 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActive Inference-Enabled Agentic Closed-Loop ISAC with Long-Horizon Planning
Apr 21, 2026Wireless agentic systems enable agents to autonomously perceive, reason, and act. However, existing works neglect the tight coupling between sensing and control in closed-loop integrated sensing and communication (ISAC) systems. In this paper, we propose an active inference (AIF)-driven wireless agentic system for closed-loop ISAC, which jointly optimizes control and sensing resource allocation via backward--forward message passing on a factor graph. The AIF agent maintains a generative model as a digital twin by integrating a localization model for uncertainty-aware state inference and a localization channel knowledge map (CKM) for approximating observation quality during planning. Simulation results demonstrate that the AIF-enabled agent adaptively allocates sensing resources based on spatially varying channel conditions, achieving superior balance among tracking accuracy, control effort, and sensing resource consumption over baseline strategies.
Semantic-based Distributed Learning for Diverse and Discriminative Representations
Apr 20, 2026In large-scale distributed scenarios, increasingly complex tasks demand more intelligent collaboration across networks, requiring the joint extraction of structural representations from data samples. However, conventional task-specific approaches often result in nonstructural embeddings, leading to collapsed variability among data samples within the same class, particularly in classification tasks. To address this issue and fully leverage the intrinsic structure of data for downstream applications, we propose a novel distributed learning framework that ensures both diverse and discriminative representations. For independent and identically distributed (i.i.d.) data, we reformulate and decouple the global optimization function by introducing constraints on representation variance. The update rules are then derived and simplified using a primal-dual approach. For non-i.i.d. data distributions, we tackle the problem by clustering and virtually replicating nodes, allowing model updates within each cluster using block coordinate descent. In both cases, the resulting optimal solutions are theoretically proven to maintain discriminative and diverse properties, with a guaranteed convergence for i.i.d. conditions. Additionally, semantic information from representations is shared among nodes, reducing the need for common neural network architectures. Finally, extensive simulations on MNIST, CIFAR-10 and CIFAR-100 confirm the effectiveness of the proposed algorithms in capturing global structural representations.
Quality-Aware Denoising of Ultra-Short TDoA Measurements for 5G-NR UAV Localization
Apr 09, 2026Reliable positioning is essential for Uncrewed Aerial Vehicles (UAVs) in safety-critical urban operations, yet achieving sub-meter accuracy under stringent latency constraints remains challenging. While 3rd Generation Partnership Project (3GPP) specifies repeated Positioning Reference Signals (PRS) transmissions for accurate Time Difference of Arrival (TDoA) measurements, denoising techniques specifically tailored for extremely limited measurement sequences within 3GPP frameworks remain underexplored. We propose Adaptive Gain Exponential Smoother (AGES), a lightweight filter combining exponentially weighted averaging with adaptive gains informed by 3GPP measurement quality reports. Simulations demonstrate AGES achieves 30-40% reduction in positioning error with only 3-5 repeated measurements while maintaining Fifth Generation New Radio (5G-NR) infrastructure compatibility.
Balancing Functionality and GDPR-Driven Privacy in ISAC Trajectory Sharing
Apr 09, 2026Integrated Sensing and Communications (ISAC) enables trajectory sharing that enhances beamforming, resource allocation, and cooperative perception, yet raises fundamental privacy concerns under the General Data Protection Regulation (GDPR) data minimisation principle. This paper proposes a Fisher Information Density (FID)-constrained trajectory sharing framework that enforces a local lower bound on estimation uncertainty, providing hard, quantifiable privacy guarantees by construction. Unlike fixed-noise approaches, the proposed method bounds the Privacy Leak Ratio (PLR) regardless of sensing power or adversarial post-processing, ensuring that no trajectory segment can be reconstructed beyond a prescribed accuracy threshold. Simulations on the OpenTraj dataset demonstrate that the framework keeps the average PLR below 20-25% and the maximum leakage segment duration under 2-2.5 s, while preserving data utility for downstream tasks such as movement prediction. The resulting criterion is interpretable, model-agnostic, and compatible with GDPR-compliant ISAC system design.
