 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinuous Learning for Children's ASR: Overcoming Catastrophic Forgetting with Elastic Weight Consolidation and Synaptic Intelligence
May 26, 2025In this work, we present the first study addressing automatic speech recognition (ASR) for children in an online learning setting. This is particularly important for both child-centric applications and the privacy protection of minors, where training models with sequentially arriving data is critical. The conventional approach of model fine-tuning often suffers from catastrophic forgetting. To tackle this issue, we explore two established techniques: elastic weight consolidation (EWC) and synaptic intelligence (SI). Using a custom protocol on the MyST corpus, tailored to the online learning setting, we achieve relative word error rate (WER) reductions of 5.21% with EWC and 4.36% with SI, compared to the fine-tuning baseline.
STOPA: A Database of Systematic VariaTion Of DeePfake Audio for Open-Set Source Tracing and Attribution
May 26, 2025A key research area in deepfake speech detection is source tracing - determining the origin of synthesised utterances. The approaches may involve identifying the acoustic model (AM), vocoder model (VM), or other generation-specific parameters. However, progress is limited by the lack of a dedicated, systematically curated dataset. To address this, we introduce STOPA, a systematically varied and metadata-rich dataset for deepfake speech source tracing, covering 8 AMs, 6 VMs, and diverse parameter settings across 700k samples from 13 distinct synthesisers. Unlike existing datasets, which often feature limited variation or sparse metadata, STOPA provides a systematically controlled framework covering a broader range of generative factors, such as the choice of the vocoder model, acoustic model, or pretrained weights, ensuring higher attribution reliability. This control improves attribution accuracy, aiding forensic analysis, deepfake detection, and generative model transparency.
Causal Analysis of ASR Errors for Children: Quantifying the Impact of Physiological, Cognitive, and Extrinsic Factors
Feb 12, 2025The increasing use of children's automatic speech recognition (ASR) systems has spurred research efforts to improve the accuracy of models designed for children's speech in recent years. The current approach utilizes either open-source speech foundation models (SFMs) directly or fine-tuning them with children's speech data. These SFMs, whether open-source or fine-tuned for children, often exhibit higher word error rates (WERs) compared to adult speech. However, there is a lack of systemic analysis of the cause of this degraded performance of SFMs. Understanding and addressing the reasons behind this performance disparity is crucial for improving the accuracy of SFMs for children's speech. Our study addresses this gap by investigating the causes of accuracy degradation and the primary contributors to WER in children's speech. In the first part of the study, we conduct a comprehensive benchmarking study on two self-supervised SFMs (Wav2Vec2.0 and Hubert) and two weakly supervised SFMs (Whisper and MMS) across various age groups on two children speech corpora, establishing the raw data for the causal inference analysis in the second part. In the second part of the study, we analyze the impact of physiological factors (age, gender), cognitive factors (pronunciation ability), and external factors (vocabulary difficulty, background noise, and word count) on SFM accuracy in children's speech using causal inference. The results indicate that physiology (age) and particular external factor (number of words in audio) have the highest impact on accuracy, followed by background noise and pronunciation ability. Fine-tuning SFMs on children's speech reduces sensitivity to physiological and cognitive factors, while sensitivity to the number of words in audio persists. Keywords: Children's ASR, Speech Foundational Models, Causal Inference, Physiology, Cognition, Pronunciation
ROAR: Reinforcing Original to Augmented Data Ratio Dynamics for Wav2Vec2.0 Based ASR
Jun 14, 2024



While automatic speech recognition (ASR) greatly benefits from data augmentation, the augmentation recipes themselves tend to be heuristic. In this paper, we address one of the heuristic approach associated with balancing the right amount of augmented data in ASR training by introducing a reinforcement learning (RL) based dynamic adjustment of original-to-augmented data ratio (OAR). Unlike the fixed OAR approach in conventional data augmentation, our proposed method employs a deep Q-network (DQN) as the RL mechanism to learn the optimal dynamics of OAR throughout the wav2vec2.0 based ASR training. We conduct experiments using the LibriSpeech dataset with varying amounts of training data, specifically, the 10Min, 1H, 10H, and 100H splits to evaluate the efficacy of the proposed method under different data conditions. Our proposed method, on average, achieves a relative improvement of 4.96% over the open-source wav2vec2.0 base model on standard LibriSpeech test sets.
