 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLost in the Prompt Order: Revealing the Limitations of Causal Attention in Language Models
Jan 20, 2026Large language models exhibit surprising sensitivity to the structure of the prompt, but the mechanisms underlying this sensitivity remain poorly understood. In this work, we conduct an in-depth investigation on a striking case: in multiple-choice question answering, placing context before the questions and options (CQO) outperforms the reverse order (QOC) by over 14%p, consistently over a wide range of models and datasets. Through systematic architectural analysis, we identify causal attention as the core mechanism: in QOC prompts, the causal mask prevents option tokens from attending to context, creating an information bottleneck where context becomes invisible to options.
Speculative End-Turn Detector for Efficient Speech Chatbot Assistant
Mar 30, 2025



Spoken dialogue systems powered by large language models have demonstrated remarkable abilities in understanding human speech and generating appropriate spoken responses. However, these systems struggle with end-turn detection (ETD) -- the ability to distinguish between user turn completion and hesitation. This limitation often leads to premature or delayed responses, disrupting the flow of spoken conversations. In this paper, we introduce the ETD Dataset, the first public dataset for end-turn detection. The ETD dataset consists of both synthetic speech data generated with text-to-speech models and real-world speech data collected from web sources. We also propose SpeculativeETD, a novel collaborative inference framework that balances efficiency and accuracy to improve real-time ETD in resource-constrained environments. Our approach jointly employs a lightweight GRU-based model, which rapidly detects the non-speaking units in real-time on local devices, and a high-performance Wav2vec-based model running on the server to make a more challenging classification of distinguishing turn ends from mere pauses. Experiments demonstrate that the proposed SpeculativeETD significantly improves ETD accuracy while keeping the required computations low. Datasets and code will be available after the review.
Imagine to Hear: Auditory Knowledge Generation can be an Effective Assistant for Language Models
Mar 21, 2025Language models pretrained on text-only corpora often struggle with tasks that require auditory commonsense knowledge. Previous work addresses this problem by augmenting the language model to retrieve knowledge from external audio databases. This approach has several limitations, such as the potential lack of relevant audio in databases and the high costs associated with constructing and querying the databases. To address these issues, we propose Imagine to Hear, a novel approach that dynamically generates auditory knowledge using generative models. Our framework detects multiple audio-related textual spans from the given prompt and generates corresponding auditory knowledge. We develop several mechanisms to efficiently process multiple auditory knowledge, including a CLAP-based rejection sampler and a language-audio fusion module. Our experiments show that our method achieves state-of-the-art performance on AuditoryBench without relying on external databases, highlighting the effectiveness of our generation-based approach.
Constructing a Singing Style Caption Dataset
Sep 15, 2024



Singing voice synthesis and conversion have emerged as significant subdomains of voice generation, leading to much demands on prompt-conditioned generation. Unlike common voice data, generating a singing voice requires an understanding of various associated vocal and musical characteristics, such as the vocal tone of the singer or emotional expressions. However, existing open-source audio-text datasets for voice generation tend to capture only a very limited range of attributes, often missing musical characteristics of the audio. To fill this gap, we introduce S2Cap, an audio-text pair dataset with a diverse set of attributes. S2Cap consists of pairs of textual prompts and music audio samples with a wide range of vocal and musical attributes, including pitch, volume, tempo, mood, singer's gender and age, and musical genre and emotional expression. Utilizing S2Cap, we suggest an effective novel baseline algorithm for singing style captioning. Singing style captioning is a relative task to voice generation that generates text descriptions of vocal characteristics, which we first suggested. First, to mitigate the misalignment between the audio encoder and the text decoder, we present a novel mechanism called CRESCENDO, which utilizes positive-pair similarity learning to synchronize the embedding spaces of a pretrained audio encoder to get similar embeddings with a text encoder. We additionally supervise the model using the singer's voice, which is demixed by the accompaniment. This supervision allows the model to more accurately capture vocal characteristics, leading to improved singing style captions that better reflect the style of the singer. The dataset and the codes are available at \bulurl{https://github.com/HJ-Ok/S2cap}.