Compositional Distributed Learning for Multi-View Perception: A Maximal Coding Rate Reduction Perspective
Nov 11, 2025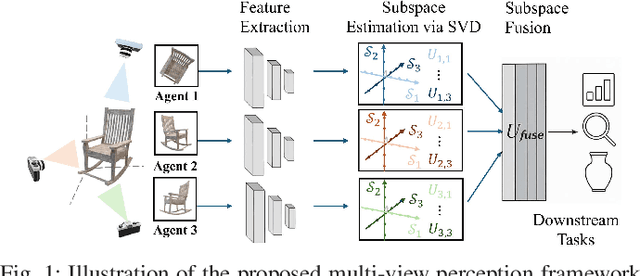
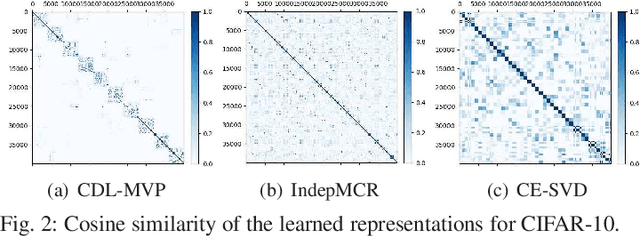

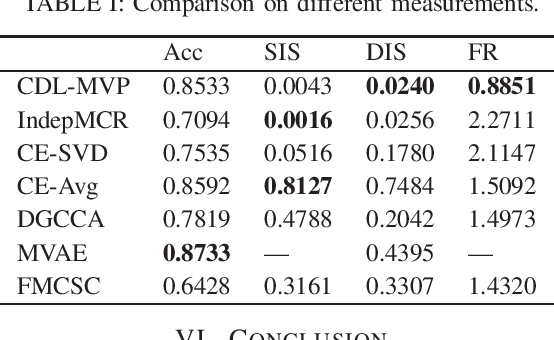
In this letter, we formulate a compositional distributed learning framework for multi-view perception by leveraging the maximal coding rate reduction principle combined with subspace basis fusion. In the proposed algorithm, each agent conducts a periodic singular value decomposition on its learned subspaces and exchanges truncated basis matrices, based on which the fused subspaces are obtained. By introducing a projection matrix and minimizing the distance between the outputs and its projection, the learned representations are enforced towards the fused subspaces. It is proved that the trace on the coding-rate change is bounded and the consistency of basis fusion is guaranteed theoretically. Numerical simulations validate that the proposed algorithm achieves high classification accuracy while maintaining representations' diversity, compared to baselines showing correlated subspaces and coupled representations.
SheafAlign: A Sheaf-theoretic Framework for Decentralized Multimodal Alignment
Oct 23, 2025Conventional multimodal alignment methods assume mutual redundancy across all modalities, an assumption that fails in real-world distributed scenarios. We propose SheafAlign, a sheaf-theoretic framework for decentralized multimodal alignment that replaces single-space alignment with multiple comparison spaces. This approach models pairwise modality relations through sheaf structures and leverages decentralized contrastive learning-based objectives for training. SheafAlign overcomes the limitations of prior methods by not requiring mutual redundancy among all modalities, preserving both shared and unique information. Experiments on multimodal sensing datasets show superior zero-shot generalization, cross-modal alignment, and robustness to missing modalities, with 50\% lower communication cost than state-of-the-art baselines.
Active Inference Framework for Closed-Loop Sensing, Communication, and Control in UAV Systems
Sep 17, 2025Integrated sensing and communication (ISAC) is a core technology for 6G, and its application to closed-loop sensing, communication, and control (SCC) enables various services. Existing SCC solutions often treat sensing and control separately, leading to suboptimal performance and resource usage. In this work, we introduce the active inference framework (AIF) into SCC-enabled unmanned aerial vehicle (UAV) systems for joint state estimation, control, and sensing resource allocation. By formulating a unified generative model, the problem reduces to minimizing variational free energy for inference and expected free energy for action planning. Simulation results show that both control cost and sensing cost are reduced relative to baselines.
