 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSheafAlign: A Sheaf-theoretic Framework for Decentralized Multimodal Alignment
Oct 23, 2025Conventional multimodal alignment methods assume mutual redundancy across all modalities, an assumption that fails in real-world distributed scenarios. We propose SheafAlign, a sheaf-theoretic framework for decentralized multimodal alignment that replaces single-space alignment with multiple comparison spaces. This approach models pairwise modality relations through sheaf structures and leverages decentralized contrastive learning-based objectives for training. SheafAlign overcomes the limitations of prior methods by not requiring mutual redundancy among all modalities, preserving both shared and unique information. Experiments on multimodal sensing datasets show superior zero-shot generalization, cross-modal alignment, and robustness to missing modalities, with 50\% lower communication cost than state-of-the-art baselines.
Scalable and Resource-Efficient Second-Order Federated Learning via Over-the-Air Aggregation
Oct 10, 2024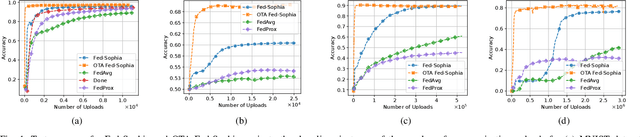

Second-order federated learning (FL) algorithms offer faster convergence than their first-order counterparts by leveraging curvature information. However, they are hindered by high computational and storage costs, particularly for large-scale models. Furthermore, the communication overhead associated with large models and digital transmission exacerbates these challenges, causing communication bottlenecks. In this work, we propose a scalable second-order FL algorithm using a sparse Hessian estimate and leveraging over-the-air aggregation, making it feasible for larger models. Our simulation results demonstrate more than $67\%$ of communication resources and energy savings compared to other first and second-order baselines.