AudioBERT: Audio Knowledge Augmented Language Model
Sep 12, 2024Recent studies have identified that language models, pretrained on text-only datasets, often lack elementary visual knowledge, \textit{e.g.,} colors of everyday objects. Motivated by this observation, we ask whether a similar shortcoming exists in terms of the \textit{auditory} knowledge. To answer this question, we construct a new dataset called AuditoryBench, which consists of two novel tasks for evaluating auditory knowledge. Based on our analysis using the benchmark, we find that language models also suffer from a severe lack of auditory knowledge. To address this limitation, we propose AudioBERT, a novel method to augment the auditory knowledge of BERT through a retrieval-based approach. First, we detect auditory knowledge spans in prompts to query our retrieval model efficiently. Then, we inject audio knowledge into BERT and switch on low-rank adaptation for effective adaptation when audio knowledge is required. Our experiments demonstrate that AudioBERT is quite effective, achieving superior performance on the AuditoryBench. The dataset and code are available at \bulurl{https://github.com/HJ-Ok/AudioBERT}.
Decoding with Limited Teacher Supervision Requires Understanding When to Trust the Teacher
Jun 26, 2024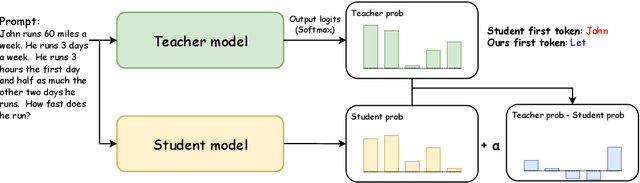
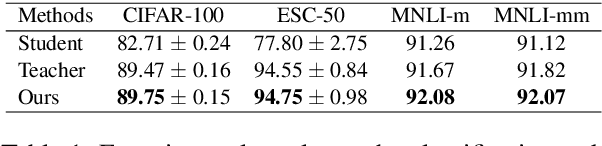
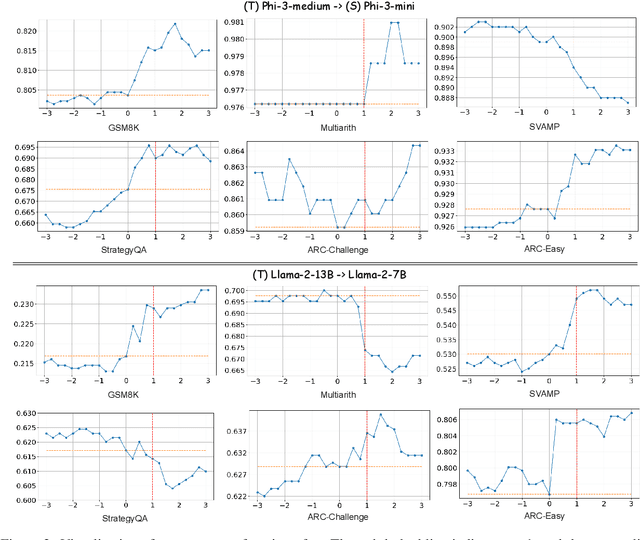
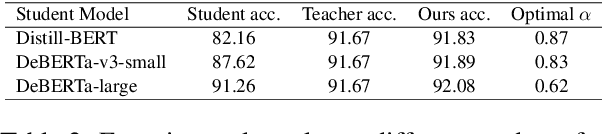
How can sLLMs efficiently utilize the supervision of LLMs to improve their generative quality? This question has been well studied in scenarios where there is no restriction on the number of LLM supervisions one can use, giving birth to many decoding algorithms that utilize supervision without further training. However, it is still unclear what is an effective strategy under the limited supervision scenario, where we assume that no more than a few tokens can be generated by LLMs. To this end, we develop an algorithm to effectively aggregate the sLLM and LLM predictions on initial tokens so that the generated tokens can more accurately condition the subsequent token generation by sLLM only. Critically, we find that it is essential to adaptively overtrust or disregard the LLM prediction based on the confidence of the sLLM. Through our experiments on a wide range of models and datasets, we demonstrate that our method provides a consistent improvement over conventional decoding strategies.
