 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Q-Network for AI Soccer
Sep 21, 2022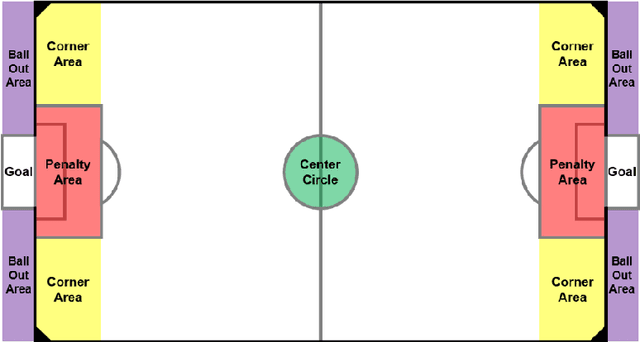


Reinforcement learning has shown an outstanding performance in the applications of games, particularly in Atari games as well as Go. Based on these successful examples, we attempt to apply one of the well-known reinforcement learning algorithms, Deep Q-Network, to the AI Soccer game. AI Soccer is a 5:5 robot soccer game where each participant develops an algorithm that controls five robots in a team to defeat the opponent participant. Deep Q-Network is designed to implement our original rewards, the state space, and the action space to train each agent so that it can take proper actions in different situations during the game. Our algorithm was able to successfully train the agents, and its performance was preliminarily proven through the mini-competition against 10 teams wishing to take part in the AI Soccer international competition. The competition was organized by the AI World Cup committee, in conjunction with the WCG 2019 Xi'an AI Masters. With our algorithm, we got the achievement of advancing to the round of 16 in this international competition with 130 teams from 39 countries.
Self-supervised 3D Object Detection from Monocular Pseudo-LiDAR
Sep 20, 2022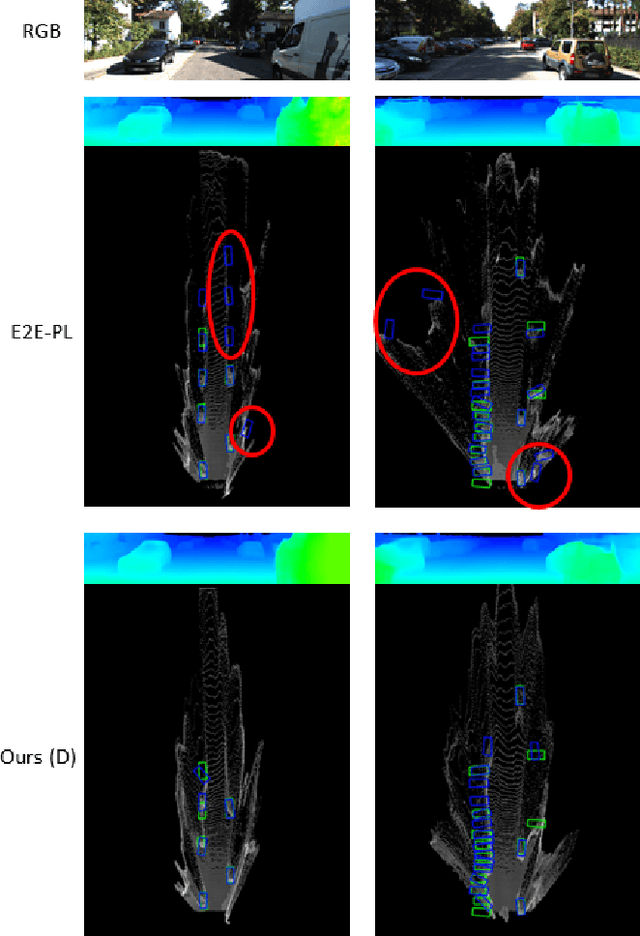


