 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWriting in The Air: Unconstrained Text Recognition from Finger Movement Using Spatio-Temporal Convolution
Paper and Code

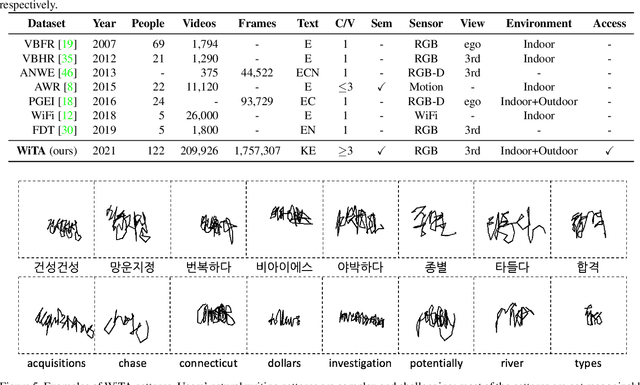

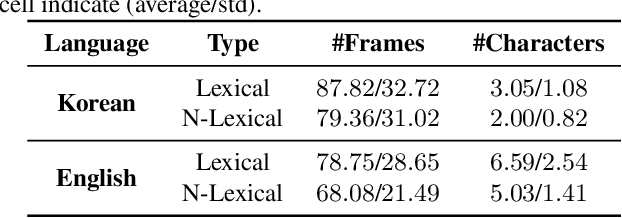
In this paper, we introduce a new benchmark dataset for the challenging writing in the air (WiTA) task -- an elaborate task bridging vision and NLP. WiTA implements an intuitive and natural writing method with finger movement for human-computer interaction (HCI). Our WiTA dataset will facilitate the development of data-driven WiTA systems which thus far have displayed unsatisfactory performance -- due to lack of dataset as well as traditional statistical models they have adopted. Our dataset consists of five sub-datasets in two languages (Korean and English) and amounts to 209,926 video instances from 122 participants. We capture finger movement for WiTA with RGB cameras to ensure wide accessibility and cost-efficiency. Next, we propose spatio-temporal residual network architectures inspired by 3D ResNet. These models perform unconstrained text recognition from finger movement, guarantee a real-time operation by processing 435 and 697 decoding frames-per-second for Korean and English, respectively, and will serve as an evaluation standard. Our dataset and the source codes are available at https://github.com/Uehwan/WiTA.