 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBARIS: Boundary-Aware Refinement with Environmental Degradation Priors for Robust Underwater Instance Segmentation
Apr 28, 2025Underwater instance segmentation is challenging due to adverse visual conditions such as light attenuation, scattering, and color distortion, which degrade model performance. In this work, we propose BARIS-Decoder (Boundary-Aware Refinement Decoder for Instance Segmentation), a framework that enhances segmentation accuracy through feature refinement. To address underwater degradations, we introduce the Environmental Robust Adapter (ERA), which efficiently models underwater degradation patterns while reducing trainable parameters by over 90\% compared to full fine-tuning. The integration of BARIS-Decoder with ERA-tuning, referred to as BARIS-ERA, achieves state-of-the-art performance, surpassing Mask R-CNN by 3.4 mAP with a Swin-B backbone and 3.8 mAP with ConvNeXt V2. Our findings demonstrate the effectiveness of BARIS-ERA in advancing underwater instance segmentation, providing a robust and efficient solution.
Always Clear Days: Degradation Type and Severity Aware All-In-One Adverse Weather Removal
Oct 27, 2023



All-in-one adverse weather removal is an emerging topic on image restoration, which aims to restore multiple weather degradation in an unified model, and the challenging are twofold. First, discovering and handling the property of multi-domain in target distribution formed by multiple weather conditions. Second, design efficient and effective operations for different degradation types. To address this problem, most prior works focus on the multi-domain caused by weather type. Inspired by inter\&intra-domain adaptation literature, we observed that not only weather type but also weather severity introduce multi-domain within each weather type domain, which is ignored by previous methods, and further limit their performance. To this end, we proposed a degradation type and severity aware model, called \textbf{UtilityIR}, for blind all-in-one bad weather image restoration. To extract weather information from single image, we proposed a novel Marginal Quality Ranking Loss (MQRL) and utilized Contrastive Loss (CL) to guide weather severity and type extraction, and leverage a bag of novel techniques such as Multi-Head Cross Attention (MHCA) and Local-Global Adaptive Instance Normalization (LG-AdaIN) to efficiently restore spatial varying weather degradation. The proposed method can significantly outperform the SOTA methods subjectively and objectively on different weather restoration tasks with a large margin, and enjoy less model parameters. Proposed method even can restore \textbf{unseen} domain combined multiple degradation images, and modulating restoration level. Implementation code will be available at {https://github.com/fordevoted/UtilityIR}{\textit{this repository}}
Panoptic-Depth Color Map for Combination of Depth and Image Segmentation
Aug 24, 2023Image segmentation and depth estimation are crucial tasks in computer vision, especially in autonomous driving scenarios. Although these tasks are typically addressed separately, we propose an innovative approach to combine them in our novel deep learning network, Panoptic-DepthLab. By incorporating an additional depth estimation branch into the segmentation network, it can predict the depth of each instance segment. Evaluating on Cityscape dataset, we demonstrate the effectiveness of our method in achieving high-quality segmentation results with depth and visualize it with a color map. Our proposed method demonstrates a new possibility of combining different tasks and networks to generate a more comprehensive image recognition result to facilitate the safety of autonomous driving vehicles.
Perspective-aware Convolution for Monocular 3D Object Detection
Aug 24, 2023Monocular 3D object detection is a crucial and challenging task for autonomous driving vehicle, while it uses only a single camera image to infer 3D objects in the scene. To address the difficulty of predicting depth using only pictorial clue, we propose a novel perspective-aware convolutional layer that captures long-range dependencies in images. By enforcing convolutional kernels to extract features along the depth axis of every image pixel, we incorporates perspective information into network architecture. We integrate our perspective-aware convolutional layer into a 3D object detector and demonstrate improved performance on the KITTI3D dataset, achieving a 23.9\% average precision in the easy benchmark. These results underscore the importance of modeling scene clues for accurate depth inference and highlight the benefits of incorporating scene structure in network design. Our perspective-aware convolutional layer has the potential to enhance object detection accuracy by providing more precise and context-aware feature extraction.
Domain Adaptation for Underwater Image Enhancement via Content and Style Separation
Feb 17, 2022


