 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBreaking the Spurious Causality of Conditional Generation via Fairness Intervention with Corrective Sampling
Dec 05, 2022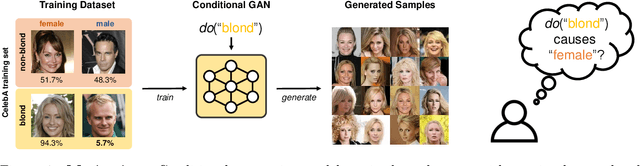



Trying to capture the sample-label relationship, conditional generative models often end up inheriting the spurious correlation in the training dataset, giving label-conditional distributions that are severely imbalanced in another latent attribute. To mitigate such undesirable correlations engraved into generative models, which we call spurious causality, we propose a general two-step strategy. (a) Fairness Intervention (FI): Emphasize the minority samples that are hard to be generated due to the spurious correlation in the training dataset. (b) Corrective Sampling (CS): Filter the generated samples explicitly to follow the desired label-conditional latent attribute distribution. We design the fairness intervention for various degrees of supervision on the spurious attribute, including unsupervised, weakly-supervised, and semi-supervised scenarios. Our experimental results show that the proposed FICS can successfully resolve the spurious correlation in generated samples on various datasets.
Spread Spurious Attribute: Improving Worst-group Accuracy with Spurious Attribute Estimation
Apr 05, 2022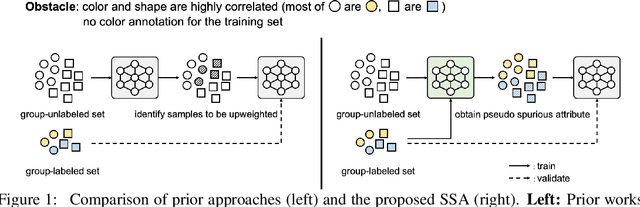
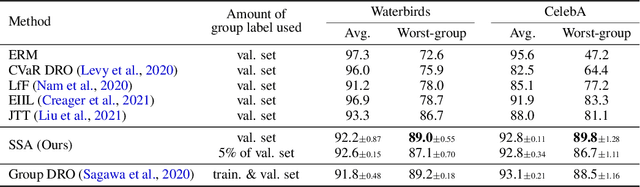
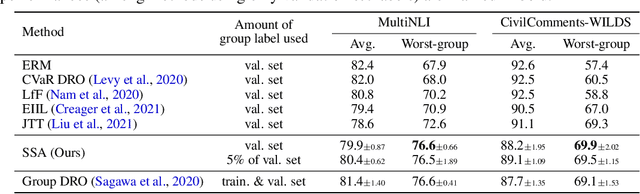

The paradigm of worst-group loss minimization has shown its promise in avoiding to learn spurious correlations, but requires costly additional supervision on spurious attributes. To resolve this, recent works focus on developing weaker forms of supervision -- e.g., hyperparameters discovered with a small number of validation samples with spurious attribute annotation -- but none of the methods retain comparable performance to methods using full supervision on the spurious attribute. In this paper, instead of searching for weaker supervisions, we ask: Given access to a fixed number of samples with spurious attribute annotations, what is the best achievable worst-group loss if we "fully exploit" them? To this end, we propose a pseudo-attribute-based algorithm, coined Spread Spurious Attribute (SSA), for improving the worst-group accuracy. In particular, we leverage samples both with and without spurious attribute annotations to train a model to predict the spurious attribute, then use the pseudo-attribute predicted by the trained model as supervision on the spurious attribute to train a new robust model having minimal worst-group loss. Our experiments on various benchmark datasets show that our algorithm consistently outperforms the baseline methods using the same number of validation samples with spurious attribute annotations. We also demonstrate that the proposed SSA can achieve comparable performances to methods using full (100%) spurious attribute supervision, by using a much smaller number of annotated samples -- from 0.6% and up to 1.5%, depending on the dataset.
Learning from Failure: Training Debiased Classifier from Biased Classifier
Jul 06, 2020
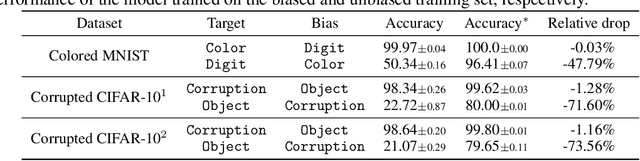

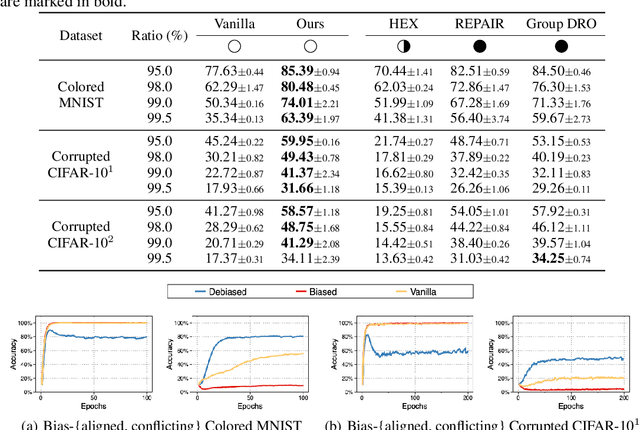
Neural networks often learn to make predictions that overly rely on spurious correlation existing in the dataset, which causes the model to be biased. While previous work tackles this issue with domain-specific knowledge or explicit supervision on the spuriously correlated attributes, we instead tackle a more challenging setting where such information is unavailable. To this end, we first observe that neural networks learn to rely on the spurious correlation only when it is ''easier'' to learn than the desired knowledge, and such reliance is most prominent during the early phase of training. Based on the observations, we propose a failure-based debiasing scheme by training a pair of neural networks simultaneously. Our main idea is twofold; (a) we intentionally train the first network to be biased by repeatedly amplifying its ''prejudice'', and (b) we debias the training of the second network by focusing on samples that go against the prejudice of the biased network in (a). Extensive experiments demonstrate that our method significantly improves the training of network against various types of biases in both synthetic and real-world datasets. Surprisingly, our framework even occasionally outperforms the debiasing methods requiring explicit supervision of the spuriously correlated attributes.