 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVision based Pedestrian Potential Risk Analysis based on Automated Behavior Feature Extraction for Smart and Safe City
May 27, 2021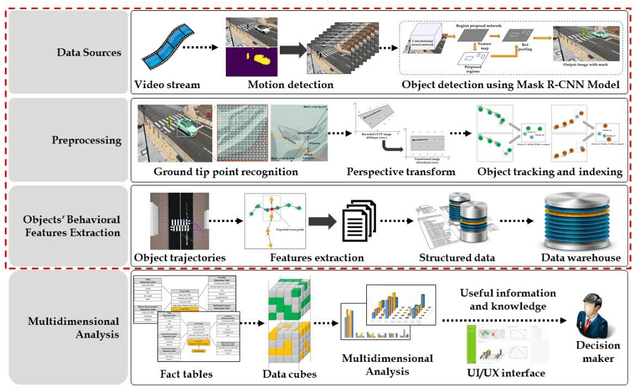
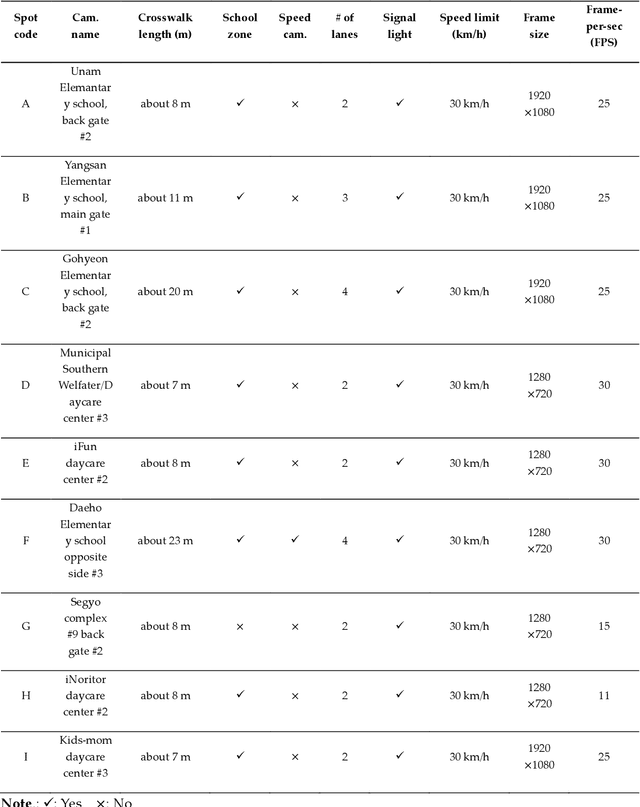

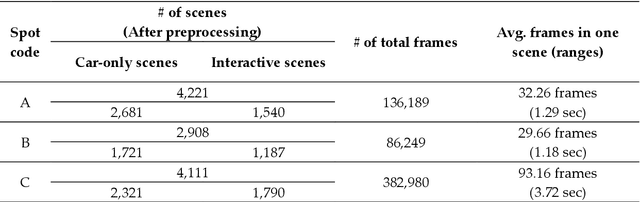
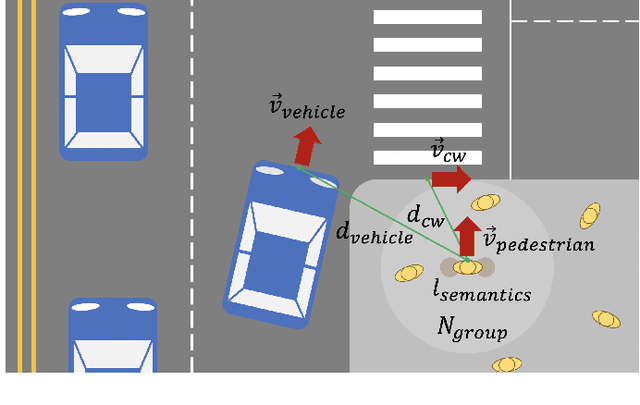
Despite recent advances in vehicle safety technologies, road traffic accidents still pose a severe threat to human lives and have become a leading cause of premature deaths. In particular, crosswalks present a major threat to pedestrians, but we lack dense behavioral data to investigate the risks they face. Therefore, we propose a comprehensive analytical model for pedestrian potential risk using video footage gathered by road security cameras deployed at such crossings. The proposed system automatically detects vehicles and pedestrians, calculates trajectories by frames, and extracts behavioral features affecting the likelihood of potentially dangerous scenes between these objects. Finally, we design a data cube model by using the large amount of the extracted features accumulated in a data warehouse to perform multidimensional analysis for potential risk scenes with levels of abstraction, but this is beyond the scope of this paper, and will be detailed in a future study. In our experiment, we focused on extracting the various behavioral features from multiple crosswalks, and visualizing and interpreting their behaviors and relationships among them by camera location to show how they may or may not contribute to potential risk. We validated feasibility and applicability by applying it in multiple crosswalks in Osan city, Korea.
