 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoccerNet 2025 Challenges Results
Aug 26, 2025The SoccerNet 2025 Challenges mark the fifth annual edition of the SoccerNet open benchmarking effort, dedicated to advancing computer vision research in football video understanding. This year's challenges span four vision-based tasks: (1) Team Ball Action Spotting, focused on detecting ball-related actions in football broadcasts and assigning actions to teams; (2) Monocular Depth Estimation, targeting the recovery of scene geometry from single-camera broadcast clips through relative depth estimation for each pixel; (3) Multi-View Foul Recognition, requiring the analysis of multiple synchronized camera views to classify fouls and their severity; and (4) Game State Reconstruction, aimed at localizing and identifying all players from a broadcast video to reconstruct the game state on a 2D top-view of the field. Across all tasks, participants were provided with large-scale annotated datasets, unified evaluation protocols, and strong baselines as starting points. This report presents the results of each challenge, highlights the top-performing solutions, and provides insights into the progress made by the community. The SoccerNet Challenges continue to serve as a driving force for reproducible, open research at the intersection of computer vision, artificial intelligence, and sports. Detailed information about the tasks, challenges, and leaderboards can be found at https://www.soccer-net.org, with baselines and development kits available at https://github.com/SoccerNet.
TWICE: What Advantages Can Low-Resource Domain-Specific Embedding Model Bring? - A Case Study on Korea Financial Texts
Feb 10, 2025
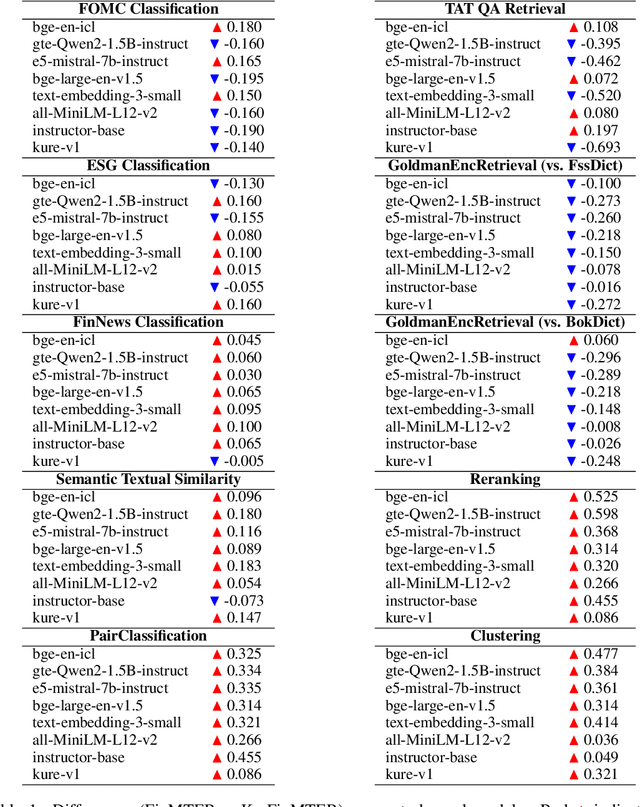

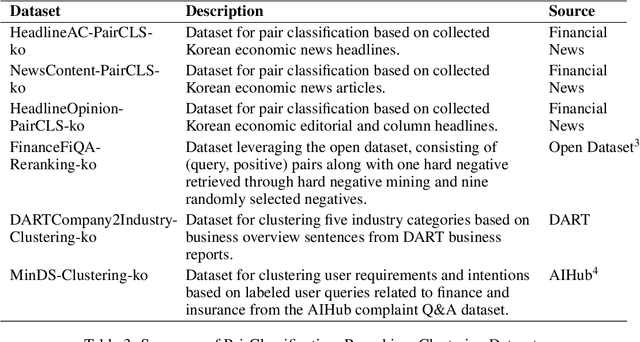
Domain specificity of embedding models is critical for effective performance. However, existing benchmarks, such as FinMTEB, are primarily designed for high-resource languages, leaving low-resource settings, such as Korean, under-explored. Directly translating established English benchmarks often fails to capture the linguistic and cultural nuances present in low-resource domains. In this paper, titled TWICE: What Advantages Can Low-Resource Domain-Specific Embedding Models Bring? A Case Study on Korea Financial Texts, we introduce KorFinMTEB, a novel benchmark for the Korean financial domain, specifically tailored to reflect its unique cultural characteristics in low-resource languages. Our experimental results reveal that while the models perform robustly on a translated version of FinMTEB, their performance on KorFinMTEB uncovers subtle yet critical discrepancies, especially in tasks requiring deeper semantic understanding, that underscore the limitations of direct translation. This discrepancy highlights the necessity of benchmarks that incorporate language-specific idiosyncrasies and cultural nuances. The insights from our study advocate for the development of domain-specific evaluation frameworks that can more accurately assess and drive the progress of embedding models in low-resource settings.
Deep Q-Network for AI Soccer
Sep 21, 2022


