this neuromorphic system has stable and responsive incipient slip detection capability.
Dataset Clustering for Improved Offline Policy Learning
Feb 14, 2024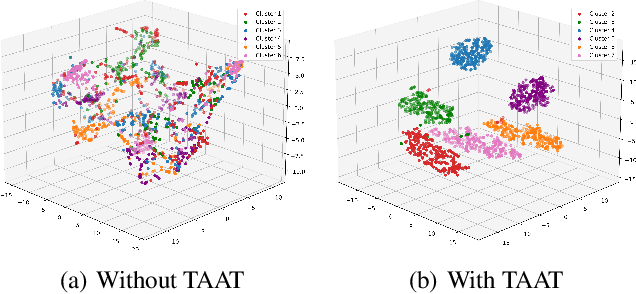
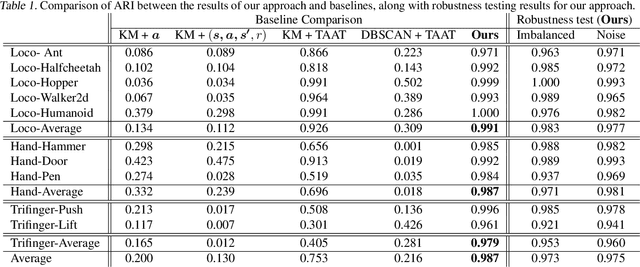
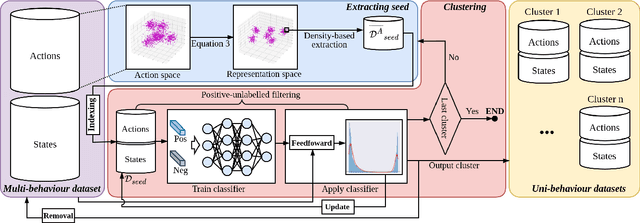

Offline policy learning aims to discover decision-making policies from previously-collected datasets without additional online interactions with the environment. As the training dataset is fixed, its quality becomes a crucial determining factor in the performance of the learned policy. This paper studies a dataset characteristic that we refer to as multi-behavior, indicating that the dataset is collected using multiple policies that exhibit distinct behaviors. In contrast, a uni-behavior dataset would be collected solely using one policy. We observed that policies learned from a uni-behavior dataset typically outperform those learned from multi-behavior datasets, despite the uni-behavior dataset having fewer examples and less diversity. Therefore, we propose a behavior-aware deep clustering approach that partitions multi-behavior datasets into several uni-behavior subsets, thereby benefiting downstream policy learning. Our approach is flexible and effective; it can adaptively estimate the number of clusters while demonstrating high clustering accuracy, achieving an average Adjusted Rand Index of 0.987 across various continuous control task datasets. Finally, we present improved policy learning examples using dataset clustering and discuss several potential scenarios where our approach might benefit the offline policy learning community.
Robust Learning-Based Incipient Slip Detection using the PapillArray Optical Tactile Sensor for Improved Robotic Gripping
Jul 08, 2023The ability to detect slip, particularly incipient slip, enables robotic systems to take corrective measures to prevent a grasped object from being dropped. Therefore, slip detection can enhance the overall security of robotic gripping. However, accurately detecting incipient slip remains a significant challenge. In this paper, we propose a novel learning-based approach to detect incipient slip using the PapillArray (Contactile, Australia) tactile sensor. The resulting model is highly effective in identifying patterns associated with incipient slip, achieving a detection success rate of 95.6% when tested with an offline dataset. Furthermore, we introduce several data augmentation methods to enhance the robustness of our model. When transferring the trained model to a robotic gripping environment distinct from where the training data was collected, our model maintained robust performance, with a success rate of 96.8%, providing timely feedback for stabilizing several practical gripping tasks. Our project website: https://sites.google.com/view/incipient-slip-detection.