SCANNER: Knowledge-Enhanced Approach for Robust Multi-modal Named Entity Recognition of Unseen Entities
Apr 02, 2024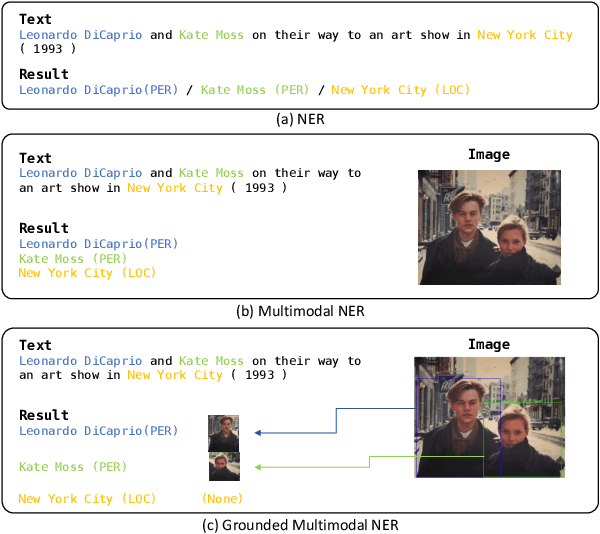

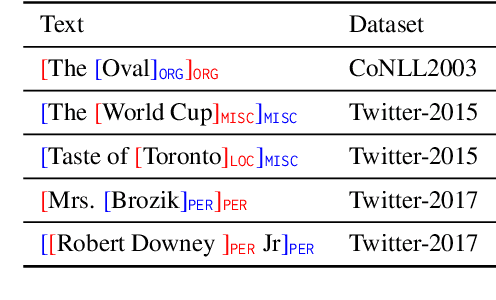
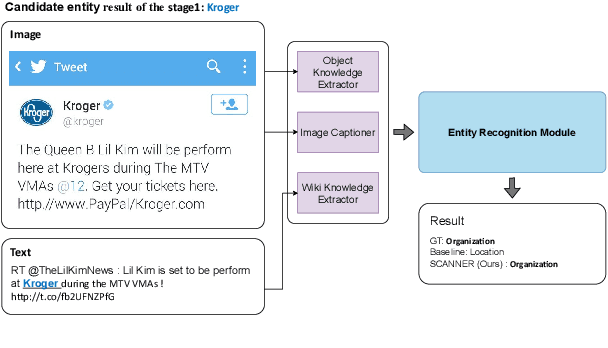
Recent advances in named entity recognition (NER) have pushed the boundary of the task to incorporate visual signals, leading to many variants, including multi-modal NER (MNER) or grounded MNER (GMNER). A key challenge to these tasks is that the model should be able to generalize to the entities unseen during the training, and should be able to handle the training samples with noisy annotations. To address this obstacle, we propose SCANNER (Span CANdidate detection and recognition for NER), a model capable of effectively handling all three NER variants. SCANNER is a two-stage structure; we extract entity candidates in the first stage and use it as a query to get knowledge, effectively pulling knowledge from various sources. We can boost our performance by utilizing this entity-centric extracted knowledge to address unseen entities. Furthermore, to tackle the challenges arising from noisy annotations in NER datasets, we introduce a novel self-distillation method, enhancing the robustness and accuracy of our model in processing training data with inherent uncertainties. Our approach demonstrates competitive performance on the NER benchmark and surpasses existing methods on both MNER and GMNER benchmarks. Further analysis shows that the proposed distillation and knowledge utilization methods improve the performance of our model on various benchmarks.
FinTree: Financial Dataset Pretrain Transformer Encoder for Relation Extraction
Jul 26, 2023We present FinTree, Financial Dataset Pretrain Transformer Encoder for Relation Extraction. Utilizing an encoder language model, we further pretrain FinTree on the financial dataset, adapting the model in financial domain tasks. FinTree stands out with its novel structure that predicts a masked token instead of the conventional [CLS] token, inspired by the Pattern Exploiting Training methodology. This structure allows for more accurate relation predictions between two given entities. The model is trained with a unique input pattern to provide contextual and positional information about the entities of interest, and a post-processing step ensures accurate predictions in line with the entity types. Our experiments demonstrate that FinTree outperforms on the REFinD, a large-scale financial relation extraction dataset. The code and pretrained models are available at https://github.com/HJ-Ok/FinTree.