 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrior-Guided Movable Antenna Control for Agile Multi-Path Sensing (extended version)
Apr 13, 2026Multi-path sensing, which aims to extract the geometric attributes of multiple propagation paths, is expected to be a key functionality of 6G. A movable antenna (MA) can enable this functionality by creating a synthetic aperture through sequential mechanical motion. However, existing MA-based sensing methods typically rely on exhaustive scanning over the entire movable plate, resulting in significant control overhead and sensing latency, which limits their practicality for agile sensing. To address this challenge, this paper develops a prior-guided agile multi-path sensing framework that leverages weak prior angle-of-arrival (AoA) statistics as side information. The proposed framework comprises two steps. First, the movable plate's three-dimensional orientation is optimized only once to maximize path visibility while preserving path discriminability, both induced from Fisher information analysis. Second, only two predetermined linear MA scans are made on the tilted plate to estimate the elevation and azimuth AoAs from the resulting sequence of received signals. By incorporating the prior AoA statistics, a maximum a posteriori (MAP)-based AoA estimation algorithm is developed. With only one orientation control and two linear scans, the proposed framework enables agile multi-path sensing with significantly reduced control overhead and latency, while achieving AoA estimation accuracy approaching that of the single-path benchmark.
Vision-Language-Model-Guided Differentiable Ray Tracing for Fast and Accurate Multi-Material RF Parameter Estimation
Jan 26, 2026Accurate radio-frequency (RF) material parameters are essential for electromagnetic digital twins in 6G systems, yet gradient-based inverse ray tracing (RT) remains sensitive to initialization and costly under limited measurements. This paper proposes a vision-language-model (VLM) guided framework that accelerates and stabilizes multi-material parameter estimation in a differentiable RT (DRT) engine. A VLM parses scene images to infer material categories and maps them to quantitative priors via an ITU-R material table, yielding informed conductivity initializations. The VLM further selects informative transmitter/receiver placements that promote diverse, material-discriminative paths. Starting from these priors, the DRT performs gradient-based refinement using measured received signal strengths. Experiments in NVIDIA Sionna on indoor scenes show 2-4$\times$ faster convergence and 10-100$\times$ lower final parameter error compared with uniform or random initialization and random placement baselines, achieving sub-0.1\% mean relative error with only a few receivers. Complexity analyses indicate per-iteration time scales near-linearly with the number of materials and measurement setups, while VLM-guided placement reduces the measurements required for accurate recovery. Ablations over RT depth and ray counts confirm further accuracy gains without significant per-iteration overhead. Results demonstrate that semantic priors from VLMs effectively guide physics-based optimization for fast and reliable RF material estimation.
Communication-Efficient Hybrid Language Model via Uncertainty-Aware Opportunistic and Compressed Transmission
May 17, 2025To support emerging language-based applications using dispersed and heterogeneous computing resources, the hybrid language model (HLM) offers a promising architecture, where an on-device small language model (SLM) generates draft tokens that are validated and corrected by a remote large language model (LLM). However, the original HLM suffers from substantial communication overhead, as the LLM requires the SLM to upload the full vocabulary distribution for each token. Moreover, both communication and computation resources are wasted when the LLM validates tokens that are highly likely to be accepted. To overcome these limitations, we propose communication-efficient and uncertainty-aware HLM (CU-HLM). In CU-HLM, the SLM transmits truncated vocabulary distributions only when its output uncertainty is high. We validate the feasibility of this opportunistic transmission by discovering a strong correlation between SLM's uncertainty and LLM's rejection probability. Furthermore, we theoretically derive optimal uncertainty thresholds and optimal vocabulary truncation strategies. Simulation results show that, compared to standard HLM, CU-HLM achieves up to 206$\times$ higher token throughput by skipping 74.8% transmissions with 97.4% vocabulary compression, while maintaining 97.4% accuracy.
