 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimVODIS: Simultaneous Visual Odometry, Object Detection, and Instance Segmentation
Paper and Code

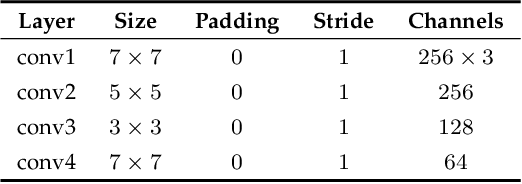


Intelligent agents need to understand the surrounding environment to provide meaningful services to or interact intelligently with humans. The agents should perceive geometric features as well as semantic entities inherent in the environment. Contemporary methods in general provide one type of information regarding the environment at a time, making it difficult to conduct high-level tasks. Moreover, running two types of methods and associating two resultant information requires a lot of computation and complicates the software architecture. To overcome these limitations, we propose a neural architecture that simultaneously performs both geometric and semantic tasks in a single thread: simultaneous visual odometry, object detection, and instance segmentation (SimVODIS). Training SimVODIS requires unlabeled video sequences and the photometric consistency between input image frames generates self-supervision signals. The performance of SimVODIS outperforms or matches the state-of-the-art performance in pose estimation, depth map prediction, object detection, and instance segmentation tasks while completing all the tasks in a single thread. We expect SimVODIS would enhance the autonomy of intelligent agents and let the agents provide effective services to humans.