Winning Solution of Real Robot Challenge III
Jan 30, 2023



This report introduces our winning solution of the real-robot phase of the Real Robot Challenge (RRC) 2022. The goal of this year's challenge is to solve dexterous manipulation tasks with offline reinforcement learning (RL) or imitation learning. To this end, participants are provided with datasets containing dozens of hours of robotic data. For each task an expert and a mixed dataset are provided. In our experiments, when learning from the expert datasets, we find standard Behavioral Cloning (BC) outperforms state-of-the-art offline RL algorithms. When learning from the mixed datasets, BC performs poorly, as expected, while surprisingly offline RL performs suboptimally, failing to match the average performance of the baseline model used for collecting the datasets. To remedy this, motivated by the strong performance of BC on the expert datasets we elect to use a semi-supervised classification technique to filter the subset of expert data out from the mixed datasets, and subsequently perform BC on this extracted subset of data. To further improve results, in all settings we use a simple data augmentation method that exploits the geometric symmetry of the RRC physical robotic environment. Our submitted BC policies each surpass the mean return of their respective raw datasets, and the policies trained on the filtered mixed datasets come close to matching the performances of those trained on the expert datasets.
Behaviour Discriminator: A Simple Data Filtering Method to Improve Offline Policy Learning
Jan 27, 2023This paper studies the problem of learning a control policy without the need for interactions with the environment; instead, learning purely from an existing dataset. Prior work has demonstrated that offline learning algorithms (e.g., behavioural cloning and offline reinforcement learning) are more likely to discover a satisfactory policy when trained using high-quality expert data. However, many real-world/practical datasets can contain significant proportions of examples generated using low-skilled agents. Therefore, we propose a behaviour discriminator (BD) concept, a novel and simple data filtering approach based on semi-supervised learning, which can accurately discern expert data from a mixed-quality dataset. Our BD approach was used to pre-process the mixed-skill-level datasets from the Real Robot Challenge (RRC) III, an open competition requiring participants to solve several dexterous robotic manipulation tasks using offline learning methods; the new BD method allowed a standard behavioural cloning algorithm to outperform other more sophisticated offline learning algorithms. Moreover, we demonstrate that the new BD pre-processing method can be applied to a number of D4RL benchmark problems, improving the performance of multiple state-of-the-art offline reinforcement learning algorithms.
Adaptive Target-Condition Neural Network: DNN-Aided Load Balancing for Hybrid LiFi and WiFi Networks
Aug 09, 2022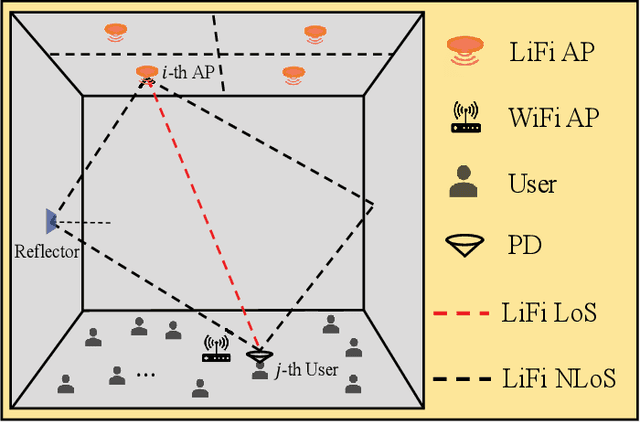
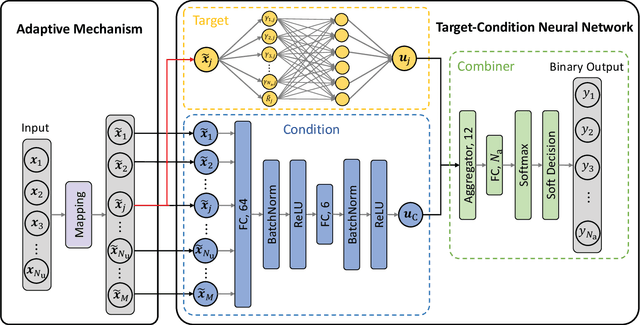
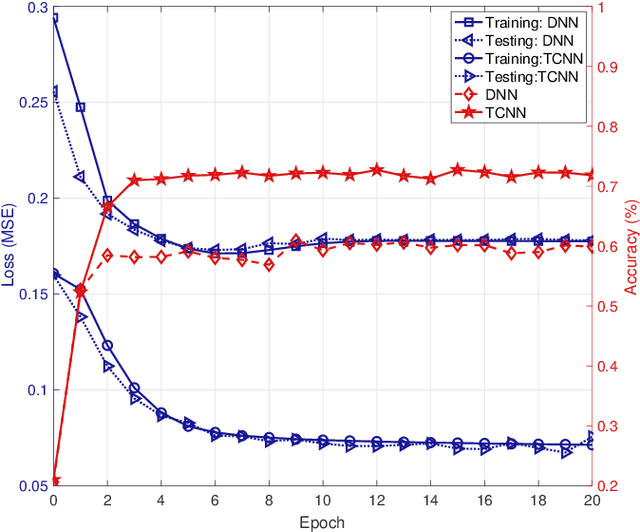
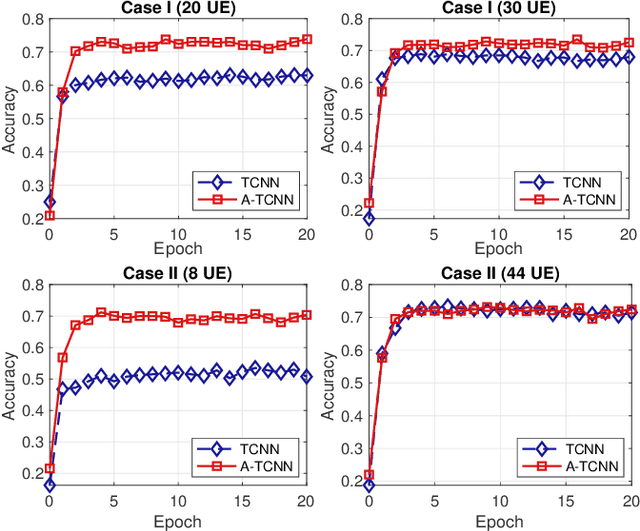
