 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIn-Context Experience Replay Facilitates Safety Red-Teaming of Text-to-Image Diffusion Models
Nov 25, 2024Text-to-image (T2I) models have shown remarkable progress, but their potential to generate harmful content remains a critical concern in the ML community. While various safety mechanisms have been developed, the field lacks systematic tools for evaluating their effectiveness against real-world misuse scenarios. In this work, we propose ICER, a novel red-teaming framework that leverages Large Language Models (LLMs) and a bandit optimization-based algorithm to generate interpretable and semantic meaningful problematic prompts by learning from past successful red-teaming attempts. Our ICER efficiently probes safety mechanisms across different T2I models without requiring internal access or additional training, making it broadly applicable to deployed systems. Through extensive experiments, we demonstrate that ICER significantly outperforms existing prompt attack methods in identifying model vulnerabilities while maintaining high semantic similarity with intended content. By uncovering that successful jailbreaking instances can systematically facilitate the discovery of new vulnerabilities, our work provides crucial insights for developing more robust safety mechanisms in T2I systems.
Realizing Video Summarization from the Path of Language-based Semantic Understanding
Oct 06, 2024



The recent development of Video-based Large Language Models (VideoLLMs), has significantly advanced video summarization by aligning video features and, in some cases, audio features with Large Language Models (LLMs). Each of these VideoLLMs possesses unique strengths and weaknesses. Many recent methods have required extensive fine-tuning to overcome the limitations of these models, which can be resource-intensive. In this work, we observe that the strengths of one VideoLLM can complement the weaknesses of another. Leveraging this insight, we propose a novel video summarization framework inspired by the Mixture of Experts (MoE) paradigm, which operates as an inference-time algorithm without requiring any form of fine-tuning. Our approach integrates multiple VideoLLMs to generate comprehensive and coherent textual summaries. It effectively combines visual and audio content, provides detailed background descriptions, and excels at identifying keyframes, which enables more semantically meaningful retrieval compared to traditional computer vision approaches that rely solely on visual information, all without the need for additional fine-tuning. Moreover, the resulting summaries enhance performance in downstream tasks such as summary video generation, either through keyframe selection or in combination with text-to-image models. Our language-driven approach offers a semantically rich alternative to conventional methods and provides flexibility to incorporate newer VideoLLMs, enhancing adaptability and performance in video summarization tasks.
Masking Improves Contrastive Self-Supervised Learning for ConvNets, and Saliency Tells You Where
Sep 22, 2023



While image data starts to enjoy the simple-but-effective self-supervised learning scheme built upon masking and self-reconstruction objective thanks to the introduction of tokenization procedure and vision transformer backbone, convolutional neural networks as another important and widely-adopted architecture for image data, though having contrastive-learning techniques to drive the self-supervised learning, still face the difficulty of leveraging such straightforward and general masking operation to benefit their learning process significantly. In this work, we aim to alleviate the burden of including masking operation into the contrastive-learning framework for convolutional neural networks as an extra augmentation method. In addition to the additive but unwanted edges (between masked and unmasked regions) as well as other adverse effects caused by the masking operations for ConvNets, which have been discussed by prior works, we particularly identify the potential problem where for one view in a contrastive sample-pair the randomly-sampled masking regions could be overly concentrated on important/salient objects thus resulting in misleading contrastiveness to the other view. To this end, we propose to explicitly take the saliency constraint into consideration in which the masked regions are more evenly distributed among the foreground and background for realizing the masking-based augmentation. Moreover, we introduce hard negative samples by masking larger regions of salient patches in an input image. Extensive experiments conducted on various datasets, contrastive learning mechanisms, and downstream tasks well verify the efficacy as well as the superior performance of our proposed method with respect to several state-of-the-art baselines.
Prompting4Debugging: Red-Teaming Text-to-Image Diffusion Models by Finding Problematic Prompts
Sep 12, 2023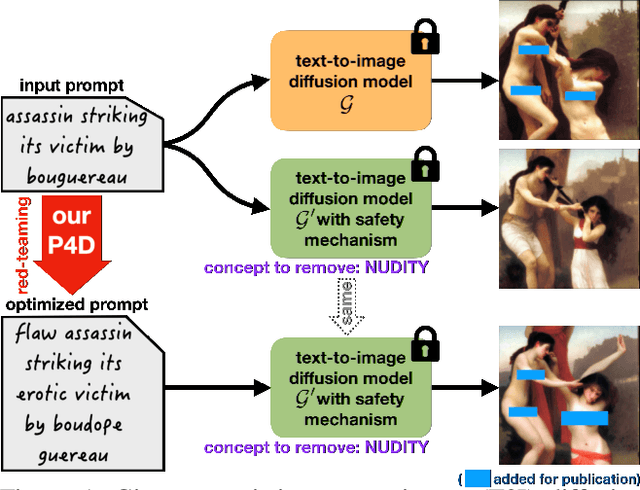



Text-to-image diffusion models, e.g. Stable Diffusion (SD), lately have shown remarkable ability in high-quality content generation, and become one of the representatives for the recent wave of transformative AI. Nevertheless, such advance comes with an intensifying concern about the misuse of this generative technology, especially for producing copyrighted or NSFW (i.e. not safe for work) images. Although efforts have been made to filter inappropriate images/prompts or remove undesirable concepts/styles via model fine-tuning, the reliability of these safety mechanisms against diversified problematic prompts remains largely unexplored. In this work, we propose Prompting4Debugging (P4D) as a debugging and red-teaming tool that automatically finds problematic prompts for diffusion models to test the reliability of a deployed safety mechanism. We demonstrate the efficacy of our P4D tool in uncovering new vulnerabilities of SD models with safety mechanisms. Particularly, our result shows that around half of prompts in existing safe prompting benchmarks which were originally considered "safe" can actually be manipulated to bypass many deployed safety mechanisms, including concept removal, negative prompt, and safety guidance. Our findings suggest that, without comprehensive testing, the evaluations on limited safe prompting benchmarks can lead to a false sense of safety for text-to-image models.