Uncertainty-Aware Hybrid Inference with On-Device Small and Remote Large Language Models
Dec 17, 2024



This paper studies a hybrid language model (HLM) architecture that integrates a small language model (SLM) operating on a mobile device with a large language model (LLM) hosted at the base station (BS) of a wireless network. The HLM token generation process follows the speculative inference principle: the SLM's vocabulary distribution is uploaded to the LLM, which either accepts or rejects it, with rejected tokens being resampled by the LLM. While this approach ensures alignment between the vocabulary distributions of the SLM and LLM, it suffers from low token throughput due to uplink transmission and the computation costs of running both language models. To address this, we propose a novel HLM structure coined Uncertainty-aware HLM (U-HLM), wherein the SLM locally measures its output uncertainty, and skips both uplink transmissions and LLM operations for tokens that are likely to be accepted. This opportunistic skipping is enabled by our empirical finding of a linear correlation between the SLM's uncertainty and the LLM's rejection probability. We analytically derive the uncertainty threshold and evaluate its expected risk of rejection. Simulations show that U-HLM reduces uplink transmissions and LLM computation by 45.93%, while achieving up to 97.54% of the LLM's inference accuracy and 2.54$\times$ faster token throughput than HLM without skipping.
Near-Field Localization with RIS via Two-Dimensional Signal Path Classification
May 29, 2024



In this paper, we propose two-dimensional signal path classification (2D-SPC) for reconfigurable intelligent surface (RIS)-assisted near-field (NF) localization. In the NF regime, multiple RIS-driven signal paths (SPs) can contribute to precise localization if these are decomposable and the reflected locations on the RIS are known, referred to as SP decomposition (SPD) and SP labeling (SPL), respectively. To this end, each RIS element modulates the incoming SP's phase by shifting it by one of the values in the phase shift profile (PSP) lists satisfying resolution requirements. By interworking with a conventional orthogonal frequency division multiplexing (OFDM) waveform, the user equipment can construct a 2D spectrum map that couples each SPs time of arrival (ToA) and PSP. Then, we design SPL by mapping SPs with the corresponding reflected RIS elements when they share the same PSP. Given two unlabeled SPs, we derive a geometric discriminant from checking whether the current label is correct. It can be extended to more than three SPs by sorting them using pairwise geometric discriminants between adjacent ones. From simulation results, it has been demonstrated that the proposed 2D SPC achieves consistent localization accuracy even if insufficient PSPs are given.
Energy-Efficient Edge Learning via Joint Data Deepening-and-Prefetching
Feb 19, 2024The vision of pervasive artificial intelligence (AI) services can be realized by training an AI model on time using real-time data collected by internet of things (IoT) devices. To this end, IoT devices require offloading their data to an edge server in proximity. However, transmitting high-dimensional and voluminous data from energy-constrained IoT devices poses a significant challenge. To address this limitation, we propose a novel offloading architecture, called joint data deepening-and-prefetching (JD2P), which is feature-by-feature offloading comprising two key techniques. The first one is data deepening, where each data sample's features are sequentially offloaded in the order of importance determined by the data embedding technique such as principle component analysis (PCA). Offloading is terminated once the already transmitted features are sufficient for accurate data classification, resulting in a reduction in the amount of transmitted data. The criteria to offload data are derived for binary and multi-class classifiers, which are designed based on support vector machine (SVM) and deep neural network (DNN), respectively. The second one is data prefetching, where some features potentially required in the future are offloaded in advance, thus achieving high efficiency via precise prediction and parameter optimization. We evaluate the effectiveness of JD2P through experiments using the MNIST dataset, and the results demonstrate its significant reduction in expected energy consumption compared to several benchmarks without degrading learning accuracy.
