 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDexterous Robotic Manipulation using Deep Reinforcement Learning and Knowledge Transfer for Complex Sparse Reward-based Tasks
Paper and Code
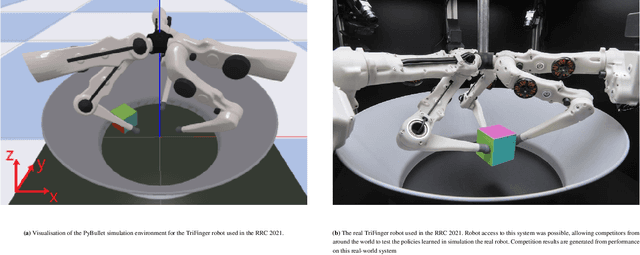

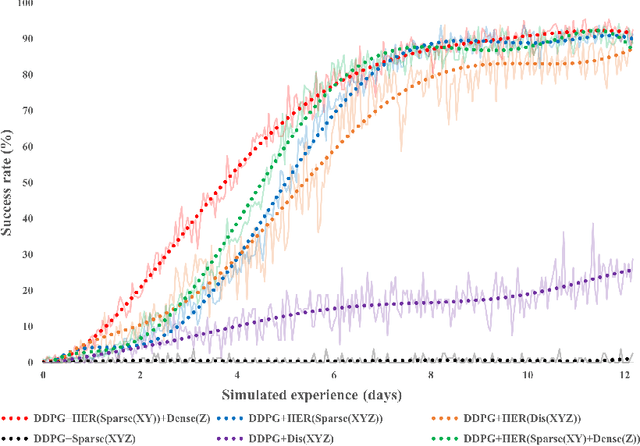

This paper describes a deep reinforcement learning (DRL) approach that won Phase 1 of the Real Robot Challenge (RRC) 2021, and then extends this method to a more difficult manipulation task. The RRC consisted of using a TriFinger robot to manipulate a cube along a specified positional trajectory, but with no requirement for the cube to have any specific orientation. We used a relatively simple reward function, a combination of goal-based sparse reward and distance reward, in conjunction with Hindsight Experience Replay (HER) to guide the learning of the DRL agent (Deep Deterministic Policy Gradient (DDPG)). Our approach allowed our agents to acquire dexterous robotic manipulation strategies in simulation. These strategies were then applied to the real robot and outperformed all other competition submissions, including those using more traditional robotic control techniques, in the final evaluation stage of the RRC. Here we extend this method, by modifying the task of Phase 1 of the RRC to require the robot to maintain the cube in a particular orientation, while the cube is moved along the required positional trajectory. The requirement to also orient the cube makes the agent unable to learn the task through blind exploration due to increased problem complexity. To circumvent this issue, we make novel use of a Knowledge Transfer (KT) technique that allows the strategies learned by the agent in the original task (which was agnostic to cube orientation) to be transferred to this task (where orientation matters). KT allowed the agent to learn and perform the extended task in the simulator, which improved the average positional deviation from 0.134 m to 0.02 m, and average orientation deviation from 142{\deg} to 76{\deg} during evaluation. This KT concept shows good generalisation properties and could be applied to any actor-critic learning algorithm.