 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntent Profiling and Translation Through Emergent Communication
Feb 05, 2024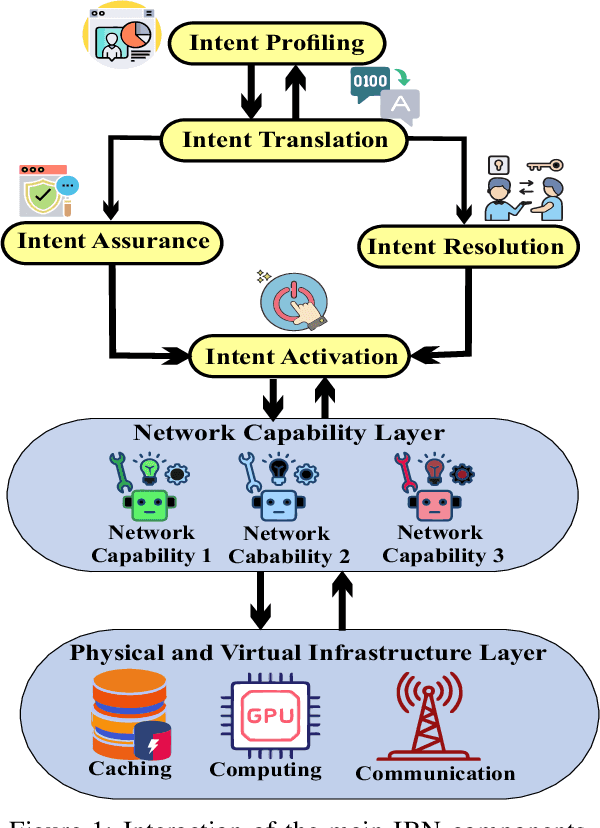
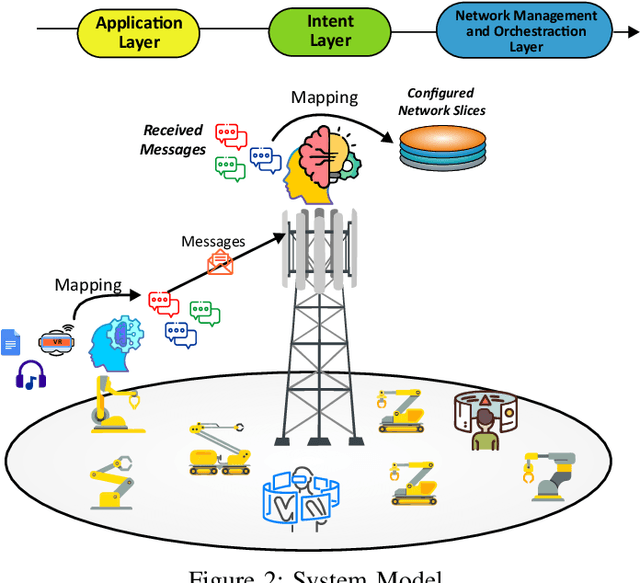
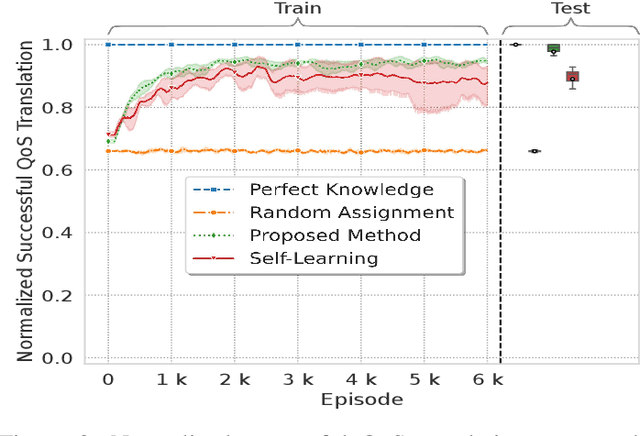
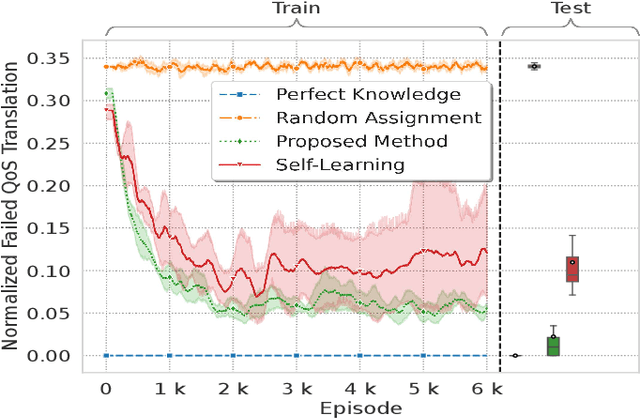
To effectively express and satisfy network application requirements, intent-based network management has emerged as a promising solution. In intent-based methods, users and applications express their intent in a high-level abstract language to the network. Although this abstraction simplifies network operation, it induces many challenges to efficiently express applications' intents and map them to different network capabilities. Therefore, in this work, we propose an AI-based framework for intent profiling and translation. We consider a scenario where applications interacting with the network express their needs for network services in their domain language. The machine-to-machine communication (i.e., between applications and the network) is complex since it requires networks to learn how to understand the domain languages of each application, which is neither practical nor scalable. Instead, a framework based on emergent communication is proposed for intent profiling, in which applications express their abstract quality-of-experience (QoE) intents to the network through emergent communication messages. Subsequently, the network learns how to interpret these communication messages and map them to network capabilities (i.e., slices) to guarantee the requested Quality-of-Service (QoS). Simulation results show that the proposed method outperforms self-learning slicing and other baselines, and achieves a performance close to the perfect knowledge baseline.