Mobility-Induced Graph Learning for WiFi Positioning
Nov 14, 2023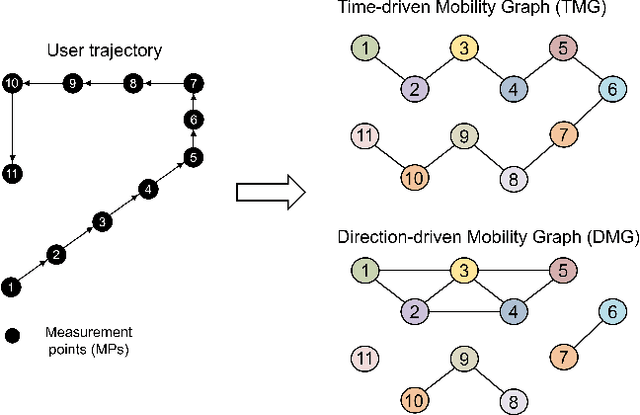

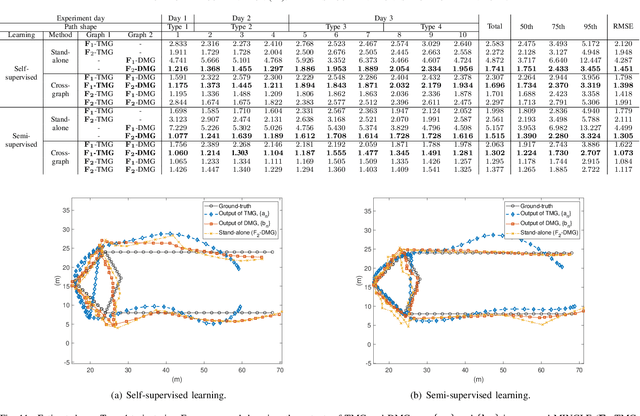
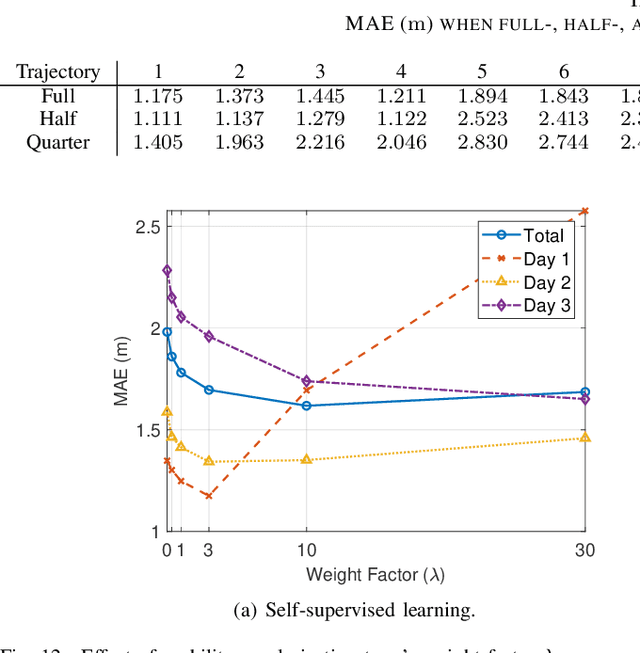
A smartphone-based user mobility tracking could be effective in finding his/her location, while the unpredictable error therein due to low specification of built-in inertial measurement units (IMUs) rejects its standalone usage but demands the integration to another positioning technique like WiFi positioning. This paper aims to propose a novel integration technique using a graph neural network called Mobility-INduced Graph LEarning (MINGLE), which is designed based on two types of graphs made by capturing different user mobility features. Specifically, considering sequential measurement points (MPs) as nodes, a user's regular mobility pattern allows us to connect neighbor MPs as edges, called time-driven mobility graph (TMG). Second, a user's relatively straight transition at a constant pace when moving from one position to another can be captured by connecting the nodes on each path, called a direction-driven mobility graph (DMG). Then, we can design graph convolution network (GCN)-based cross-graph learning, where two different GCN models for TMG and DMG are jointly trained by feeding different input features created by WiFi RTTs yet sharing their weights. Besides, the loss function includes a mobility regularization term such that the differences between adjacent location estimates should be less variant due to the user's stable moving pace. Noting that the regularization term does not require ground-truth location, MINGLE can be designed under semi- and self-supervised learning frameworks. The proposed MINGLE's effectiveness is extensively verified through field experiments, showing a better positioning accuracy than benchmarks, say root mean square errors (RMSEs) being 1.398 (m) and 1.073 (m) for self- and semi-supervised learning cases, respectively.
Towards Semantic Communication Protocols for 6G: From Protocol Learning to Language-Oriented Approaches
Oct 14, 2023



The forthcoming 6G systems are expected to address a wide range of non-stationary tasks. This poses challenges to traditional medium access control (MAC) protocols that are static and predefined. In response, data-driven MAC protocols have recently emerged, offering ability to tailor their signaling messages for specific tasks. This article presents a novel categorization of these data-driven MAC protocols into three levels: Level 1 MAC. task-oriented neural protocols constructed using multi-agent deep reinforcement learning (MADRL); Level 2 MAC. neural network-oriented symbolic protocols developed by converting Level 1 MAC outputs into explicit symbols; and Level 3 MAC. language-oriented semantic protocols harnessing large language models (LLMs) and generative models. With this categorization, we aim to explore the opportunities and challenges of each level by delving into their foundational techniques. Drawing from information theory and associated principles as well as selected case studies, this study provides insights into the trajectory of data-driven MAC protocols and sheds light on future research directions.