* Accepted: Interspeech 2024
ChildAugment: Data Augmentation Methods for Zero-Resource Children's Speaker Verification
Feb 23, 2024



The accuracy of modern automatic speaker verification (ASV) systems, when trained exclusively on adult data, drops substantially when applied to children's speech. The scarcity of children's speech corpora hinders fine-tuning ASV systems for children's speech. Hence, there is a timely need to explore more effective ways of reusing adults' speech data. One promising approach is to align vocal-tract parameters between adults and children through children-specific data augmentation, referred here to as ChildAugment. Specifically, we modify the formant frequencies and formant bandwidths of adult speech to emulate children's speech. The modified spectra are used to train ECAPA-TDNN (emphasized channel attention, propagation, and aggregation in time-delay neural network) recognizer for children. We compare ChildAugment against various state-of-the-art data augmentation techniques for children's ASV. We also extensively compare different scoring methods, including cosine scoring, PLDA (probabilistic linear discriminant analysis), and NPLDA (neural PLDA). We also propose a low-complexity weighted cosine score for extremely low-resource children ASV. Our findings on the CSLU kids corpus indicate that ChildAugment holds promise as a simple, acoustics-motivated approach, for improving state-of-the-art deep learning based ASV for children. We achieve up to 12.45% (boys) and 11.96% (girls) relative improvement over the baseline.
Speaker Verification Across Ages: Investigating Deep Speaker Embedding Sensitivity to Age Mismatch in Enrollment and Test Speech
Jun 13, 2023In this paper, we study the impact of the ageing on modern deep speaker embedding based automatic speaker verification (ASV) systems. We have selected two different datasets to examine ageing on the state-of-the-art ECAPA-TDNN system. The first dataset, used for addressing short-term ageing (up to 10 years time difference between enrollment and test) under uncontrolled conditions, is VoxCeleb. The second dataset, used for addressing long-term ageing effect (up to 40 years difference) of Finnish speakers under a more controlled setup, is Longitudinal Corpus of Finnish Spoken in Helsinki (LCFSH). Our study provides new insights into the impact of speaker ageing on modern ASV systems. Specifically, we establish a quantitative measure between ageing and ASV scores. Further, our research indicates that ageing affects female English speakers to a greater degree than male English speakers, while in the case of Finnish, it has a greater impact on male speakers than female speakers.
Spectral Modification Based Data Augmentation For Improving End-to-End ASR For Children's Speech
Mar 13, 2022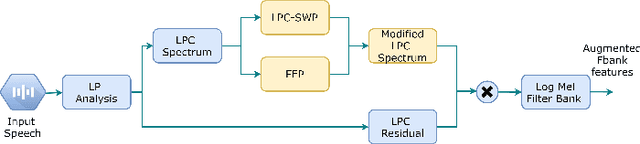
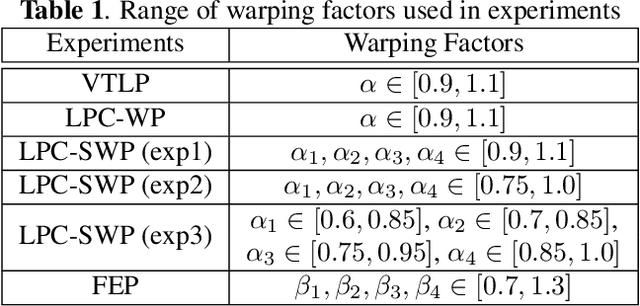
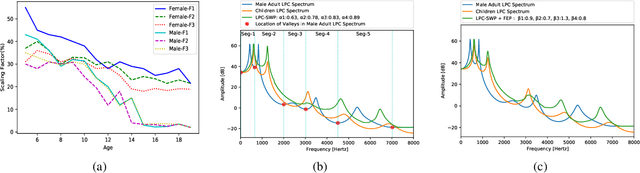
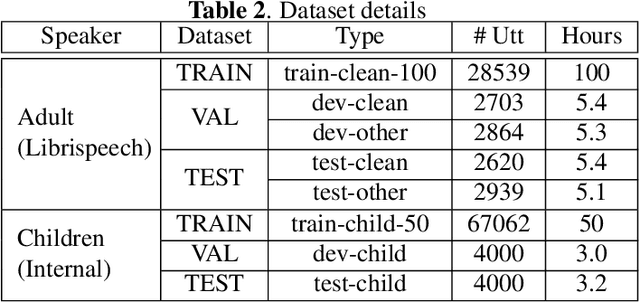
Training a robust Automatic Speech Recognition (ASR) system for children's speech recognition is a challenging task due to inherent differences in acoustic attributes of adult and child speech and scarcity of publicly available children's speech dataset. In this paper, a novel segmental spectrum warping and perturbations in formant energy are introduced, to generate a children-like speech spectrum from that of an adult's speech spectrum. Then, this modified adult spectrum is used as augmented data to improve end-to-end ASR systems for children's speech recognition. The proposed data augmentation methods give 6.5% and 6.1% relative reduction in WER on children dev and test sets respectively, compared to the vocal tract length perturbation (VTLP) baseline system trained on Librispeech 100 hours adult speech dataset. When children's speech data is added in training with Librispeech set, it gives a 3.7 % and 5.1% relative reduction in WER, compared to the VTLP baseline system.