Load balancing (LB) is a challenging issue in the hybrid light fidelity (LiFi) and wireless fidelity (WiFi) networks (HLWNets), due to the nature of heterogeneous access points (APs). Machine learning has the potential to provide a complexity-friendly LB solution with near-optimal network performance, at the cost of a training process. The state-of-the-art (SOTA) learning-aided LB methods, however, need retraining when the network environment (especially the number of users) changes, significantly limiting its practicability. In this paper, a novel deep neural network (DNN) structure named adaptive target-condition neural network (A-TCNN) is proposed, which conducts AP selection for one target user upon the condition of other users. Also, an adaptive mechanism is developed to map a smaller number of users to a larger number through splitting their data rate requirements, without affecting the AP selection result for the target user. This enables the proposed method to handle different numbers of users without the need for retraining. Results show that A-TCNN achieves a network throughput very close to that of the testing dataset, with a gap less than 3%. It is also proven that A-TCNN can obtain a network throughput comparable to two SOTA benchmarks, while reducing the runtime by up to three orders of magnitude.
Dexterous Robotic Manipulation using Deep Reinforcement Learning and Knowledge Transfer for Complex Sparse Reward-based Tasks
May 19, 2022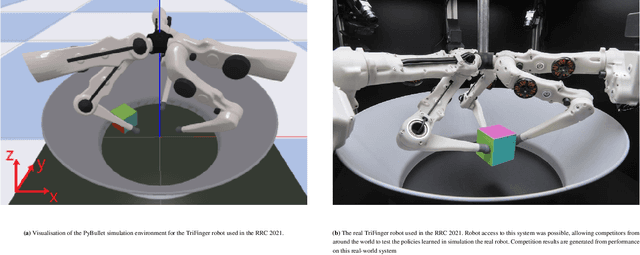


This paper describes a deep reinforcement learning (DRL) approach that won Phase 1 of the Real Robot Challenge (RRC) 2021, and then extends this method to a more difficult manipulation task. The RRC consisted of using a TriFinger robot to manipulate a cube along a specified positional trajectory, but with no requirement for the cube to have any specific orientation. We used a relatively simple reward function, a combination of goal-based sparse reward and distance reward, in conjunction with Hindsight Experience Replay (HER) to guide the learning of the DRL agent (Deep Deterministic Policy Gradient (DDPG)). Our approach allowed our agents to acquire dexterous robotic manipulation strategies in simulation. These strategies were then applied to the real robot and outperformed all other competition submissions, including those using more traditional robotic control techniques, in the final evaluation stage of the RRC. Here we extend this method, by modifying the task of Phase 1 of the RRC to require the robot to maintain the cube in a particular orientation, while the cube is moved along the required positional trajectory. The requirement to also orient the cube makes the agent unable to learn the task through blind exploration due to increased problem complexity. To circumvent this issue, we make novel use of a Knowledge Transfer (KT) technique that allows the strategies learned by the agent in the original task (which was agnostic to cube orientation) to be transferred to this task (where orientation matters). KT allowed the agent to learn and perform the extended task in the simulator, which improved the average positional deviation from 0.134 m to 0.02 m, and average orientation deviation from 142{\deg} to 76{\deg} during evaluation. This KT concept shows good generalisation properties and could be applied to any actor-critic learning algorithm.
