 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCo$^2$L: Contrastive Continual Learning
Jun 28, 2021



Recent breakthroughs in self-supervised learning show that such algorithms learn visual representations that can be transferred better to unseen tasks than joint-training methods relying on task-specific supervision. In this paper, we found that the similar holds in the continual learning con-text: contrastively learned representations are more robust against the catastrophic forgetting than jointly trained representations. Based on this novel observation, we propose a rehearsal-based continual learning algorithm that focuses on continually learning and maintaining transferable representations. More specifically, the proposed scheme (1) learns representations using the contrastive learning objective, and (2) preserves learned representations using a self-supervised distillation step. We conduct extensive experimental validations under popular benchmark image classification datasets, where our method sets the new state-of-the-art performance.
Learning from Failure: Training Debiased Classifier from Biased Classifier
Jul 06, 2020
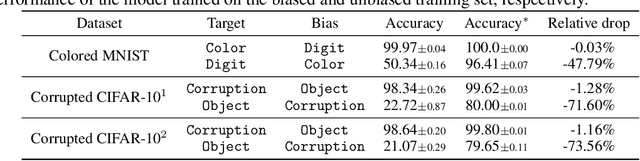

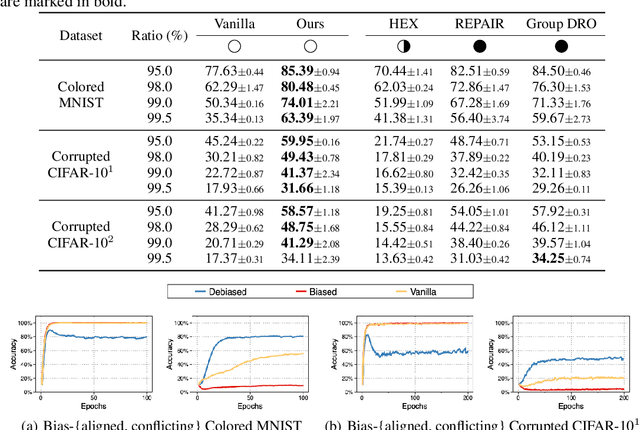
Neural networks often learn to make predictions that overly rely on spurious correlation existing in the dataset, which causes the model to be biased. While previous work tackles this issue with domain-specific knowledge or explicit supervision on the spuriously correlated attributes, we instead tackle a more challenging setting where such information is unavailable. To this end, we first observe that neural networks learn to rely on the spurious correlation only when it is ''easier'' to learn than the desired knowledge, and such reliance is most prominent during the early phase of training. Based on the observations, we propose a failure-based debiasing scheme by training a pair of neural networks simultaneously. Our main idea is twofold; (a) we intentionally train the first network to be biased by repeatedly amplifying its ''prejudice'', and (b) we debias the training of the second network by focusing on samples that go against the prejudice of the biased network in (a). Extensive experiments demonstrate that our method significantly improves the training of network against various types of biases in both synthetic and real-world datasets. Surprisingly, our framework even occasionally outperforms the debiasing methods requiring explicit supervision of the spuriously correlated attributes.