 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProxy Experience Replay: Federated Distillation for Distributed Reinforcement Learning
Paper and Code
May 15, 2020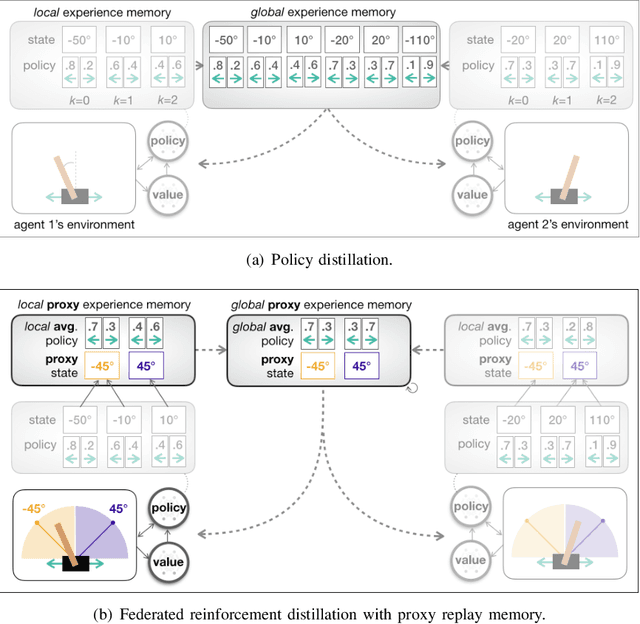
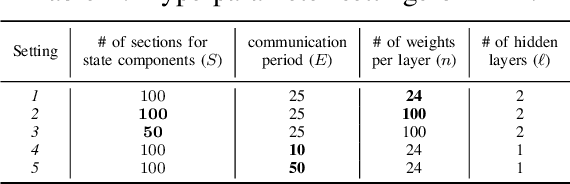
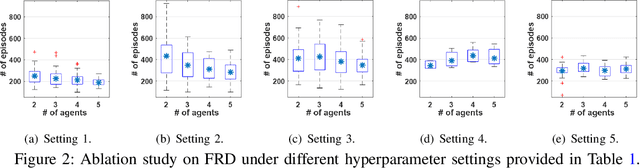
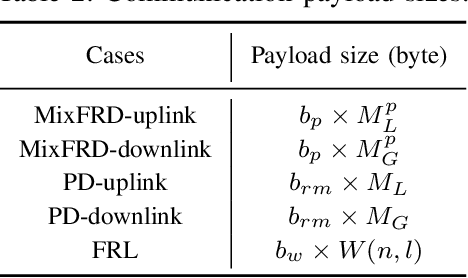
Traditional distributed deep reinforcement learning (RL) commonly relies on exchanging the experience replay memory (RM) of each agent. Since the RM contains all state observations and action policy history, it may incur huge communication overhead while violating the privacy of each agent. Alternatively, this article presents a communication-efficient and privacy-preserving distributed RL framework, coined federated reinforcement distillation (FRD). In FRD, each agent exchanges its proxy experience replay memory (ProxRM), in which policies are locally averaged with respect to proxy states clustering actual states. To provide FRD design insights, we present ablation studies on the impact of ProxRM structures, neural network architectures, and communication intervals. Furthermore, we propose an improved version of FRD, coined mixup augmented FRD (MixFRD), in which ProxRM is interpolated using the mixup data augmentation algorithm. Simulations in a Cartpole environment validate the effectiveness of MixFRD in reducing the variance of mission completion time and communication cost, compared to the benchmark schemes, vanilla FRD, federated reinforcement learning (FRL), and policy distillation (PD).