 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Batch Correction for Cell Painting via Batch-Dependent Kernels and Adaptive Sampling
Jan 29, 2026Cell Painting is a microscopy-based, high-content imaging assay that produces rich morphological profiles of cells and can support drug discovery by quantifying cellular responses to chemical perturbations. At scale, however, Cell Painting data is strongly affected by batch effects arising from differences in laboratories, instruments, and protocols, which can obscure biological signal. We present BALANS (Batch Alignment via Local Affinities and Subsampling), a scalable batch-correction method that aligns samples across batches by constructing a smoothed affinity matrix from pairwise distances. Given $n$ data points, BALANS builds a sparse affinity matrix $A \in \mathbb{R}^{n \times n}$ using two ideas. (i) For points $i$ and $j$, it sets a local scale using the distance from $i$ to its $k$-th nearest neighbor within the batch of $j$, then computes $A_{ij}$ via a Gaussian kernel calibrated by these batch-aware local scales. (ii) Rather than forming all $n^2$ entries, BALANS uses an adaptive sampling procedure that prioritizes rows with low cumulative neighbor coverage and retains only the strongest affinities per row, yielding a sparse but informative approximation of $A$. We prove that this sampling strategy is order-optimal in sample complexity and provides an approximation guarantee, and we show that BALANS runs in nearly linear time in $n$. Experiments on diverse real-world Cell Painting datasets and controlled large-scale synthetic benchmarks demonstrate that BALANS scales to large collections while improving runtime over native implementations of widely used batch-correction methods, without sacrificing correction quality.
A Survey of Large Language Models for Text-Guided Molecular Discovery: from Molecule Generation to Optimization
May 22, 2025Large language models (LLMs) are introducing a paradigm shift in molecular discovery by enabling text-guided interaction with chemical spaces through natural language, symbolic notations, with emerging extensions to incorporate multi-modal inputs. To advance the new field of LLM for molecular discovery, this survey provides an up-to-date and forward-looking review of the emerging use of LLMs for two central tasks: molecule generation and molecule optimization. Based on our proposed taxonomy for both problems, we analyze representative techniques in each category, highlighting how LLM capabilities are leveraged across different learning settings. In addition, we include the commonly used datasets and evaluation protocols. We conclude by discussing key challenges and future directions, positioning this survey as a resource for researchers working at the intersection of LLMs and molecular science. A continuously updated reading list is available at https://github.com/REAL-Lab-NU/Awesome-LLM-Centric-Molecular-Discovery.
DMol: A Schedule-Driven Diffusion Model for Highly Efficient and Versatile Molecule Generation
Apr 08, 2025We introduce a new graph diffusion model for small molecule generation, \emph{DMol}, which outperforms the state-of-the-art DiGress model in terms of validity by roughly $1.5\%$ across all benchmarking datasets while reducing the number of diffusion steps by at least $10$-fold, and the running time to roughly one half. The performance improvements are a result of a careful change in the objective function and a ``graph noise" scheduling approach which, at each diffusion step, allows one to only change a subset of nodes of varying size in the molecule graph. Another relevant property of the method is that it can be easily combined with junction-tree-like graph representations that arise by compressing a collection of relevant ring structures into supernodes. Unlike classical junction-tree techniques that involve VAEs and require complicated reconstruction steps, compressed DMol directly performs graph diffusion on a graph that compresses only a carefully selected set of frequent carbon rings into supernodes, which results in straightforward sample generation. This compressed DMol method offers additional validity improvements over generic DMol of roughly $2\%$, increases the novelty of the method, and further improves the running time due to reductions in the graph size.
