 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLFS-GAN: Lifelong Few-Shot Image Generation
Sep 05, 2023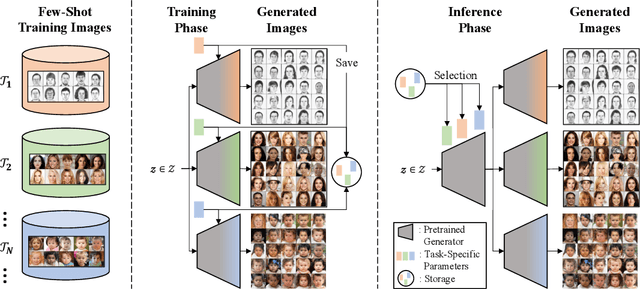

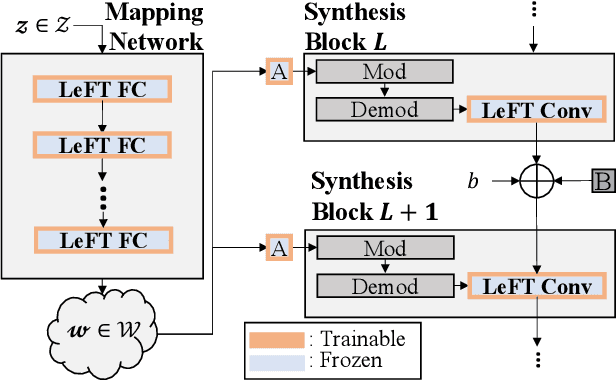

We address a challenging lifelong few-shot image generation task for the first time. In this situation, a generative model learns a sequence of tasks using only a few samples per task. Consequently, the learned model encounters both catastrophic forgetting and overfitting problems at a time. Existing studies on lifelong GANs have proposed modulation-based methods to prevent catastrophic forgetting. However, they require considerable additional parameters and cannot generate high-fidelity and diverse images from limited data. On the other hand, the existing few-shot GANs suffer from severe catastrophic forgetting when learning multiple tasks. To alleviate these issues, we propose a framework called Lifelong Few-Shot GAN (LFS-GAN) that can generate high-quality and diverse images in lifelong few-shot image generation task. Our proposed framework learns each task using an efficient task-specific modulator - Learnable Factorized Tensor (LeFT). LeFT is rank-constrained and has a rich representation ability due to its unique reconstruction technique. Furthermore, we propose a novel mode seeking loss to improve the diversity of our model in low-data circumstances. Extensive experiments demonstrate that the proposed LFS-GAN can generate high-fidelity and diverse images without any forgetting and mode collapse in various domains, achieving state-of-the-art in lifelong few-shot image generation task. Surprisingly, we find that our LFS-GAN even outperforms the existing few-shot GANs in the few-shot image generation task. The code is available at Github.
RDIS: Random Drop Imputation with Self-Training for Incomplete Time Series Data
Oct 20, 2020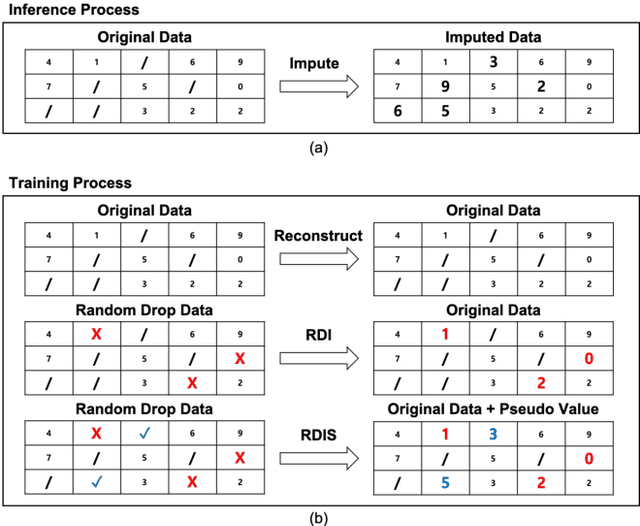
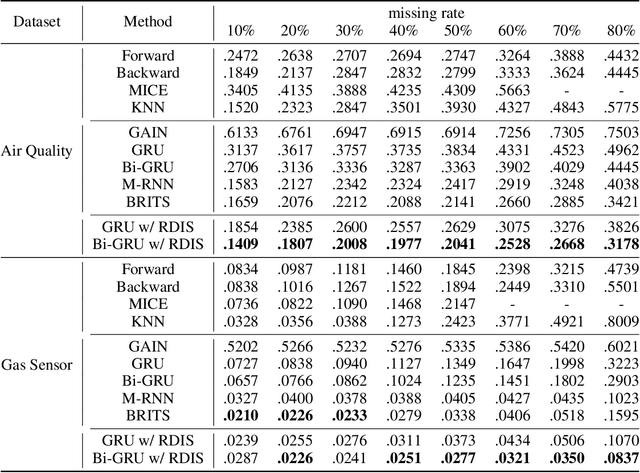
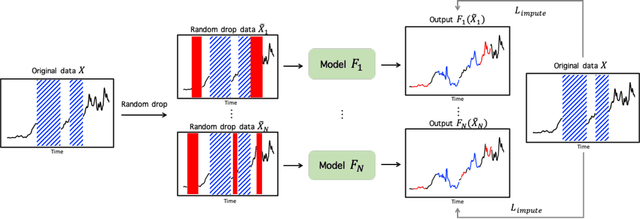

It is common that time-series data with missing values are encountered in many fields such as in finance, meteorology, and robotics. Imputation is an intrinsic method to handle such missing values. In the previous research, most of imputation networks were trained implicitly for the incomplete time series data because missing values have no ground truth. This paper proposes Random Drop Imputation with Self-training (RDIS), a novel training method for imputation networks for the incomplete time-series data. In RDIS, there are extra missing values by applying a random drop on the given incomplete data such that the imputation network can explicitly learn by imputing the random drop values. Also, self-training is introduced to exploit the original missing values without ground truth. To verify the effectiveness of our RDIS on imputation tasks, we graft RDIS to a bidirectional GRU and achieve state-of-the-art results on two real-world datasets, an air quality dataset and a gas sensor dataset with 7.9% and 5.8% margin, respectively.