 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-supervised 3D Object Detection from Monocular Pseudo-LiDAR
Paper and Code
Sep 20, 2022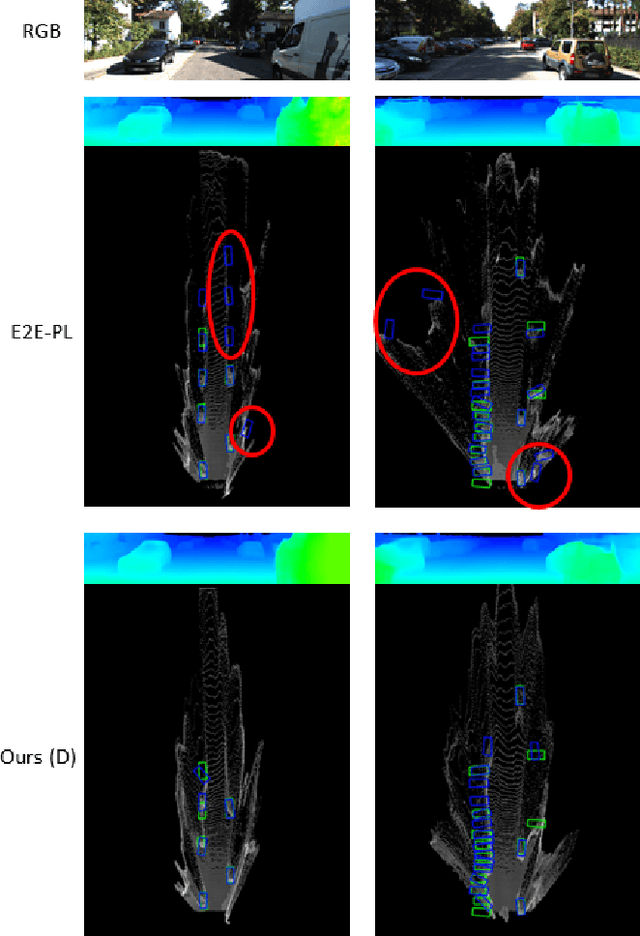


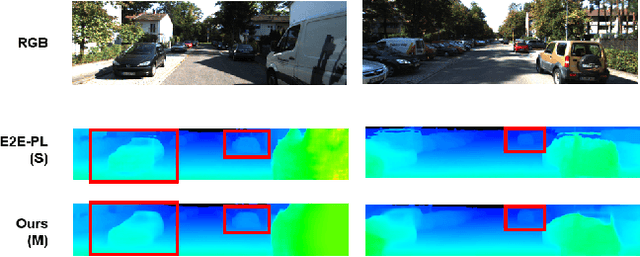
There have been attempts to detect 3D objects by fusion of stereo camera images and LiDAR sensor data or using LiDAR for pre-training and only monocular images for testing, but there have been less attempts to use only monocular image sequences due to low accuracy. In addition, when depth prediction using only monocular images, only scale-inconsistent depth can be predicted, which is the reason why researchers are reluctant to use monocular images alone. Therefore, we propose a method for predicting absolute depth and detecting 3D objects using only monocular image sequences by enabling end-to-end learning of detection networks and depth prediction networks. As a result, the proposed method surpasses other existing methods in performance on the KITTI 3D dataset. Even when monocular image and 3D LiDAR are used together during training in an attempt to improve performance, ours exhibit is the best performance compared to other methods using the same input. In addition, end-to-end learning not only improves depth prediction performance, but also enables absolute depth prediction, because our network utilizes the fact that the size of a 3D object such as a car is determined by the approximate size.