 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCAP-GAN: Towards Adversarial Robustness with Cycle-consistent Attentional Purification
Paper and Code
Feb 17, 2021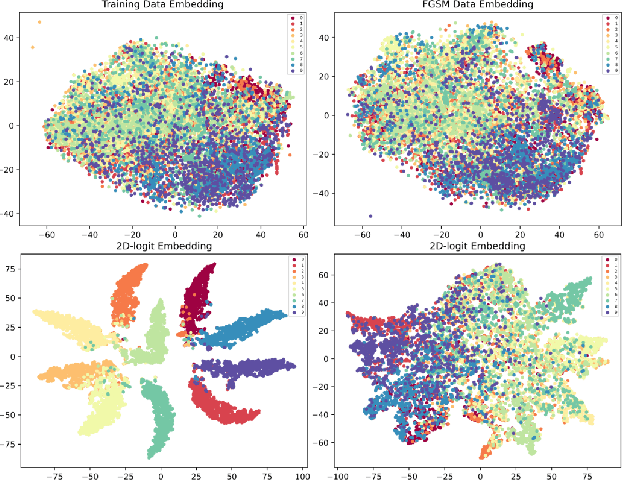
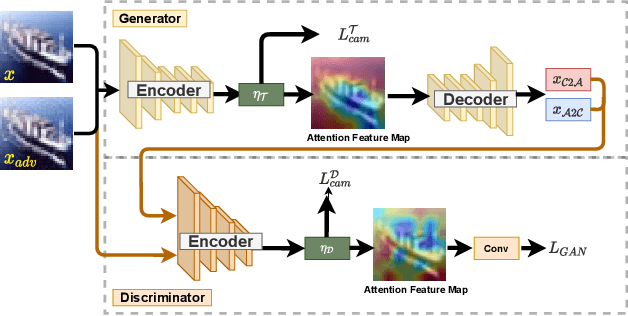
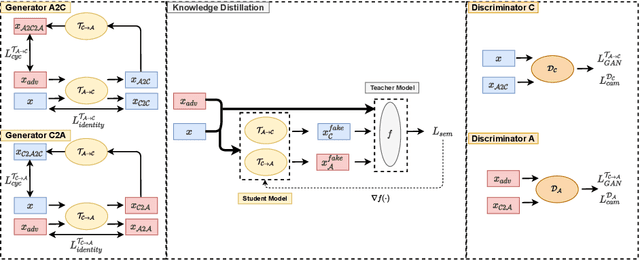
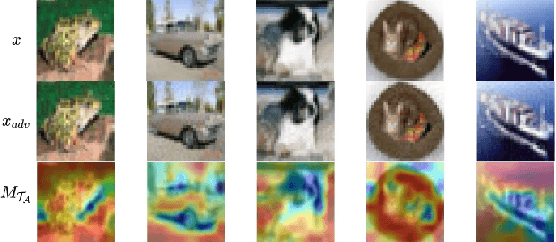
Adversarial attack is aimed at fooling the target classifier with imperceptible perturbation. Adversarial examples, which are carefully crafted with a malicious purpose, can lead to erroneous predictions, resulting in catastrophic accidents. To mitigate the effects of adversarial attacks, we propose a novel purification model called CAP-GAN. CAP-GAN takes account of the idea of pixel-level and feature-level consistency to achieve reasonable purification under cycle-consistent learning. Specifically, we utilize the guided attention module and knowledge distillation to convey meaningful information to the purification model. Once a model is fully trained, inputs would be projected into the purification model and transformed into clean-like images. We vary the capacity of the adversary to argue the robustness against various types of attack strategies. On the CIFAR-10 dataset, CAP-GAN outperforms other pre-processing based defenses under both black-box and white-box settings.