Distributed Learning over Networks with Graph-Attention-Based Personalization
May 22, 2023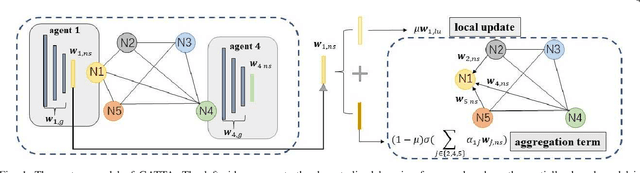
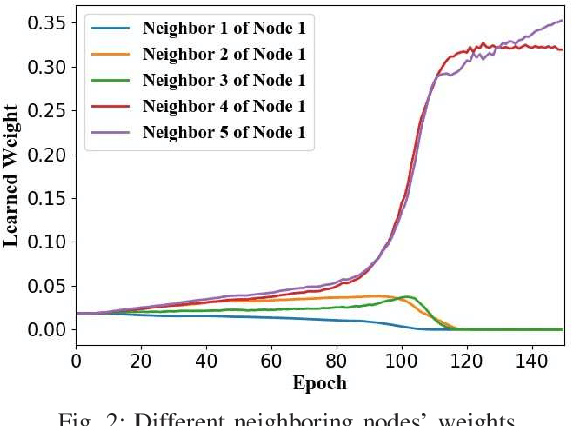
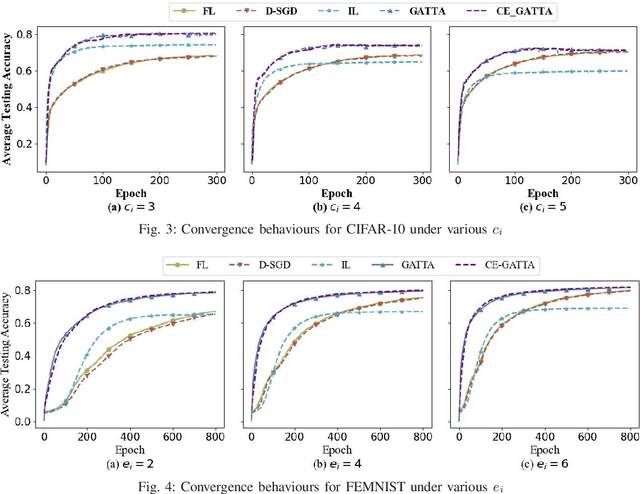
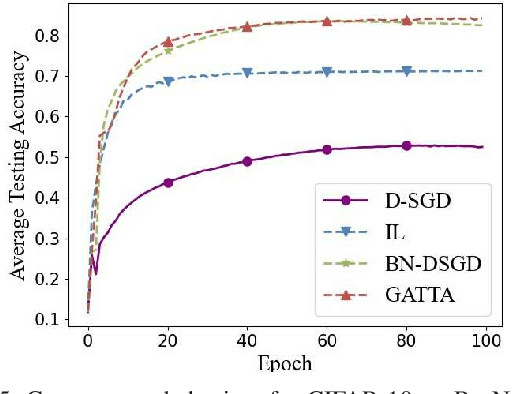
In conventional distributed learning over a network, multiple agents collaboratively build a common machine learning model. However, due to the underlying non-i.i.d. data distribution among agents, the unified learning model becomes inefficient for each agent to process its locally accessible data. To address this problem, we propose a graph-attention-based personalized training algorithm (GATTA) for distributed deep learning. The GATTA enables each agent to train its local personalized model while exploiting its correlation with neighboring nodes and utilizing their useful information for aggregation. In particular, the personalized model in each agent is composed of a global part and a node-specific part. By treating each agent as one node in a graph and the node-specific parameters as its features, the benefits of the graph attention mechanism can be inherited. Namely, instead of aggregation based on averaging, it learns the specific weights for different neighboring nodes without requiring prior knowledge about the graph structure or the neighboring nodes' data distribution. Furthermore, relying on the weight-learning procedure, we develop a communication-efficient GATTA by skipping the transmission of information with small aggregation weights. Additionally, we theoretically analyze the convergence properties of GATTA for non-convex loss functions. Numerical results validate the excellent performances of the proposed algorithms in terms of convergence and communication cost.