A Mixture of Expert Based Deep Neural Network for Improved ASR
Dec 02, 2021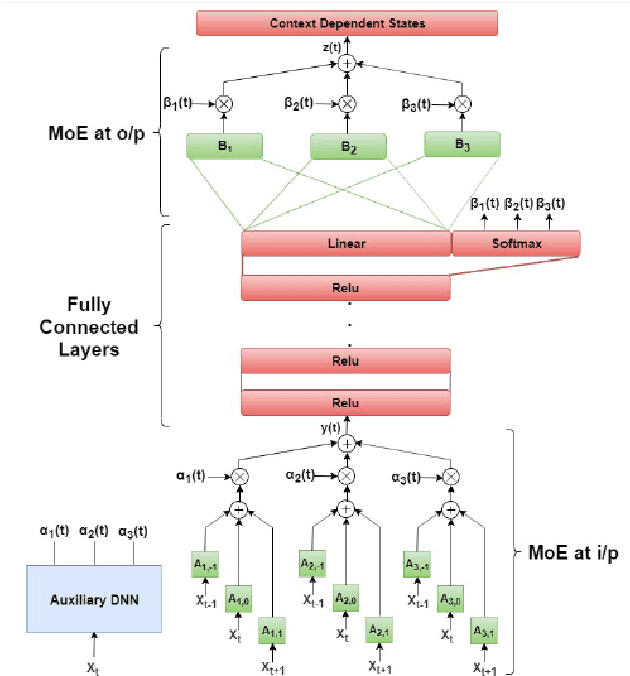
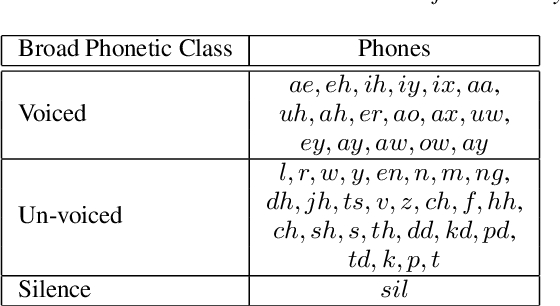
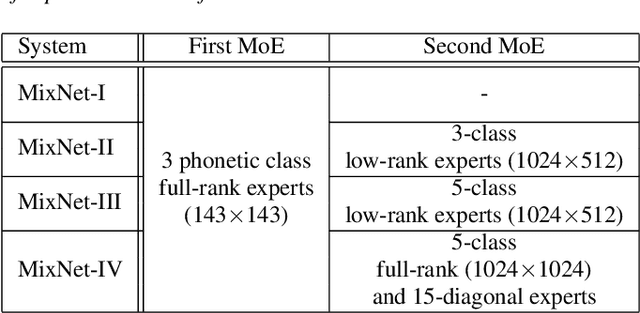
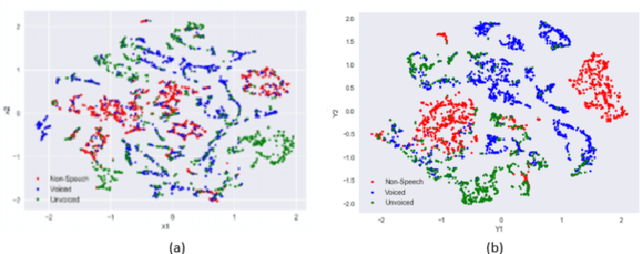
This paper presents a novel deep learning architecture for acoustic model in the context of Automatic Speech Recognition (ASR), termed as MixNet. Besides the conventional layers, such as fully connected layers in DNN-HMM and memory cells in LSTM-HMM, the model uses two additional layers based on Mixture of Experts (MoE). The first MoE layer operating at the input is based on pre-defined broad phonetic classes and the second layer operating at the penultimate layer is based on automatically learned acoustic classes. In natural speech, overlap in distribution across different acoustic classes is inevitable, which leads to inter-class mis-classification. The ASR accuracy is expected to improve if the conventional architecture of acoustic model is modified to make them more suitable to account for such overlaps. MixNet is developed keeping this in mind. Analysis conducted by means of scatter diagram verifies that MoE indeed improves the separation between classes that translates to better ASR accuracy. Experiments are conducted on a large vocabulary ASR task which show that the proposed architecture provides 13.6% and 10.0% relative reduction in word error rates compared to the conventional models, namely, DNN and LSTM respectively, trained using sMBR criteria. In comparison to an existing method developed for phone-classification (by Eigen et al), our proposed method yields a significant improvement.
