 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecoding with Limited Teacher Supervision Requires Understanding When to Trust the Teacher
Paper and Code
Jun 26, 2024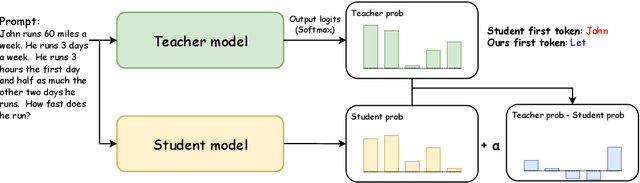
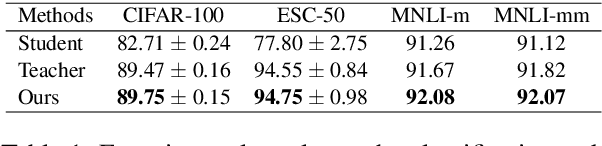
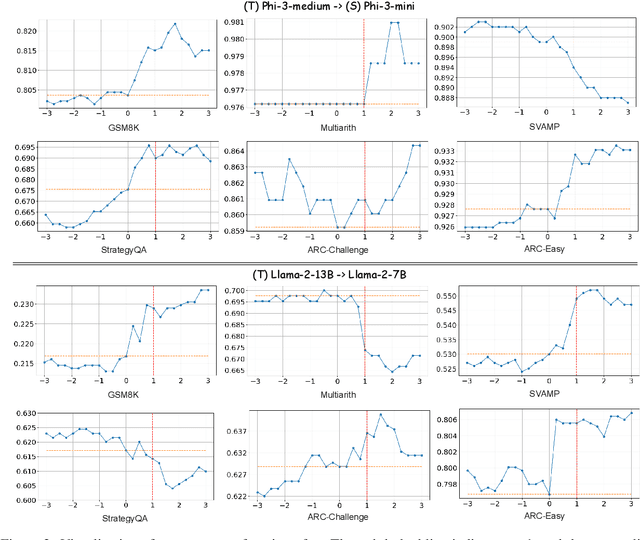
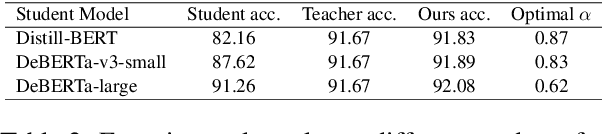
How can sLLMs efficiently utilize the supervision of LLMs to improve their generative quality? This question has been well studied in scenarios where there is no restriction on the number of LLM supervisions one can use, giving birth to many decoding algorithms that utilize supervision without further training. However, it is still unclear what is an effective strategy under the limited supervision scenario, where we assume that no more than a few tokens can be generated by LLMs. To this end, we develop an algorithm to effectively aggregate the sLLM and LLM predictions on initial tokens so that the generated tokens can more accurately condition the subsequent token generation by sLLM only. Critically, we find that it is essential to adaptively overtrust or disregard the LLM prediction based on the confidence of the sLLM. Through our experiments on a wide range of models and datasets, we demonstrate that our method provides a consistent improvement over conventional decoding strategies.