Semantics Alignment via Split Learning for Resilient Multi-User Semantic Communication
Oct 13, 2023



Recent studies on semantic communication commonly rely on neural network (NN) based transceivers such as deep joint source and channel coding (DeepJSCC). Unlike traditional transceivers, these neural transceivers are trainable using actual source data and channels, enabling them to extract and communicate semantics. On the flip side, each neural transceiver is inherently biased towards specific source data and channels, making different transceivers difficult to understand intended semantics, particularly upon their initial encounter. To align semantics over multiple neural transceivers, we propose a distributed learning based solution, which leverages split learning (SL) and partial NN fine-tuning techniques. In this method, referred to as SL with layer freezing (SLF), each encoder downloads a misaligned decoder, and locally fine-tunes a fraction of these encoder-decoder NN layers. By adjusting this fraction, SLF controls computing and communication costs. Simulation results confirm the effectiveness of SLF in aligning semantics under different source data and channel dissimilarities, in terms of classification accuracy, reconstruction errors, and recovery time for comprehending intended semantics from misalignment.
Enabling AI Quality Control via Feature Hierarchical Edge Inference
Nov 15, 2022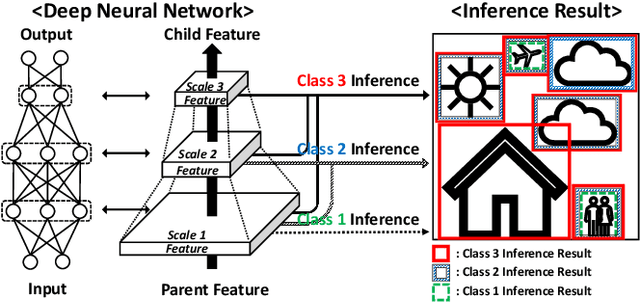
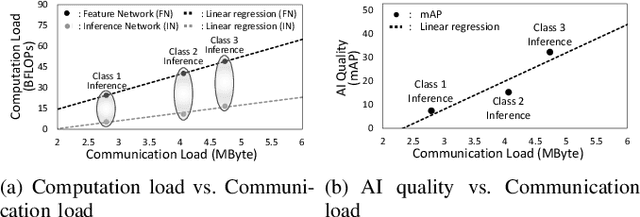
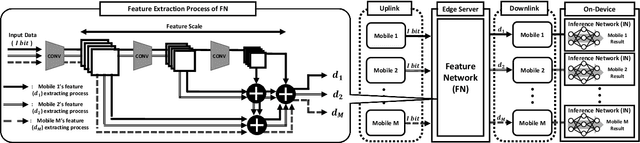
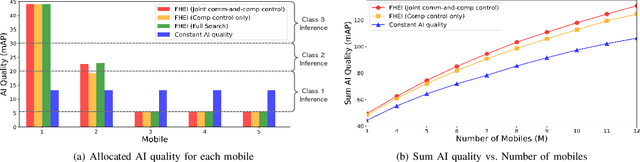
With the rise of edge computing, various AI services are expected to be available at a mobile side through the inference based on deep neural network (DNN) operated at the network edge, called edge inference (EI). On the other hand, the resulting AI quality (e.g., mean average precision in objective detection) has been regarded as a given factor, and AI quality control has yet to be explored despite its importance in addressing the diverse demands of different users. This work aims at tackling the issue by proposing a feature hierarchical EI (FHEI), comprising feature network and inference network deployed at an edge server and corresponding mobile, respectively. Specifically, feature network is designed based on feature hierarchy, a one-directional feature dependency with a different scale. A higher scale feature requires more computation and communication loads while it provides a better AI quality. The tradeoff enables FHEI to control AI quality gradually w.r.t. communication and computation loads, leading to deriving a near-to-optimal solution to maximize multi-user AI quality under the constraints of uplink \& downlink transmissions and edge server and mobile computation capabilities. It is verified by extensive simulations that the proposed joint communication-and-computation control on FHEI architecture always outperforms several benchmarks by differentiating each user's AI quality depending on the communication and computation conditions.