Cooperative Multi-Agent Learning for Navigation via Structured State Abstraction
Jun 20, 2023



Cooperative multi-agent reinforcement learning (MARL) for navigation enables agents to cooperate to achieve their navigation goals. Using emergent communication, agents learn a communication protocol to coordinate and share information that is needed to achieve their navigation tasks. In emergent communication, symbols with no pre-specified usage rules are exchanged, in which the meaning and syntax emerge through training. Learning a navigation policy along with a communication protocol in a MARL environment is highly complex due to the huge state space to be explored. To cope with this complexity, this work proposes a novel neural network architecture, for jointly learning an adaptive state space abstraction and a communication protocol among agents participating in navigation tasks. The goal is to come up with an adaptive abstractor that significantly reduces the size of the state space to be explored, without degradation in the policy performance. Simulation results show that the proposed method reaches a better policy, in terms of achievable rewards, resulting in fewer training iterations compared to the case where raw states or fixed state abstraction are used. Moreover, it is shown that a communication protocol emerges during training which enables the agents to learn better policies within fewer training iterations.
Cross Layer Optimization and Distributed Reinforcement Learning Approach for Tile-Based 360 Degree Wireless Video Streaming
Nov 12, 2020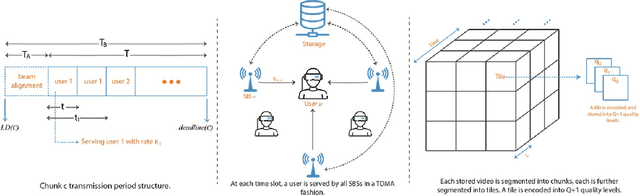
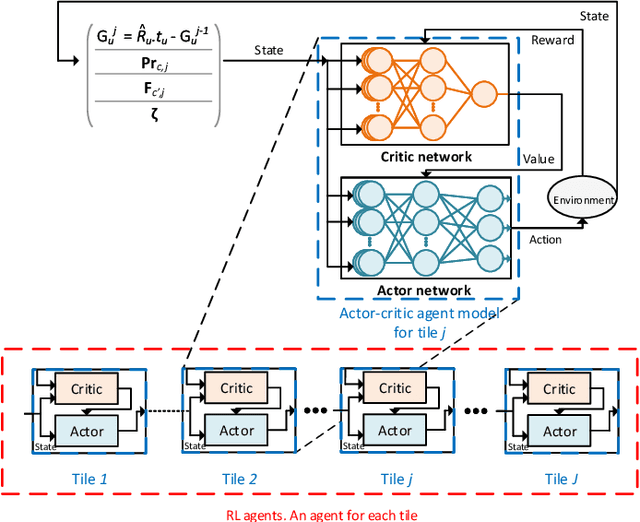

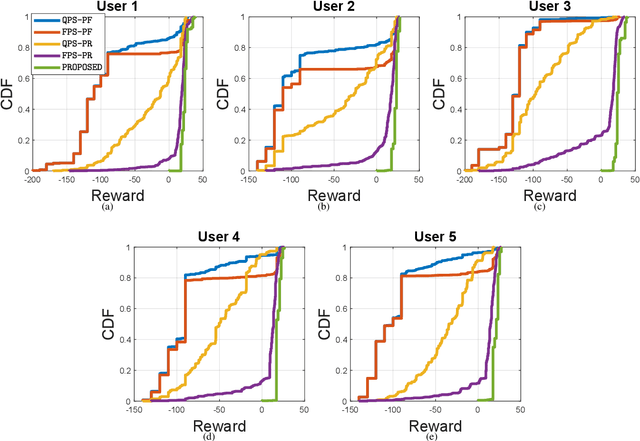
Wirelessly streaming high quality 360 degree videos is still a challenging problem. When there are many users watching different 360 degree videos and competing for the computing and communication resources, the streaming algorithm at hand should maximize the average quality of experience (QoE) while guaranteeing a minimum rate for each user. In this paper, we propose a \emph{cross layer} optimization approach that maximizes the available rate to each user and efficiently uses it to maximize users' QoE. Particularly, we consider a tile based 360 degree video streaming, and we optimize a QoE metric that balances the tradeoff between maximizing each user's QoE and ensuring fairness among users. We show that the problem can be decoupled into two interrelated subproblems: (i) a physical layer subproblem whose objective is to find the download rate for each user, and (ii) an application layer subproblem whose objective is to use that rate to find a quality decision per tile such that the user's QoE is maximized. We prove that the physical layer subproblem can be solved optimally with low complexity and an actor-critic deep reinforcement learning (DRL) is proposed to leverage the parallel training of multiple independent agents and solve the application layer subproblem. Extensive experiments reveal the robustness of our scheme and demonstrate its significant performance improvement compared to several baseline algorithms.