 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSLAM: A Unified Encoder for Speech and Language Modeling via Speech-Text Joint Pre-Training
Oct 20, 2021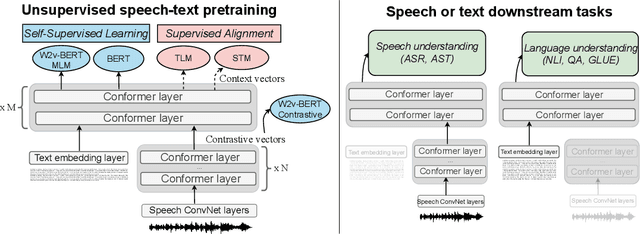
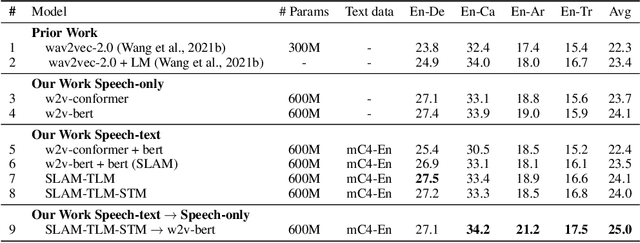
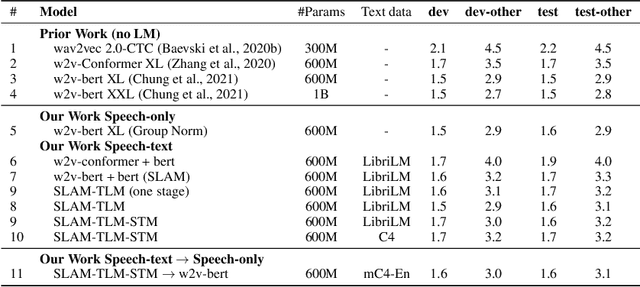
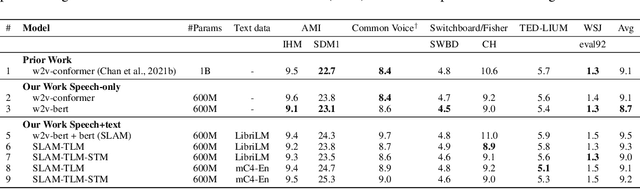
Unsupervised pre-training is now the predominant approach for both text and speech understanding. Self-attention models pre-trained on large amounts of unannotated data have been hugely successful when fine-tuned on downstream tasks from a variety of domains and languages. This paper takes the universality of unsupervised language pre-training one step further, by unifying speech and text pre-training within a single model. We build a single encoder with the BERT objective on unlabeled text together with the w2v-BERT objective on unlabeled speech. To further align our model representations across modalities, we leverage alignment losses, specifically Translation Language Modeling (TLM) and Speech Text Matching (STM) that make use of supervised speech-text recognition data. We demonstrate that incorporating both speech and text data during pre-training can significantly improve downstream quality on CoVoST~2 speech translation, by around 1 BLEU compared to single-modality pre-trained models, while retaining close to SotA performance on LibriSpeech and SpeechStew ASR tasks. On four GLUE tasks and text-normalization, we observe evidence of capacity limitations and interference between the two modalities, leading to degraded performance compared to an equivalent text-only model, while still being competitive with BERT. Through extensive empirical analysis we also demonstrate the importance of the choice of objective function for speech pre-training, and the beneficial effect of adding additional supervised signals on the quality of the learned representations.