 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommunication-Efficient On-Device Machine Learning: Federated Distillation and Augmentation under Non-IID Private Data
Paper and Code
Nov 28, 2018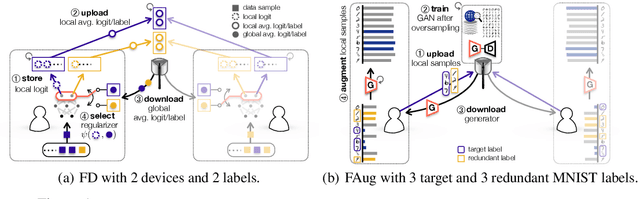

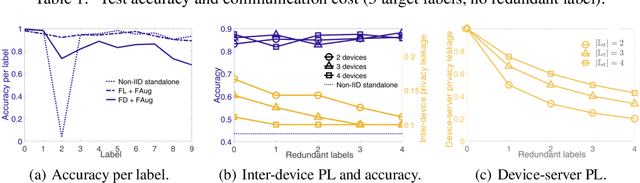
On-device machine learning (ML) enables the training process to exploit a massive amount of user-generated private data samples. To enjoy this benefit, inter-device communication overhead should be minimized. With this end, we propose federated distillation (FD), a distributed model training algorithm whose communication payload size is much smaller than a benchmark scheme, federated learning (FL), particularly when the model size is large. Moreover, user-generated data samples are likely to become non-IID across devices, which commonly degrades the performance compared to the case with an IID dataset. To cope with this, we propose federated augmentation (FAug), where each device collectively trains a generative model, and thereby augments its local data towards yielding an IID dataset. Empirical studies demonstrate that FD with FAug yields around 26x less communication overhead while achieving 95-98% test accuracy compared to FL.