A higher order Minkowski loss for improved prediction ability of acoustic model in ASR
Dec 02, 2021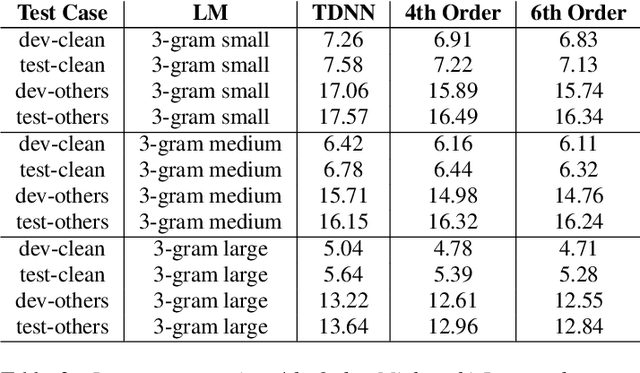
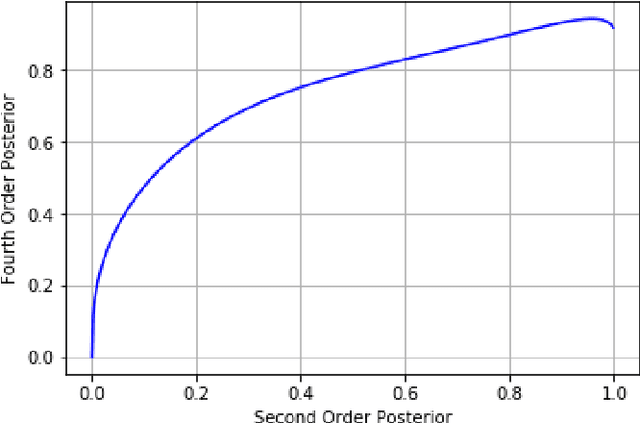
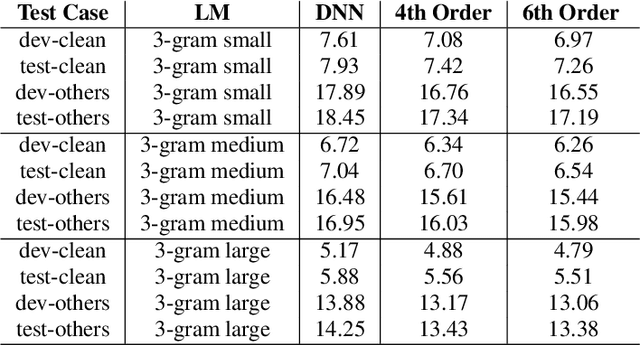
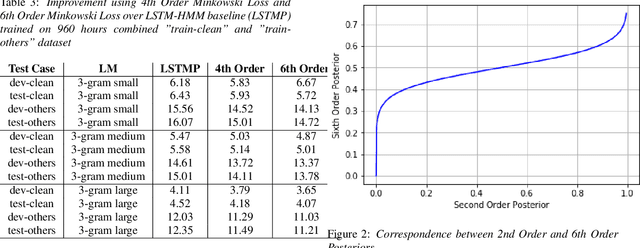
Conventional automatic speech recognition (ASR) system uses second-order minkowski loss during inference time which is suboptimal as it incorporates only first order statistics in posterior estimation [2]. In this paper we have proposed higher order minkowski loss (4th Order and 6th Order) during inference time, without any changes during training time. The main contribution of the paper is to show that higher order loss uses higher order statistics in posterior estimation, which improves the prediction ability of acoustic model in ASR system. We have shown mathematically that posterior probability obtained due to higher order loss is function of second order posterior and thus the method can be incorporated in standard ASR system in an easy manner. It is to be noted that all changes are proposed during test(inference) time, we do not make any change in any training pipeline. Multiple baseline systems namely, TDNN1, TDNN2, DNN and LSTM are developed to verify the improvement incurred due to higher order minkowski loss. All experiments are conducted on LibriSpeech dataset and performance metrics are word error rate (WER) on "dev-clean", "test-clean", "dev-other" and "test-other" datasets.