Reinforcement learning has shown an outstanding performance in the applications of games, particularly in Atari games as well as Go. Based on these successful examples, we attempt to apply one of the well-known reinforcement learning algorithms, Deep Q-Network, to the AI Soccer game. AI Soccer is a 5:5 robot soccer game where each participant develops an algorithm that controls five robots in a team to defeat the opponent participant. Deep Q-Network is designed to implement our original rewards, the state space, and the action space to train each agent so that it can take proper actions in different situations during the game. Our algorithm was able to successfully train the agents, and its performance was preliminarily proven through the mini-competition against 10 teams wishing to take part in the AI Soccer international competition. The competition was organized by the AI World Cup committee, in conjunction with the WCG 2019 Xi'an AI Masters. With our algorithm, we got the achievement of advancing to the round of 16 in this international competition with 130 teams from 39 countries.
Writing in The Air: Unconstrained Text Recognition from Finger Movement Using Spatio-Temporal Convolution
Apr 19, 2021
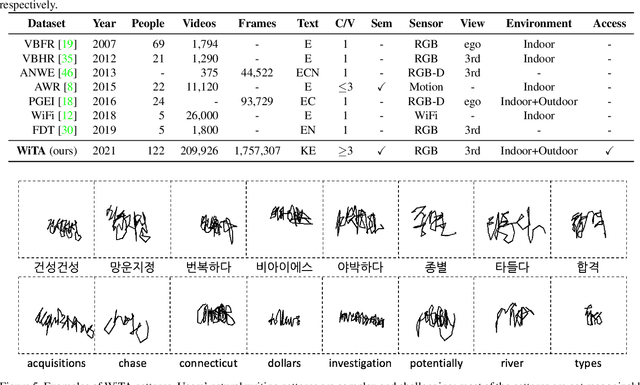

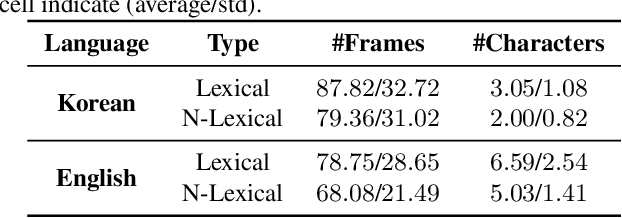
In this paper, we introduce a new benchmark dataset for the challenging writing in the air (WiTA) task -- an elaborate task bridging vision and NLP. WiTA implements an intuitive and natural writing method with finger movement for human-computer interaction (HCI). Our WiTA dataset will facilitate the development of data-driven WiTA systems which thus far have displayed unsatisfactory performance -- due to lack of dataset as well as traditional statistical models they have adopted. Our dataset consists of five sub-datasets in two languages (Korean and English) and amounts to 209,926 video instances from 122 participants. We capture finger movement for WiTA with RGB cameras to ensure wide accessibility and cost-efficiency. Next, we propose spatio-temporal residual network architectures inspired by 3D ResNet. These models perform unconstrained text recognition from finger movement, guarantee a real-time operation by processing 435 and 697 decoding frames-per-second for Korean and English, respectively, and will serve as an evaluation standard. Our dataset and the source codes are available at https://github.com/Uehwan/WiTA.