A Real-time Vision Framework for Pedestrian Behavior Recognition and Intention Prediction at Intersections Using 3D Pose Estimation
Sep 23, 2020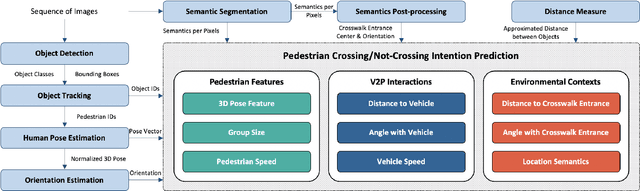
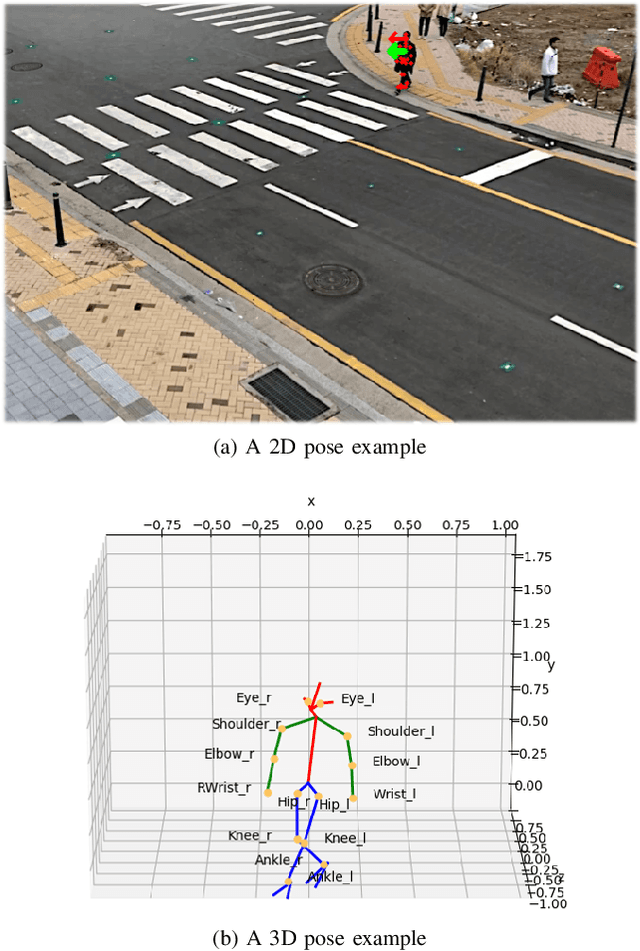

Minimizing traffic accidents between vehicles and pedestrians is one of the primary research goals in intelligent transportation systems. To achieve the goal, pedestrian behavior recognition and prediction of pedestrian's crossing or not-crossing intention play a central role. Contemporary approaches do not guarantee satisfactory performance due to lack of generalization, the requirement of manual data labeling, and high computational complexity. To overcome these limitations, we propose a real-time vision framework for two tasks: pedestrian behavior recognition (100.53 FPS) and intention prediction (35.76 FPS). Our framework obtains satisfying generalization over multiple sites because of the proposed site-independent features. At the center of the feature extraction lies 3D pose estimation. The 3D pose analysis enables robust and accurate recognition of pedestrian behaviors and prediction of intentions over multiple sites. The proposed vision framework realizes 89.3% accuracy in the behavior recognition task on the TUD dataset without any training process and 91.28% accuracy in intention prediction on our dataset achieving new state-of-the-art performance. To contribute to the corresponding research community, we make our source codes public which are available at https://github.com/Uehwan/VisionForPedestrian