Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs Independent Learning All You Need in the StarCraft Multi-Agent Challenge?
Paper and Code
Nov 18, 2020


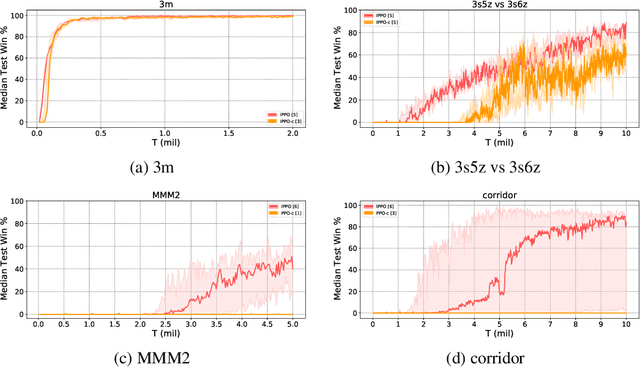
Most recently developed approaches to cooperative multi-agent reinforcement learning in the \emph{centralized training with decentralized execution} setting involve estimating a centralized, joint value function. In this paper, we demonstrate that, despite its various theoretical shortcomings, Independent PPO (IPPO), a form of independent learning in which each agent simply estimates its local value function, can perform just as well as or better than state-of-the-art joint learning approaches on popular multi-agent benchmark suite SMAC with little hyperparameter tuning. We also compare IPPO to several variants; the results suggest that IPPO's strong performance may be due to its robustness to some forms of environment non-stationarity.
View paper on