 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproved far-field speech recognition using Joint Variational Autoencoder
Paper and Code
Apr 24, 2022
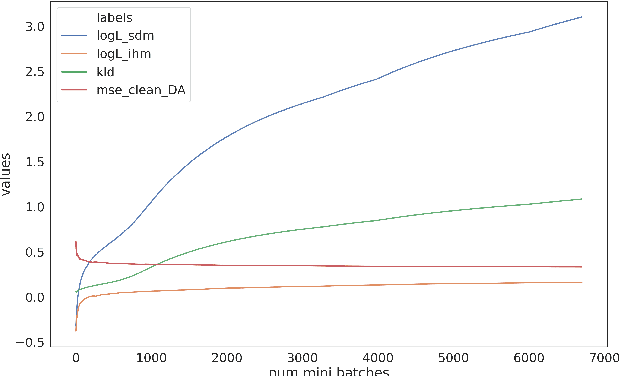

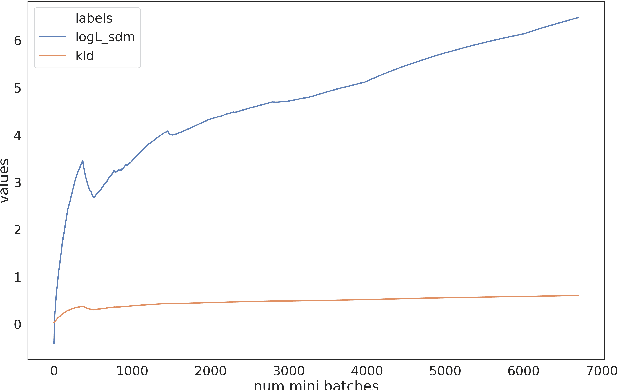
Automatic Speech Recognition (ASR) systems suffer considerably when source speech is corrupted with noise or room impulse responses (RIR). Typically, speech enhancement is applied in both mismatched and matched scenario training and testing. In matched setting, acoustic model (AM) is trained on dereverberated far-field features while in mismatched setting, AM is fixed. In recent past, mapping speech features from far-field to close-talk using denoising autoencoder (DA) has been explored. In this paper, we focus on matched scenario training and show that the proposed joint VAE based mapping achieves a significant improvement over DA. Specifically, we observe an absolute improvement of 2.5% in word error rate (WER) compared to DA based enhancement and 3.96% compared to AM trained directly on far-field filterbank features.