 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Mixture of Expert Based Deep Neural Network for Improved ASR
Paper and Code
Dec 02, 2021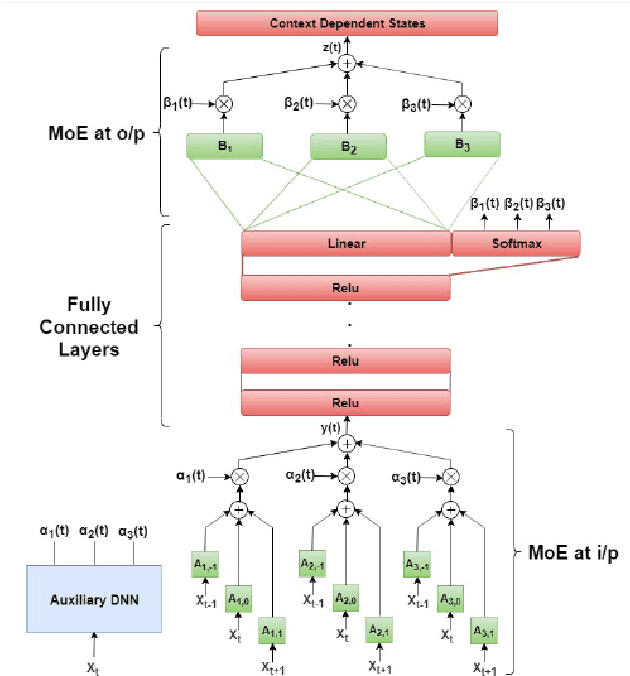
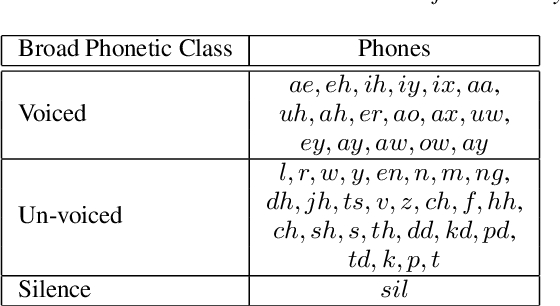
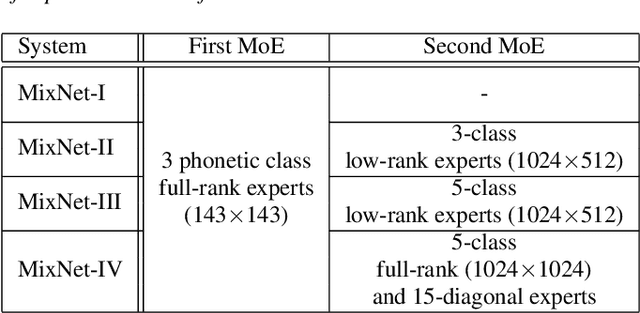
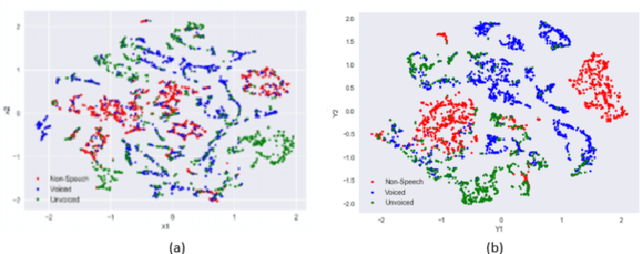
This paper presents a novel deep learning architecture for acoustic model in the context of Automatic Speech Recognition (ASR), termed as MixNet. Besides the conventional layers, such as fully connected layers in DNN-HMM and memory cells in LSTM-HMM, the model uses two additional layers based on Mixture of Experts (MoE). The first MoE layer operating at the input is based on pre-defined broad phonetic classes and the second layer operating at the penultimate layer is based on automatically learned acoustic classes. In natural speech, overlap in distribution across different acoustic classes is inevitable, which leads to inter-class mis-classification. The ASR accuracy is expected to improve if the conventional architecture of acoustic model is modified to make them more suitable to account for such overlaps. MixNet is developed keeping this in mind. Analysis conducted by means of scatter diagram verifies that MoE indeed improves the separation between classes that translates to better ASR accuracy. Experiments are conducted on a large vocabulary ASR task which show that the proposed architecture provides 13.6% and 10.0% relative reduction in word error rates compared to the conventional models, namely, DNN and LSTM respectively, trained using sMBR criteria. In comparison to an existing method developed for phone-classification (by Eigen et al), our proposed method yields a significant improvement.