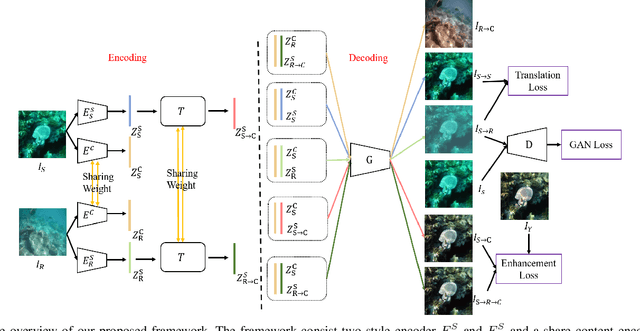
Underwater image suffer from color cast, low contrast and hazy effect due to light absorption, refraction and scattering, which degraded the high-level application, e.g, object detection and object tracking. Recent learning-based methods demonstrate astonishing performance on underwater image enhancement, however, most of these works use synthesis pair data for supervised learning and ignore the domain gap to real-world data. In this paper, we propose a domain adaptation framework for underwater image enhancement via content and style separation, we assume image could be disentangled to content and style latent, and image could be clustered to the sub-domain of associated style in latent space, the goal is to build up the mapping between underwater style latent and clean one. Different from prior works of domain adaptation for underwater image enhancement, which target to minimize the latent discrepancy of synthesis and real-world data, we aim to distinguish style latent from different sub-domains. To solve the problem of lacking pair real-world data, we leverage synthesis to real image-to-image translation to obtain pseudo real underwater image pairs for supervised learning, and enhancement can be achieved by input content and clean style latent into generator. Our model provide a user interact interface to adjust different enhanced level by latent manipulation. Experiment on various public real-world underwater benchmarks demonstrate that the proposed framework is capable to perform domain adaptation for underwater image enhancement and outperform various state-of-the-art underwater image enhancement algorithms in quantity and quality. The model and source code are available at https://github.com/fordevoted/UIESS
Explorable Tone Mapping Operators
Oct 20, 2020
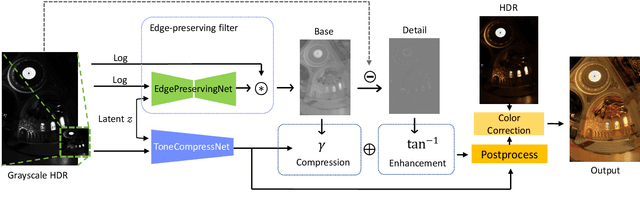


Tone-mapping plays an essential role in high dynamic range (HDR) imaging. It aims to preserve visual information of HDR images in a medium with a limited dynamic range. Although many works have been proposed to provide tone-mapped results from HDR images, most of them can only perform tone-mapping in a single pre-designed way. However, the subjectivity of tone-mapping quality varies from person to person, and the preference of tone-mapping style also differs from application to application. In this paper, a learning-based multimodal tone-mapping method is proposed, which not only achieves excellent visual quality but also explores the style diversity. Based on the framework of BicycleGAN, the proposed method can provide a variety of expert-level tone-mapped results by manipulating different latent codes. Finally, we show that the proposed method performs favorably against state-of-the-art tone-mapping algorithms both quantitatively and qualitatively.
Discrete Gyrator Transforms: Computational Algorithms and Applications
Jun 03, 2017
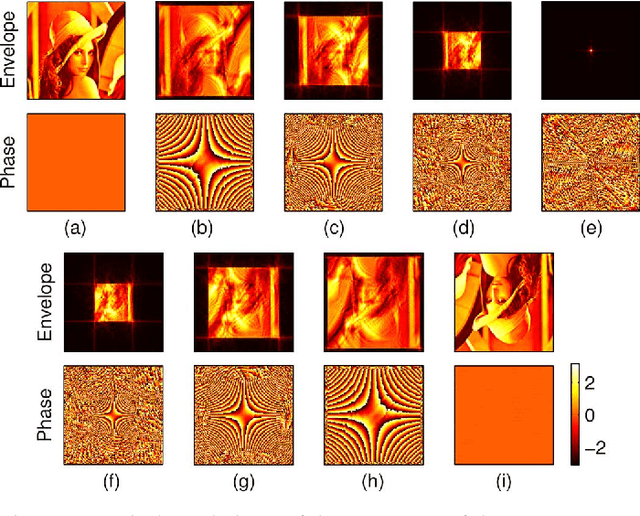
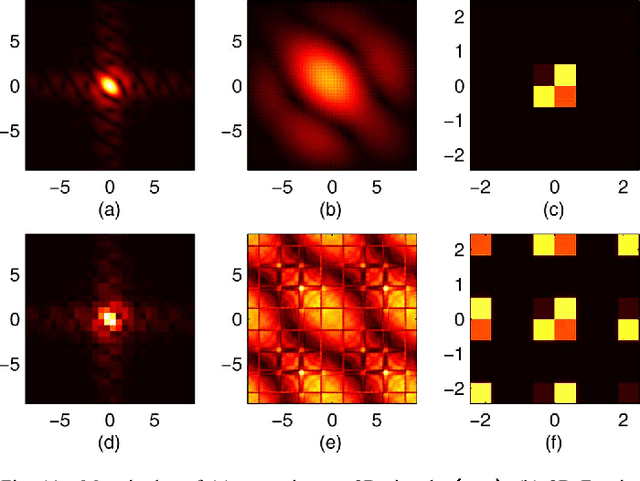