SRIB Submission to Interspeech 2021 DiCOVA Challenge
Jun 15, 2021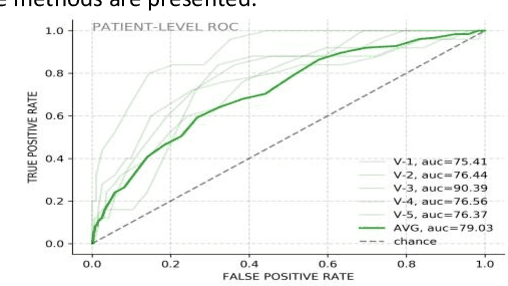
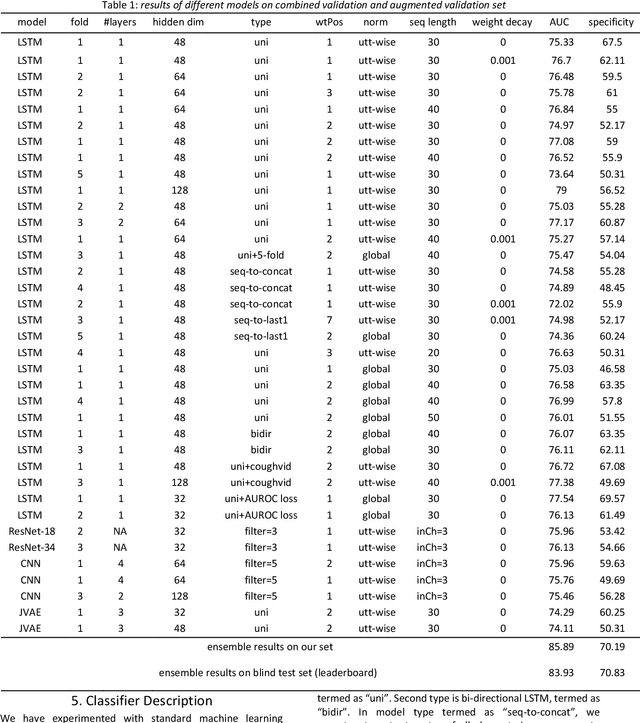
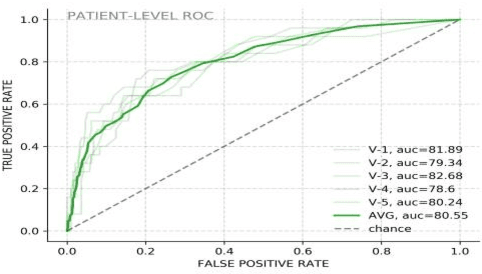
The COVID-19 pandemic has resulted in more than 125 million infections and more than 2.7 million casualties. In this paper, we attempt to classify covid vs non-covid cough sounds using signal processing and deep learning methods. Air turbulence, the vibration of tissues, movement of fluid through airways, opening, and closure of glottis are some of the causes for the production of the acoustic sound signals during cough. Does the COVID-19 alter the acoustic characteristics of breath, cough, and speech sounds produced through the respiratory system? This is an open question waiting for answers. In this paper, we incorporated novel data augmentation methods for cough sound augmentation and multiple deep neural network architectures and methods along with handcrafted features. Our proposed system gives 14% absolute improvement in area under the curve (AUC). The proposed system is developed as part of Interspeech 2021 special sessions and challenges viz. diagnosing of COVID-19 using acoustics (DiCOVA). Our proposed method secured the 5th position on the leaderboard among 29 participants.