Distributed ADMM with Synergetic Communication and Computation
Sep 29, 2020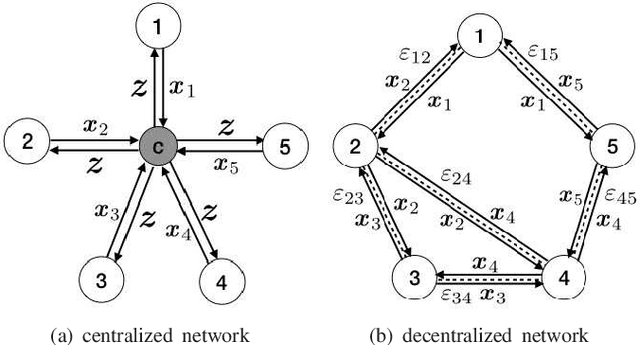
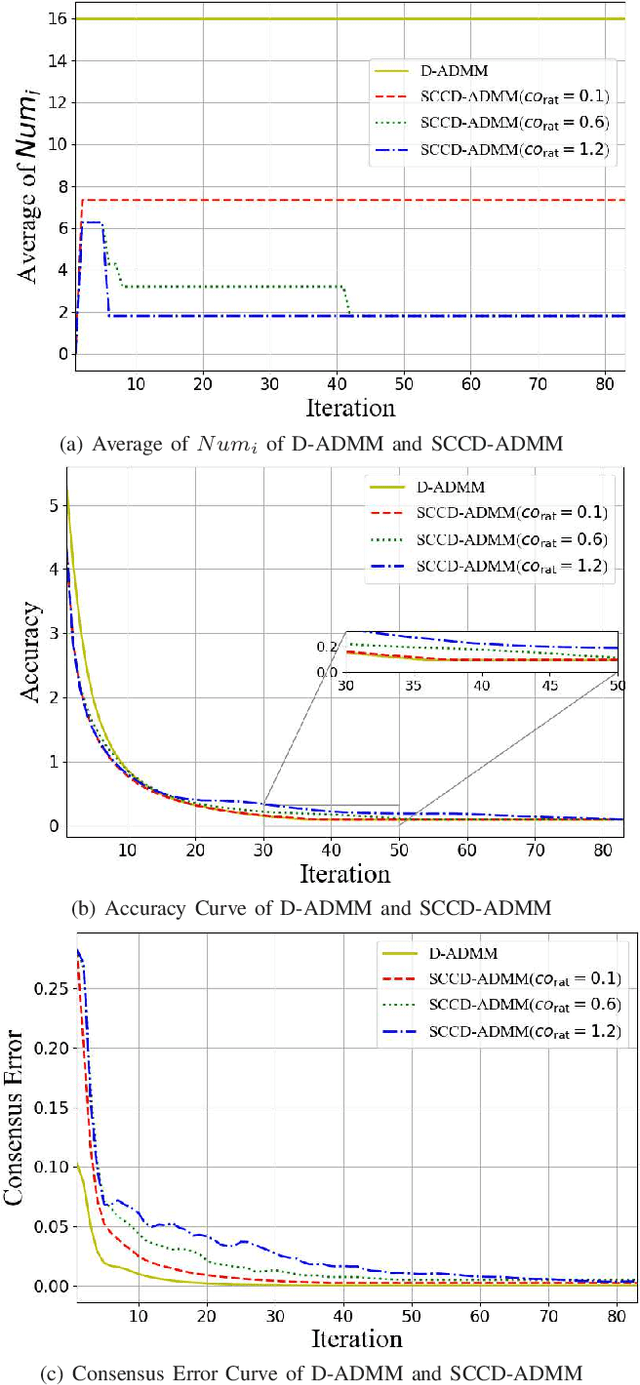
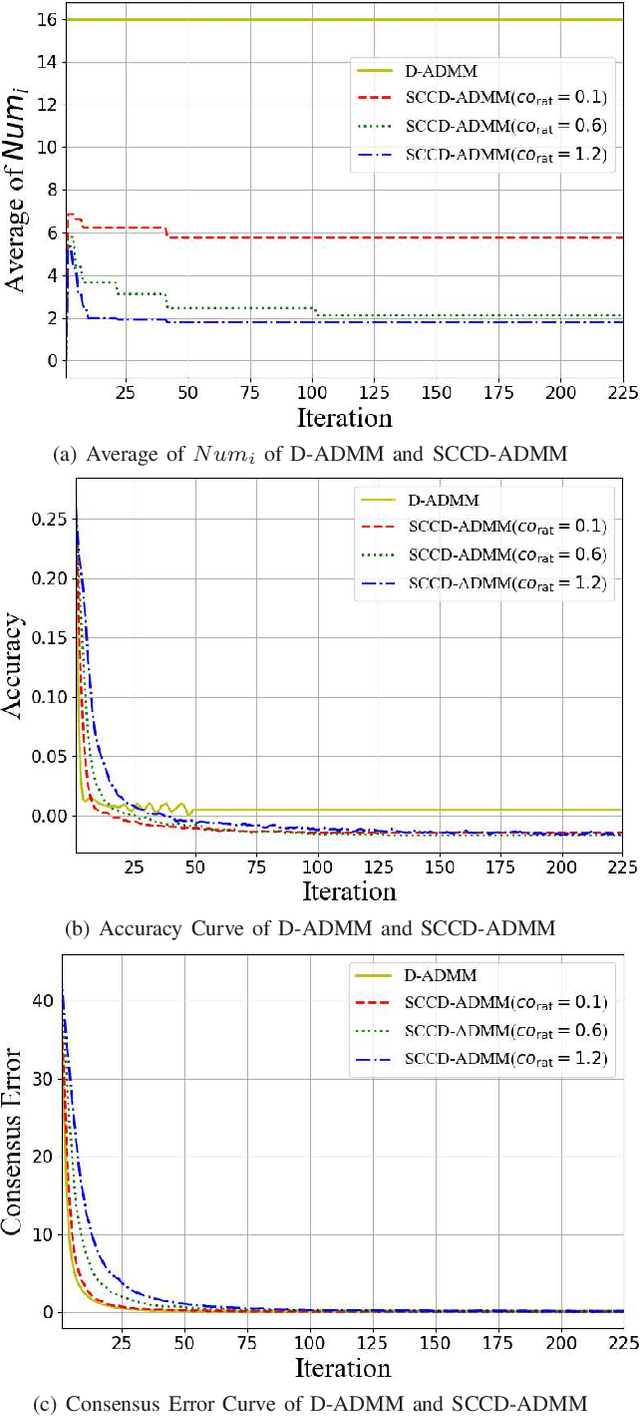
In this paper, we propose a novel distributed alternating direction method of multipliers (ADMM) algorithm with synergetic communication and computation, called SCCD-ADMM, to reduce the total communication and computation cost of the system. Explicitly, in the proposed algorithm, each node interacts with only part of its neighboring nodes, the number of which is progressively determined according to a heuristic searching procedure, which takes into account both the predicted convergence rate and the communication and computation costs at each iteration, resulting in a trade-off between communication and computation. Then the node chooses its neighboring nodes according to an importance sampling distribution derived theoretically to minimize the variance with the latest information it locally stores. Finally, the node updates its local information with a new update rule which adapts to the number of communication nodes. We prove the convergence of the proposed algorithm and provide an upper bound of the convergence variance brought by randomness. Extensive simulations validate the excellent performances of the proposed algorithm in terms of convergence rate and variance, the overall communication and computation cost, the impact of network topology as well as the time for evaluation, in comparison with the traditional counterparts.