 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Syn-to-Real Domain Adaptation for Military Target Detection
Dec 29, 2025Object detection is one of the key target tasks of interest in the context of civil and military applications. In particular, the real-world deployment of target detection methods is pivotal in the decision-making process during military command and reconnaissance. However, current domain adaptive object detection algorithms consider adapting one domain to another similar one only within the scope of natural or autonomous driving scenes. Since military domains often deal with a mixed variety of environments, detecting objects from multiple varying target domains poses a greater challenge. Several studies for armored military target detection have made use of synthetic aperture radar (SAR) data due to its robustness to all weather, long range, and high-resolution characteristics. Nevertheless, the costs of SAR data acquisition and processing are still much higher than those of the conventional RGB camera, which is a more affordable alternative with significantly lower data processing time. Furthermore, the lack of military target detection datasets limits the use of such a low-cost approach. To mitigate these issues, we propose to generate RGB-based synthetic data using a photorealistic visual tool, Unreal Engine, for military target detection in a cross-domain setting. To this end, we conducted synthetic-to-real transfer experiments by training our synthetic dataset and validating on our web-collected real military target datasets. We benchmark the state-of-the-art domain adaptation methods distinguished by the degree of supervision on our proposed train-val dataset pair, and find that current methods using minimal hints on the image (e.g., object class) achieve a substantial improvement over unsupervised or semi-supervised DA methods. From these observations, we recognize the current challenges that remain to be overcome.
Task-oriented Learnable Diffusion Timesteps for Universal Few-shot Learning of Dense Tasks
Dec 29, 2025Denoising diffusion probabilistic models have brought tremendous advances in generative tasks, achieving state-of-the-art performance thus far. Current diffusion model-based applications exploit the power of learned visual representations from multistep forward-backward Markovian processes for single-task prediction tasks by attaching a task-specific decoder. However, the heuristic selection of diffusion timestep features still heavily relies on empirical intuition, often leading to sub-optimal performance biased towards certain tasks. To alleviate this constraint, we investigate the significance of versatile diffusion timestep features by adaptively selecting timesteps best suited for the few-shot dense prediction task, evaluated on an arbitrary unseen task. To this end, we propose two modules: Task-aware Timestep Selection (TTS) to select ideal diffusion timesteps based on timestep-wise losses and similarity scores, and Timestep Feature Consolidation (TFC) to consolidate the selected timestep features to improve the dense predictive performance in a few-shot setting. Accompanied by our parameter-efficient fine-tuning adapter, our framework effectively achieves superiority in dense prediction performance given only a few support queries. We empirically validate our learnable timestep consolidation method on the large-scale challenging Taskonomy dataset for dense prediction, particularly for practical universal and few-shot learning scenarios.
AVOID: The Adverse Visual Conditions Dataset with Obstacles for Driving Scene Understanding
Dec 29, 2025Understanding road scenes for visual perception remains crucial for intelligent self-driving cars. In particular, it is desirable to detect unexpected small road hazards reliably in real-time, especially under varying adverse conditions (e.g., weather and daylight). However, existing road driving datasets provide large-scale images acquired in either normal or adverse scenarios only, and often do not contain the road obstacles captured in the same visual domain as for the other classes. To address this, we introduce a new dataset called AVOID, the Adverse Visual Conditions Dataset, for real-time obstacle detection collected in a simulated environment. AVOID consists of a large set of unexpected road obstacles located along each path captured under various weather and time conditions. Each image is coupled with the corresponding semantic and depth maps, raw and semantic LiDAR data, and waypoints, thereby supporting most visual perception tasks. We benchmark the results on high-performing real-time networks for the obstacle detection task, and also propose and conduct ablation studies using a comprehensive multi-task network for semantic segmentation, depth and waypoint prediction tasks.
FACL-Attack: Frequency-Aware Contrastive Learning for Transferable Adversarial Attacks
Jul 30, 2024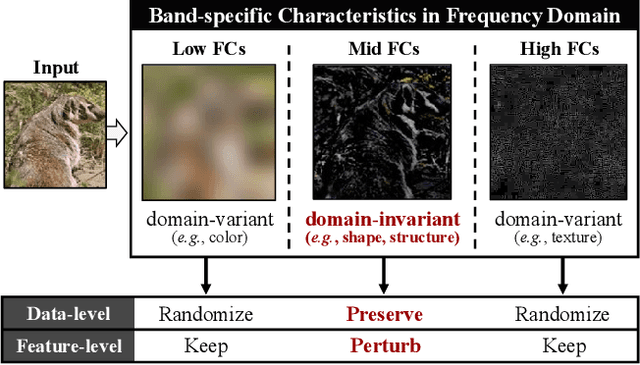