Improved far-field speech recognition using Joint Variational Autoencoder
Apr 24, 2022
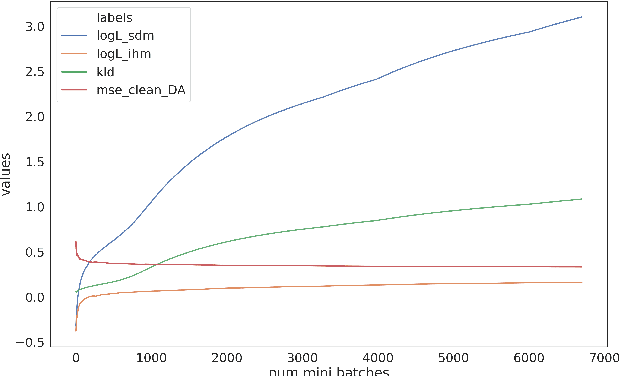

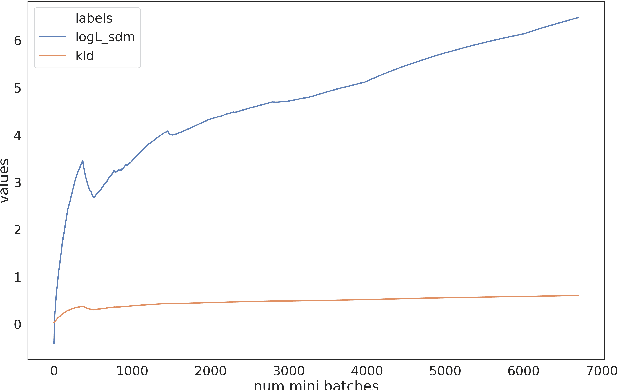
Automatic Speech Recognition (ASR) systems suffer considerably when source speech is corrupted with noise or room impulse responses (RIR). Typically, speech enhancement is applied in both mismatched and matched scenario training and testing. In matched setting, acoustic model (AM) is trained on dereverberated far-field features while in mismatched setting, AM is fixed. In recent past, mapping speech features from far-field to close-talk using denoising autoencoder (DA) has been explored. In this paper, we focus on matched scenario training and show that the proposed joint VAE based mapping achieves a significant improvement over DA. Specifically, we observe an absolute improvement of 2.5% in word error rate (WER) compared to DA based enhancement and 3.96% compared to AM trained directly on far-field filterbank features.
Spectral Modification Based Data Augmentation For Improving End-to-End ASR For Children's Speech
Mar 13, 2022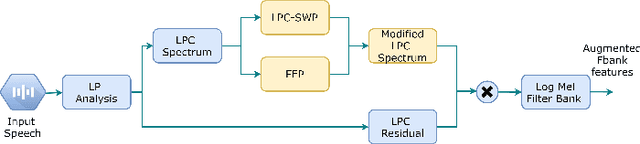
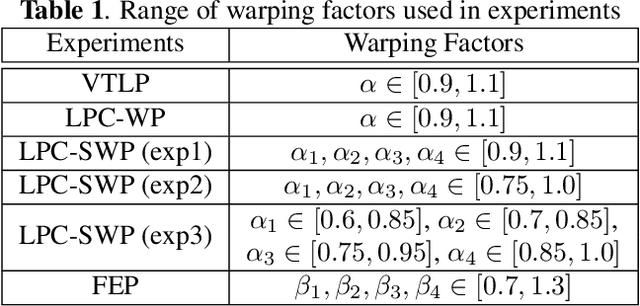
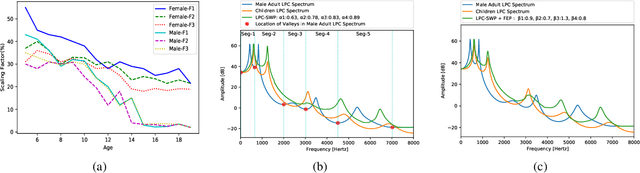
Training a robust Automatic Speech Recognition (ASR) system for children's speech recognition is a challenging task due to inherent differences in acoustic attributes of adult and child speech and scarcity of publicly available children's speech dataset. In this paper, a novel segmental spectrum warping and perturbations in formant energy are introduced, to generate a children-like speech spectrum from that of an adult's speech spectrum. Then, this modified adult spectrum is used as augmented data to improve end-to-end ASR systems for children's speech recognition. The proposed data augmentation methods give 6.5% and 6.1% relative reduction in WER on children dev and test sets respectively, compared to the vocal tract length perturbation (VTLP) baseline system trained on Librispeech 100 hours adult speech dataset. When children's speech data is added in training with Librispeech set, it gives a 3.7 % and 5.1% relative reduction in WER, compared to the VTLP baseline system.
