 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgerlpyt: A Research Code Base for Deep Reinforcement Learning in PyTorch
Paper and Code
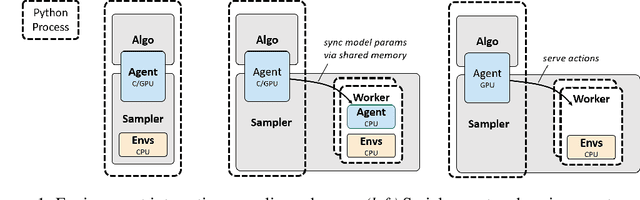

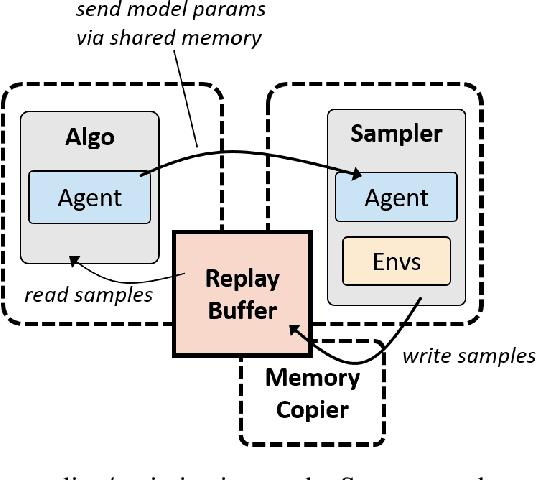
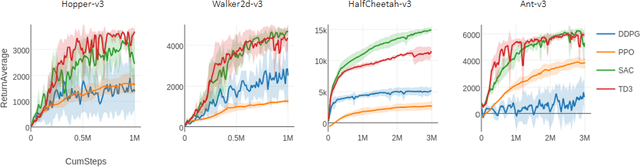
Since the recent advent of deep reinforcement learning for game play and simulated robotic control, a multitude of new algorithms have flourished. Most are model-free algorithms which can be categorized into three families: deep Q-learning, policy gradients, and Q-value policy gradients. These have developed along separate lines of research, such that few, if any, code bases incorporate all three kinds. Yet these algorithms share a great depth of common deep reinforcement learning machinery. We are pleased to share rlpyt, which implements all three algorithm families on top of a shared, optimized infrastructure, in a single repository. It contains modular implementations of many common deep RL algorithms in Python using PyTorch, a leading deep learning library. rlpyt is designed as a high-throughput code base for small- to medium-scale research in deep RL. This white paper summarizes its features, algorithms implemented, and relation to prior work, and concludes with detailed implementation and usage notes. rlpyt is available at https://github.com/astooke/rlpyt.