Imaginary Hindsight Experience Replay: Curious Model-based Learning for Sparse Reward Tasks
Oct 05, 2021
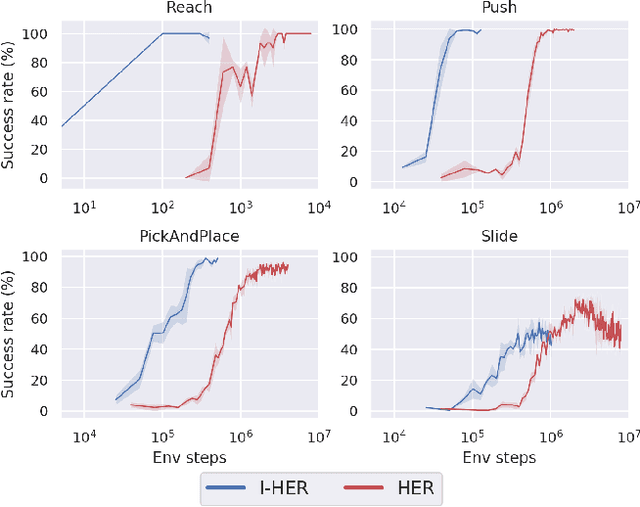
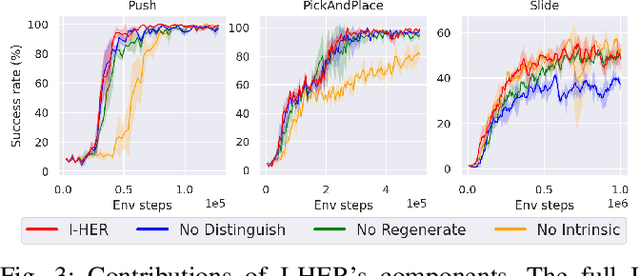
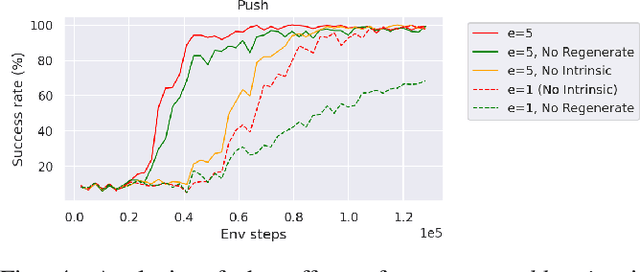
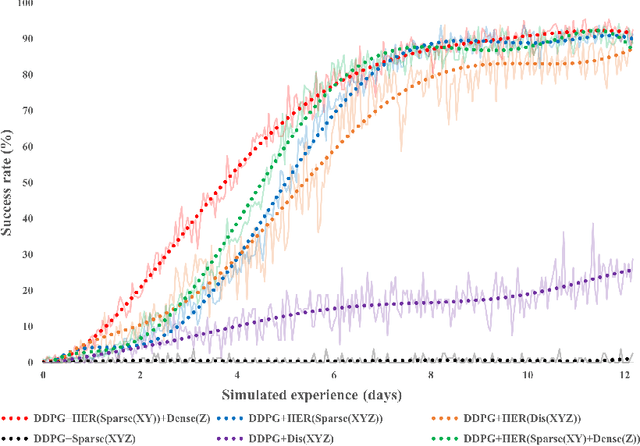
Model-based reinforcement learning is a promising learning strategy for practical robotic applications due to its improved data-efficiency versus model-free counterparts. However, current state-of-the-art model-based methods rely on shaped reward signals, which can be difficult to design and implement. To remedy this, we propose a simple model-based method tailored for sparse-reward multi-goal tasks that foregoes the need for complicated reward engineering. This approach, termed Imaginary Hindsight Experience Replay, minimises real-world interactions by incorporating imaginary data into policy updates. To improve exploration in the sparse-reward setting, the policy is trained with standard Hindsight Experience Replay and endowed with curiosity-based intrinsic rewards. Upon evaluation, this approach provides an order of magnitude increase in data-efficiency on average versus the state-of-the-art model-free method in the benchmark OpenAI Gym Fetch Robotics tasks.