A Mixture of Expert Based Deep Neural Network for Improved ASR
Dec 02, 2021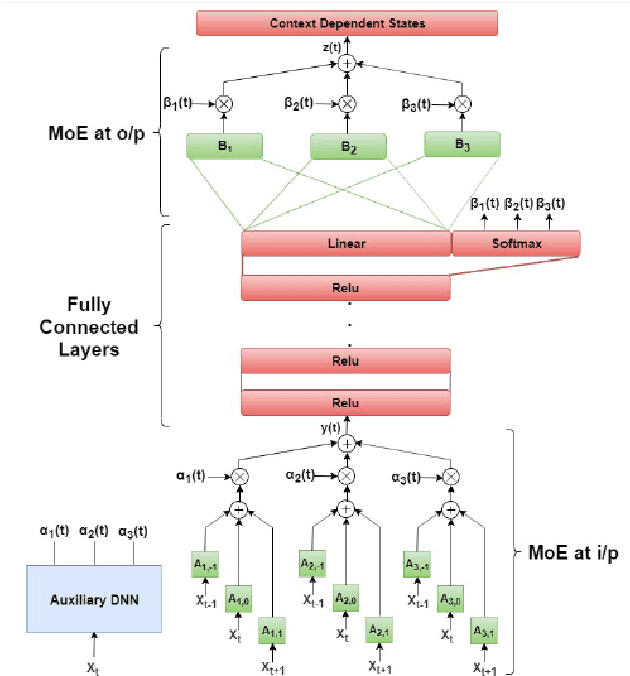
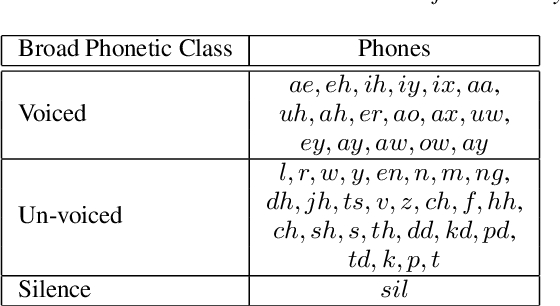
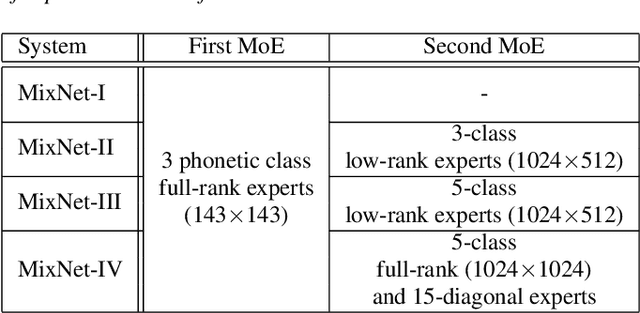
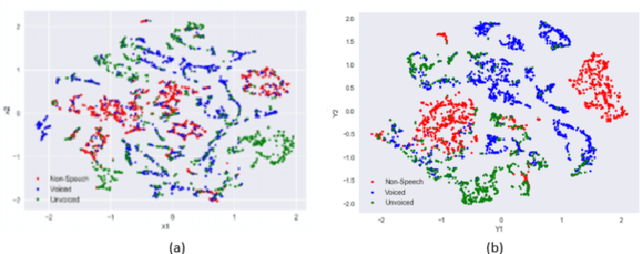
This paper presents a novel deep learning architecture for acoustic model in the context of Automatic Speech Recognition (ASR), termed as MixNet. Besides the conventional layers, such as fully connected layers in DNN-HMM and memory cells in LSTM-HMM, the model uses two additional layers based on Mixture of Experts (MoE). The first MoE layer operating at the input is based on pre-defined broad phonetic classes and the second layer operating at the penultimate layer is based on automatically learned acoustic classes. In natural speech, overlap in distribution across different acoustic classes is inevitable, which leads to inter-class mis-classification. The ASR accuracy is expected to improve if the conventional architecture of acoustic model is modified to make them more suitable to account for such overlaps. MixNet is developed keeping this in mind. Analysis conducted by means of scatter diagram verifies that MoE indeed improves the separation between classes that translates to better ASR accuracy. Experiments are conducted on a large vocabulary ASR task which show that the proposed architecture provides 13.6% and 10.0% relative reduction in word error rates compared to the conventional models, namely, DNN and LSTM respectively, trained using sMBR criteria. In comparison to an existing method developed for phone-classification (by Eigen et al), our proposed method yields a significant improvement.
