 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTWICE: What Advantages Can Low-Resource Domain-Specific Embedding Model Bring? - A Case Study on Korea Financial Texts
Feb 10, 2025Domain specificity of embedding models is critical for effective performance. However, existing benchmarks, such as FinMTEB, are primarily designed for high-resource languages, leaving low-resource settings, such as Korean, under-explored. Directly translating established English benchmarks often fails to capture the linguistic and cultural nuances present in low-resource domains. In this paper, titled TWICE: What Advantages Can Low-Resource Domain-Specific Embedding Models Bring? A Case Study on Korea Financial Texts, we introduce KorFinMTEB, a novel benchmark for the Korean financial domain, specifically tailored to reflect its unique cultural characteristics in low-resource languages. Our experimental results reveal that while the models perform robustly on a translated version of FinMTEB, their performance on KorFinMTEB uncovers subtle yet critical discrepancies, especially in tasks requiring deeper semantic understanding, that underscore the limitations of direct translation. This discrepancy highlights the necessity of benchmarks that incorporate language-specific idiosyncrasies and cultural nuances. The insights from our study advocate for the development of domain-specific evaluation frameworks that can more accurately assess and drive the progress of embedding models in low-resource settings.
EaSyGuide : ESG Issue Identification Framework leveraging Abilities of Generative Large Language Models
Jun 13, 2023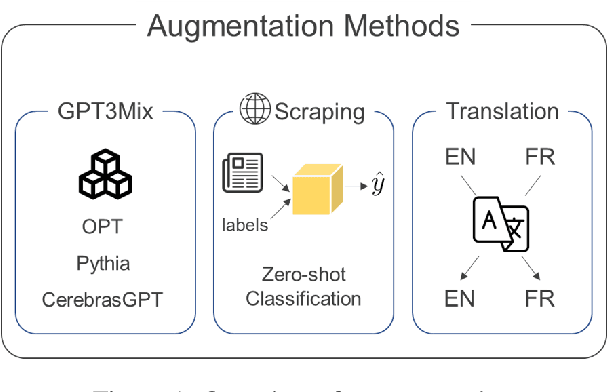


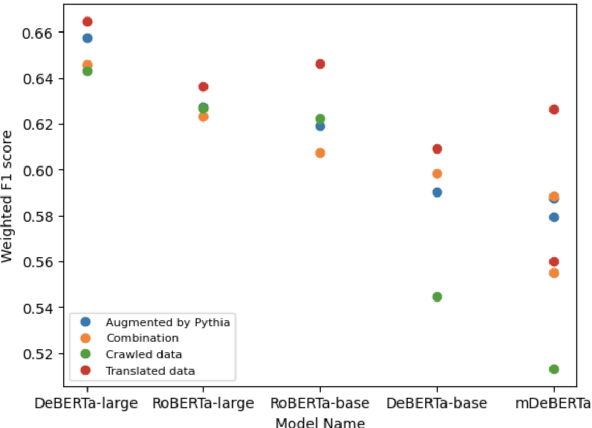
This paper presents our participation in the FinNLP-2023 shared task on multi-lingual environmental, social, and corporate governance issue identification (ML-ESG). The task's objective is to classify news articles based on the 35 ESG key issues defined by the MSCI ESG rating guidelines. Our approach focuses on the English and French subtasks, employing the CerebrasGPT, OPT, and Pythia models, along with the zero-shot and GPT3Mix Augmentation techniques. We utilize various encoder models, such as RoBERTa, DeBERTa, and FinBERT, subjecting them to knowledge distillation and additional training. Our approach yielded exceptional results, securing the first position in the English text subtask with F1-score 0.69 and the second position in the French text subtask with F1-score 0.78. These outcomes underscore the effectiveness of our methodology in identifying ESG issues in news articles across different languages. Our findings contribute to the exploration of ESG topics and highlight the potential of leveraging advanced language models for ESG issue identification.