Real Robot Challenge using Deep Reinforcement Learning
Sep 30, 2021


This paper details our winning submission to Phase 1 of the 2021 Real Robot Challenge, a challenge in which a three fingered robot must carry a cube along specified goal trajectories. To solve Phase 1, we use a pure reinforcement learning approach which requires minimal expert knowledge of the robotic system or of robotic grasping in general. A sparse goal-based reward is employed in conjunction with Hindsight Experience Replay to teach the control policy to move the cube to the desired x and y coordinates. Simultaneously, a dense distance-based reward is employed to teach the policy to lift the cube to the desired z coordinate. The policy is trained in simulation with domain randomization before being transferred to the real robot for evaluation. Although performance tends to worsen after this transfer, our best trained policy can successfully lift the real cube along goal trajectories via the use of an effective pinching grasp. Our approach outperforms all other submissions, including those leveraging more traditional robotic control techniques, and is the first learning-based approach to solve this challenge.
Estimating Lower Body Kinematics using a Lie Group Constrained Extended Kalman Filter and Reduced IMU Count
Mar 21, 2021
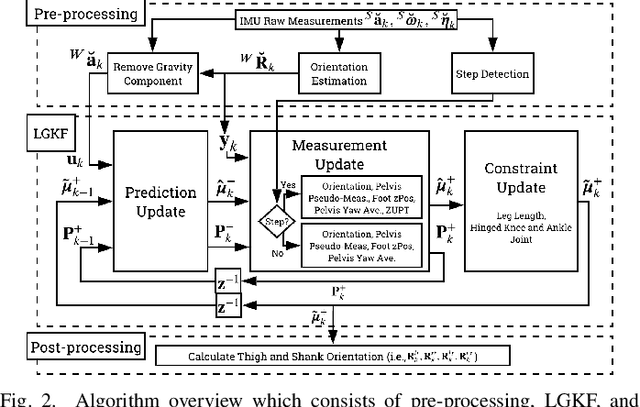
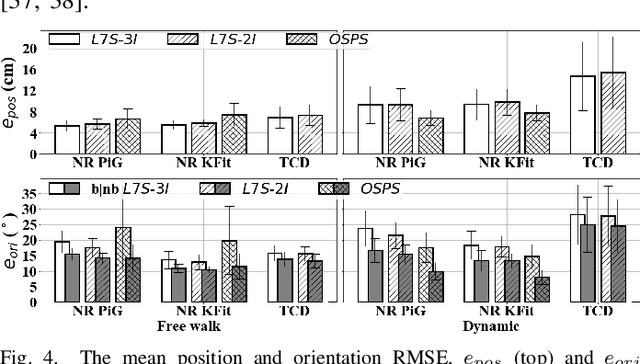
Goal: This paper presents an algorithm for estimating pelvis, thigh, shank, and foot kinematics during walking using only two or three wearable inertial sensors. Methods: The algorithm makes novel use of a Lie-group-based extended Kalman filter. The algorithm iterates through the prediction (kinematic equation), measurement (pelvis position pseudo-measurements, zero-velocity update, and flat-floor assumption), and constraint update (hinged knee and ankle joints, constant leg lengths). Results: The inertial motion capture algorithm was extensively evaluated on two datasets showing its performance against two standard benchmark approaches in optical motion capture (i.e., plug-in gait (commonly used in gait analysis) and a kinematic fit (commonly used in animation, robotics, and musculoskeleton simulation)), giving insight into the similarity and differences between the said approaches used in different application areas. The overall mean body segment position (relative to mid-pelvis origin) and orientation error magnitude of our algorithm ($n=14$ participants) for free walking was $5.93 \pm 1.33$ cm and $13.43 \pm 1.89^\circ$ when using three IMUs placed on the feet and pelvis, and $6.35 \pm 1.20$ cm and $12.71 \pm 1.60^\circ$ when using only two IMUs placed on the feet. Conclusion: The algorithm was able to track the joint angles in the sagittal plane for straight walking well, but requires improvement for unscripted movements (e.g., turning around, side steps), especially for dynamic movements or when considering clinical applications. Significance: This work has brought us closer to comprehensive remote gait monitoring using IMUs on the shoes. The low computational cost also suggests that it can be used in real-time with gait assistive devices.