 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrompt-based Depth Pruning of Large Language Models
Feb 04, 2025Depth pruning aims to reduce the inference cost of a large language model without any hardware-specific complications, by simply removing several less important transformer blocks. However, our empirical findings suggest that the importance of a transformer block may be highly task-dependent -- a block that is crucial for a task can be removed without degrading the accuracy on another task. Based on this observation, we develop a dynamic depth pruning algorithm, coined PuDDing (Prompt-routed Dynamic Depth Pruning), which determines which blocks to omit from the model based on the input prompt. PuDDing operates by training a lightweight router to predict the best omission set among a set of options, where this option set has also been constructed in a data-driven manner. Empirical results on commonsense reasoning benchmarks demonstrate that PuDDing effectively accelerates the inference language models, and achieves better on-task performance than static depth pruning baselines.
Heterogeneous Graph Neural Network for Personalized Session-Based Recommendation with User-Session Constraints
May 24, 2022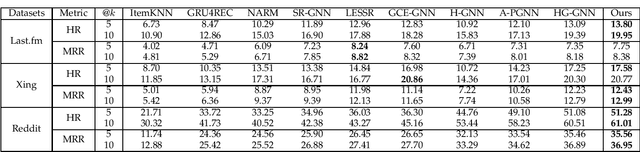
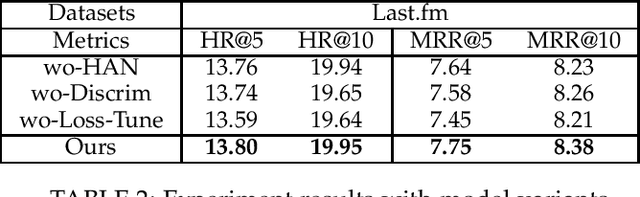
The recommendation system provides users with an appropriate limit of recent online large amounts of information. Session-based recommendation, a sub-area of recommender systems, attempts to recommend items by interpreting sessions that consist of sequences of items. Recently, research to include user information in these sessions is progress. However, it is difficult to generate high-quality user representation that includes session representations generated by user. In this paper, we consider various relationships in graph created by sessions through Heterogeneous attention network. Constraints also force user representations to consider the user's preferences presented in the session. It seeks to increase performance through additional optimization in the training process. The proposed model outperformed other methods on various real-world datasets.
Cross-view Self-Supervised Learning on Heterogeneous Graph Neural Network via Bootstrapping
Jan 11, 2022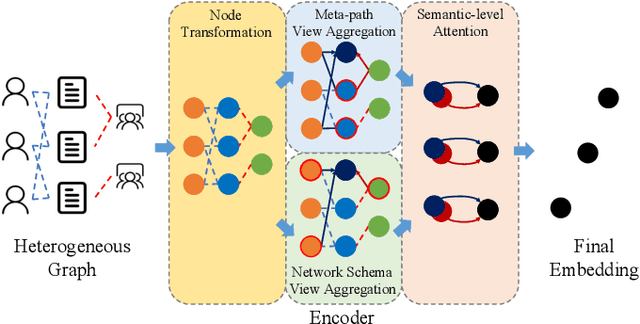
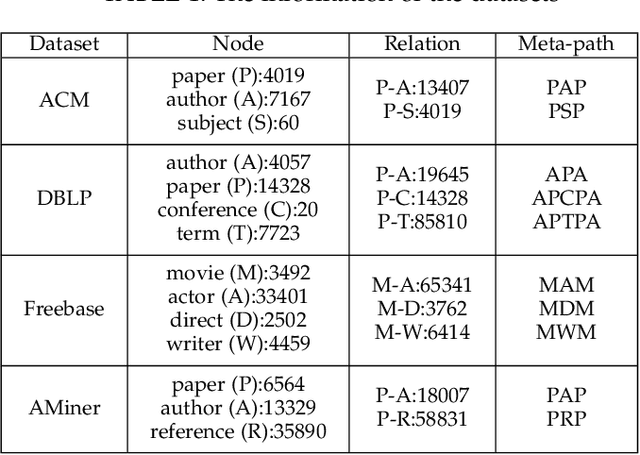
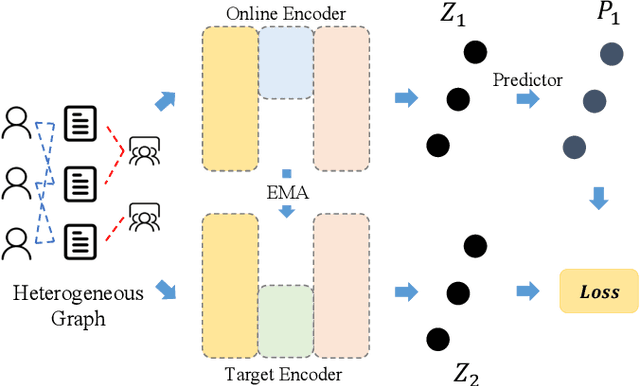
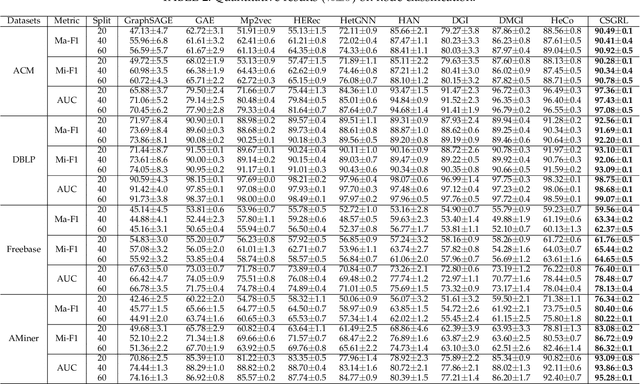
Heterogeneous graph neural networks can represent information of heterogeneous graphs with excellent ability. Recently, self-supervised learning manner is researched which learns the unique expression of a graph through a contrastive learning method. In the absence of labels, this learning methods show great potential. However, contrastive learning relies heavily on positive and negative pairs, and generating high-quality pairs from heterogeneous graphs is difficult. In this paper, in line with recent innovations in self-supervised learning called BYOL or bootstrapping, we introduce a that can generate good representations without generating large number of pairs. In addition, paying attention to the fact that heterogeneous graphs can be viewed from two perspectives, network schema and meta-path views, high-level expressions in the graphs are captured and expressed. The proposed model showed state-of-the-art performance than other methods in various real world datasets.