As an extension of the 2D fractional Fourier transform (FRFT) and a special case of the 2D linear canonical transform (LCT), the gyrator transform was introduced to produce rotations in twisted space/spatial-frequency planes. It is a useful tool in optics, signal processing and image processing. In this paper, we develop discrete gyrator transforms (DGTs) based on the 2D LCT. Taking the advantage of the additivity property of the 2D LCT, we propose three kinds of DGTs, each of which is a cascade of low-complexity operators. These DGTs have different constraints, characteristics, and properties, and are realized by different computational algorithms. Besides, we propose a kind of DGT based on the eigenfunctions of the gyrator transform. This DGT is an orthonormal transform, and thus its comprehensive properties, especially the additivity property, make it more useful in many applications. We also develop an efficient computational algorithm to significantly reduce the complexity of this DGT. At the end, a brief review of some important applications of the DGTs is presented, including mode conversion, sampling and reconstruction, watermarking, and image encryption.
* Accepted by IEEE Transactions on Signal Processing
Two-dimensional nonseparable discrete linear canonical transform based on CM-CC-CM-CC decomposition
May 26, 2017

As a generalization of the two-dimensional Fourier transform (2D FT) and 2D fractional Fourier transform, the 2D nonseparable linear canonical transform (2D NsLCT) is useful in optics, signal and image processing. To reduce the digital implementation complexity of the 2D NsLCT, some previous works decomposed the 2D NsLCT into several low-complexity operations, including 2D FT, 2D chirp multiplication (2D CM) and 2D affine transformations. However, 2D affine transformations will introduce interpolation error. In this paper, we propose a new decomposition called CM-CC-CM-CC decomposition, which decomposes the 2D NsLCT into two 2D CMs and two 2D chirp convolutions (2D CCs). No 2D affine transforms are involved. Simulation results show that the proposed methods have higher accuracy, lower computational complexity and smaller error in the additivity property compared with the previous works. Plus, the proposed methods have perfect reversibility property that one can reconstruct the input signal/image losslessly from the output.
* Accepted by Journal of the Optical Society of America A (JOSA A)
Fast Binary Embedding via Circulant Downsampled Matrix -- A Data-Independent Approach
Jan 24, 2016
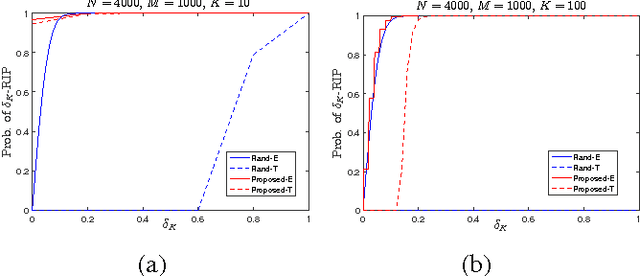
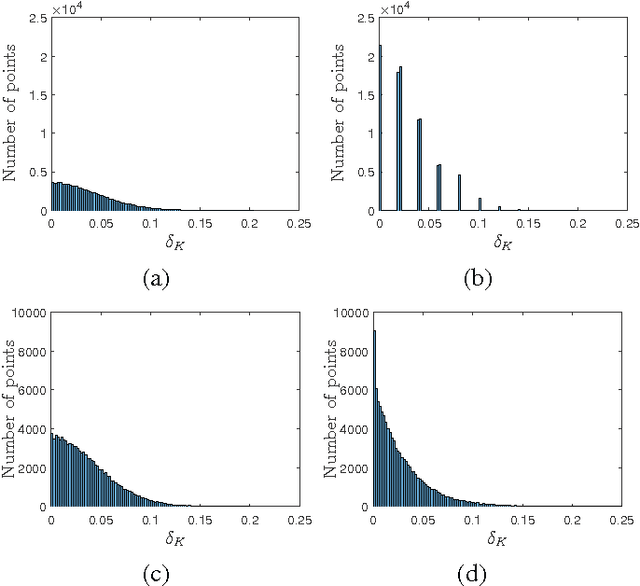

Binary embedding of high-dimensional data aims to produce low-dimensional binary codes while preserving discriminative power. State-of-the-art methods often suffer from high computation and storage costs. We present a simple and fast embedding scheme by first downsampling N-dimensional data into M-dimensional data and then multiplying the data with an MxM circulant matrix. Our method requires O(N +M log M) computation and O(N) storage costs. We prove if data have sparsity, our scheme can achieve similarity-preserving well. Experiments further demonstrate that though our method is cost-effective and fast, it still achieves comparable performance in image applications.