A higher order Minkowski loss for improved prediction ability of acoustic model in ASR
Dec 02, 2021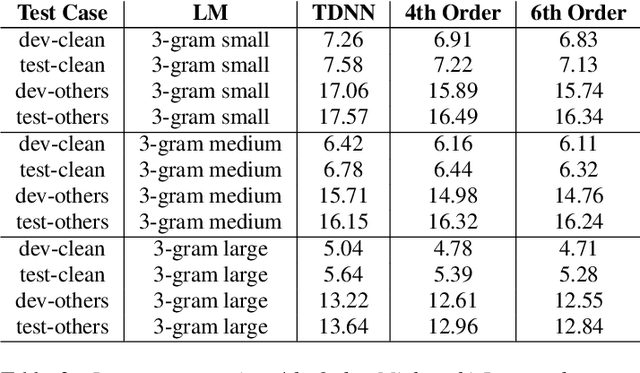
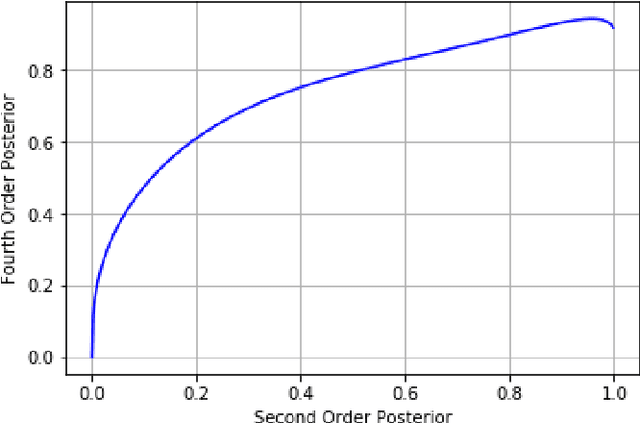
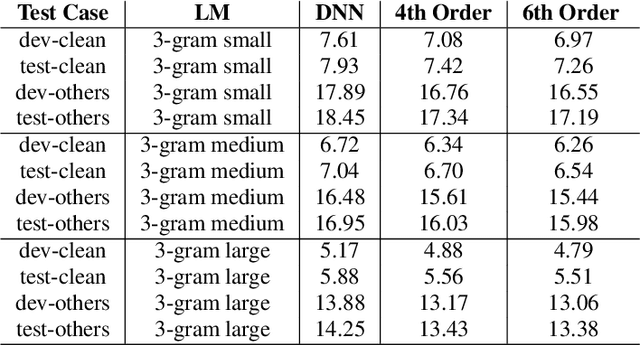
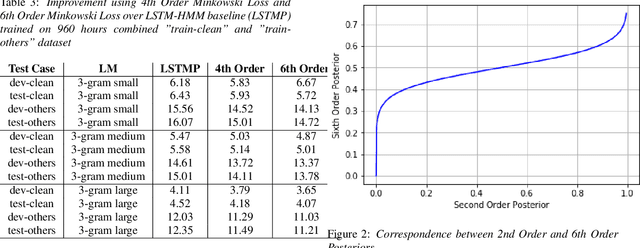
Conventional automatic speech recognition (ASR) system uses second-order minkowski loss during inference time which is suboptimal as it incorporates only first order statistics in posterior estimation [2]. In this paper we have proposed higher order minkowski loss (4th Order and 6th Order) during inference time, without any changes during training time. The main contribution of the paper is to show that higher order loss uses higher order statistics in posterior estimation, which improves the prediction ability of acoustic model in ASR system. We have shown mathematically that posterior probability obtained due to higher order loss is function of second order posterior and thus the method can be incorporated in standard ASR system in an easy manner. It is to be noted that all changes are proposed during test(inference) time, we do not make any change in any training pipeline. Multiple baseline systems namely, TDNN1, TDNN2, DNN and LSTM are developed to verify the improvement incurred due to higher order minkowski loss. All experiments are conducted on LibriSpeech dataset and performance metrics are word error rate (WER) on "dev-clean", "test-clean", "dev-other" and "test-other" datasets.