Deep neural networks are known to be vulnerable to security risks due to the inherent transferable nature of adversarial examples. Despite the success of recent generative model-based attacks demonstrating strong transferability, it still remains a challenge to design an efficient attack strategy in a real-world strict black-box setting, where both the target domain and model architectures are unknown. In this paper, we seek to explore a feature contrastive approach in the frequency domain to generate adversarial examples that are robust in both cross-domain and cross-model settings. With that goal in mind, we propose two modules that are only employed during the training phase: a Frequency-Aware Domain Randomization (FADR) module to randomize domain-variant low- and high-range frequency components and a Frequency-Augmented Contrastive Learning (FACL) module to effectively separate domain-invariant mid-frequency features of clean and perturbed image. We demonstrate strong transferability of our generated adversarial perturbations through extensive cross-domain and cross-model experiments, while keeping the inference time complexity.
Prompt-Driven Contrastive Learning for Transferable Adversarial Attacks
Jul 30, 2024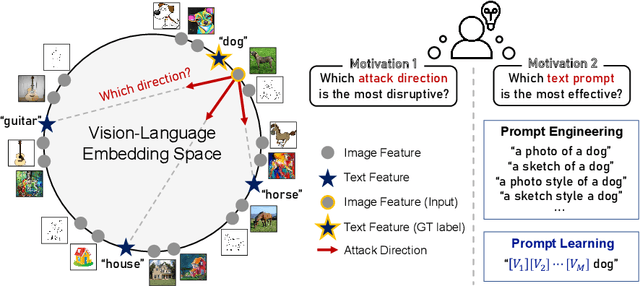

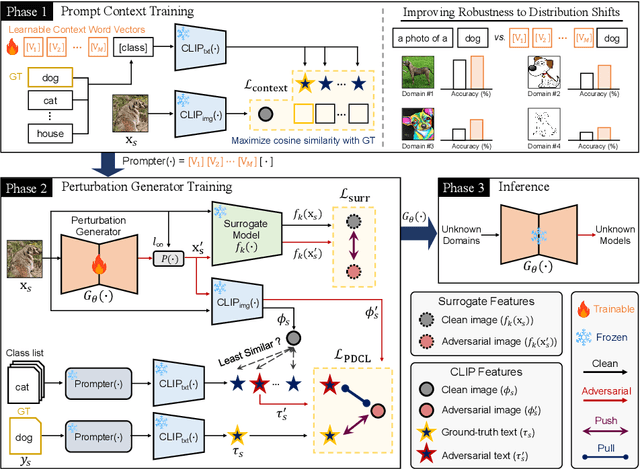

Recent vision-language foundation models, such as CLIP, have demonstrated superior capabilities in learning representations that can be transferable across diverse range of downstream tasks and domains. With the emergence of such powerful models, it has become crucial to effectively leverage their capabilities in tackling challenging vision tasks. On the other hand, only a few works have focused on devising adversarial examples that transfer well to both unknown domains and model architectures. In this paper, we propose a novel transfer attack method called PDCL-Attack, which leverages the CLIP model to enhance the transferability of adversarial perturbations generated by a generative model-based attack framework. Specifically, we formulate an effective prompt-driven feature guidance by harnessing the semantic representation power of text, particularly from the ground-truth class labels of input images. To the best of our knowledge, we are the first to introduce prompt learning to enhance the transferable generative attacks. Extensive experiments conducted across various cross-domain and cross-model settings empirically validate our approach, demonstrating its superiority over state-of-the-art methods.
Semantics-guided Transformer-based Sensor Fusion for Improved Waypoint Prediction
Aug 04, 2023Sensor fusion approaches for intelligent self-driving agents remain key to driving scene understanding given visual global contexts acquired from input sensors. Specifically, for the local waypoint prediction task, single-modality networks are still limited by strong dependency on the sensitivity of the input sensor, and thus recent works promote the use of multiple sensors in fusion in feature level. While it is well known that multiple data modalities promote mutual contextual exchange, deployment to practical driving scenarios requires global 3D scene understanding in real-time with minimal computations, thus placing greater significance on training strategies given a limited number of practically usable sensors. In this light, we exploit carefully selected auxiliary tasks that are highly correlated with the target task of interest (e.g., traffic light recognition and semantic segmentation) by fusing auxiliary task features and also using auxiliary heads for waypoint prediction based on imitation learning. Our multi-task feature fusion augments and improves the base network, TransFuser, by significant margins for safer and more complete road navigation in CARLA simulator as validated on the Town05 Benchmark through extensive experiments.
Doubly Contrastive End-to-End Semantic Segmentation for Autonomous Driving under Adverse Weather
Nov 21, 2022Road scene understanding tasks have recently become crucial for self-driving vehicles. In particular, real-time semantic segmentation is indispensable for intelligent self-driving agents to recognize roadside objects in the driving area. As prior research works have primarily sought to improve the segmentation performance with computationally heavy operations, they require far significant hardware resources for both training and deployment, and thus are not suitable for real-time applications. As such, we propose a doubly contrastive approach to improve the performance of a more practical lightweight model for self-driving, specifically under adverse weather conditions such as fog, nighttime, rain and snow. Our proposed approach exploits both image- and pixel-level contrasts in an end-to-end supervised learning scheme without requiring a memory bank for global consistency or the pretraining step used in conventional contrastive methods. We validate the effectiveness of our method using SwiftNet on the ACDC dataset, where it achieves up to 1.34%p improvement in mIoU (ResNet-18 backbone) at 66.7 FPS (2048x1024 resolution) on a single RTX 3080 Mobile GPU at inference. Furthermore, we demonstrate that replacing image-level supervision with self-supervision achieves comparable performance when pre-trained with clear weather images.