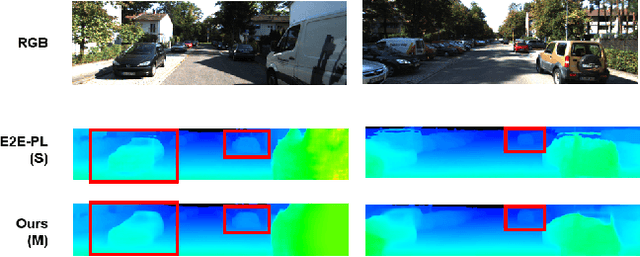
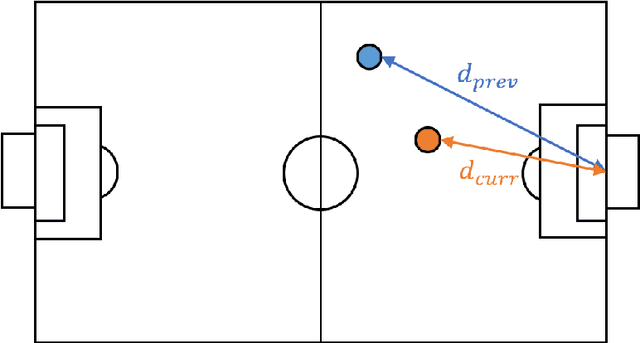
There have been attempts to detect 3D objects by fusion of stereo camera images and LiDAR sensor data or using LiDAR for pre-training and only monocular images for testing, but there have been less attempts to use only monocular image sequences due to low accuracy. In addition, when depth prediction using only monocular images, only scale-inconsistent depth can be predicted, which is the reason why researchers are reluctant to use monocular images alone. Therefore, we propose a method for predicting absolute depth and detecting 3D objects using only monocular image sequences by enabling end-to-end learning of detection networks and depth prediction networks. As a result, the proposed method surpasses other existing methods in performance on the KITTI 3D dataset. Even when monocular image and 3D LiDAR are used together during training in an attempt to improve performance, ours exhibit is the best performance compared to other methods using the same input. In addition, end-to-end learning not only improves depth prediction performance, but also enables absolute depth prediction, because our network utilizes the fact that the size of a 3D object such as a car is determined by the approximate size.
A Dual-Cycled Cross-View Transformer Network for Unified Road Layout Estimation and 3D Object Detection in the Bird's-Eye-View
Sep 19, 2022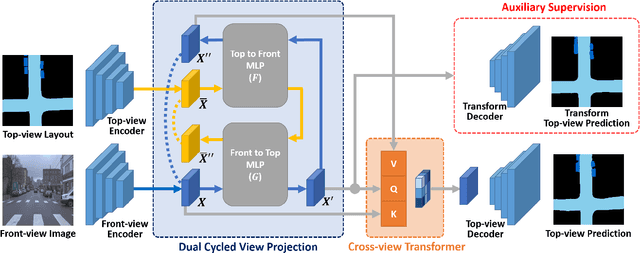


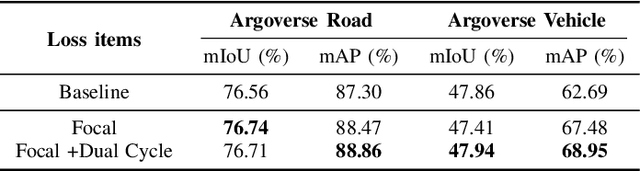
The bird's-eye-view (BEV) representation allows robust learning of multiple tasks for autonomous driving including road layout estimation and 3D object detection. However, contemporary methods for unified road layout estimation and 3D object detection rarely handle the class imbalance of the training dataset and multi-class learning to reduce the total number of networks required. To overcome these limitations, we propose a unified model for road layout estimation and 3D object detection inspired by the transformer architecture and the CycleGAN learning framework. The proposed model deals with the performance degradation due to the class imbalance of the dataset utilizing the focal loss and the proposed dual cycle loss. Moreover, we set up extensive learning scenarios to study the effect of multi-class learning for road layout estimation in various situations. To verify the effectiveness of the proposed model and the learning scheme, we conduct a thorough ablation study and a comparative study. The experiment results attest the effectiveness of our model; we achieve state-of-the-art performance in both the road layout estimation and 3D object detection tasks.