SRIB Submission to Interspeech 2021 DiCOVA Challenge
Jun 15, 2021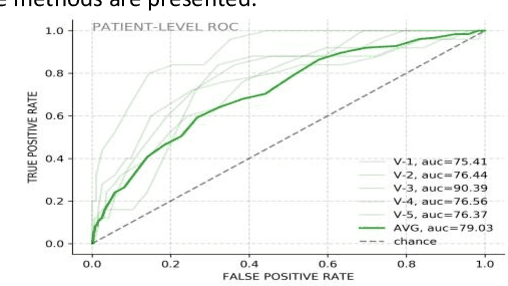
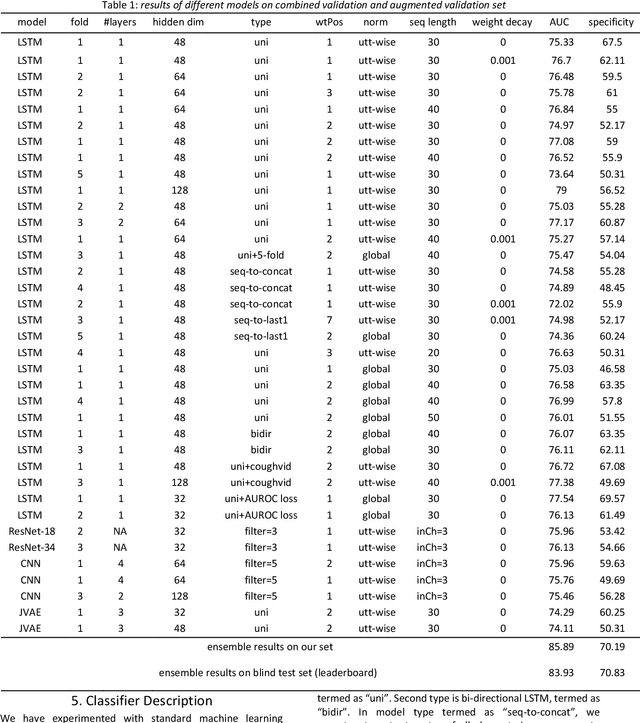
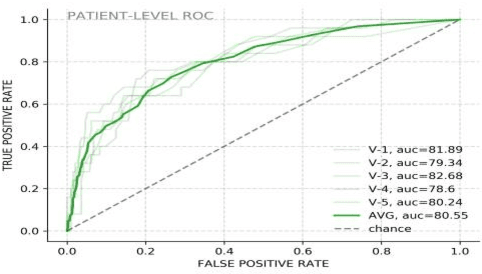
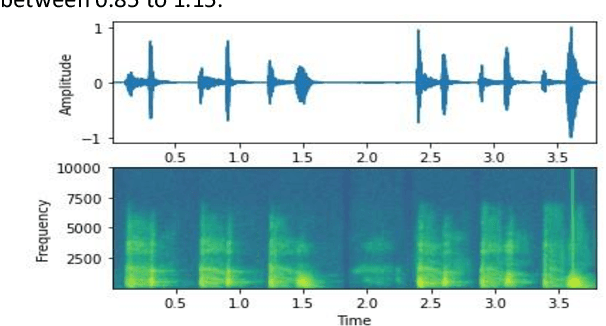
The COVID-19 pandemic has resulted in more than 125 million infections and more than 2.7 million casualties. In this paper, we attempt to classify covid vs non-covid cough sounds using signal processing and deep learning methods. Air turbulence, the vibration of tissues, movement of fluid through airways, opening, and closure of glottis are some of the causes for the production of the acoustic sound signals during cough. Does the COVID-19 alter the acoustic characteristics of breath, cough, and speech sounds produced through the respiratory system? This is an open question waiting for answers. In this paper, we incorporated novel data augmentation methods for cough sound augmentation and multiple deep neural network architectures and methods along with handcrafted features. Our proposed system gives 14% absolute improvement in area under the curve (AUC). The proposed system is developed as part of Interspeech 2021 special sessions and challenges viz. diagnosing of COVID-19 using acoustics (DiCOVA). Our proposed method secured the 5th position on the leaderboard among 29 participants.
Color and Shape Content Based Image Classification using RBF Network and PSO Technique: A Survey
Nov 27, 2013The improvement of the accuracy of image query retrieval used image classification technique. Image classification is well known technique of supervised learning. The improved method of image classification increases the working efficiency of image query retrieval. For the improvements of classification technique we used RBF neural network function for better prediction of feature used in image retrieval.Colour content is represented by pixel values in image classification using radial base function(RBF) technique. This approach provides better result compare to SVM technique in image representation.Image is represented by matrix though RBF using pixel values of colour intensity of image. Firstly we using RGB colour model. In this colour model we use red, green and blue colour intensity values in matrix.SVM with partical swarm optimization for image classification is implemented in content of images which provide better Results based on the proposed approach are found encouraging in terms of color image classification accuracy.