 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA higher order Minkowski loss for improved prediction ability of acoustic model in ASR
Paper and Code
Dec 02, 2021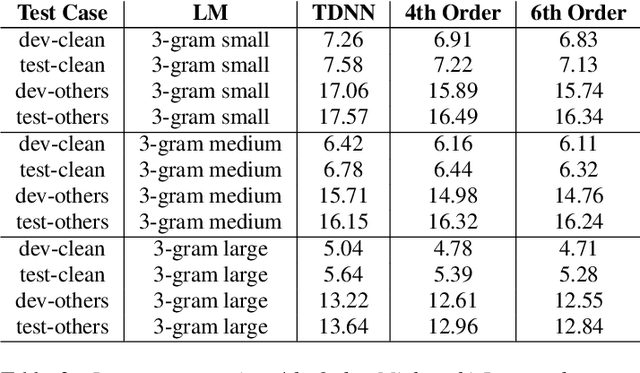
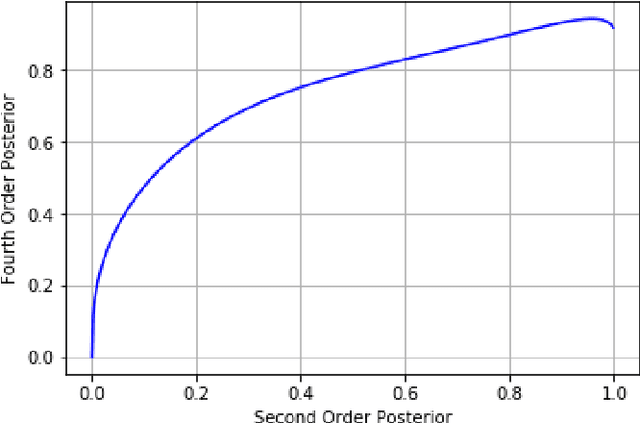
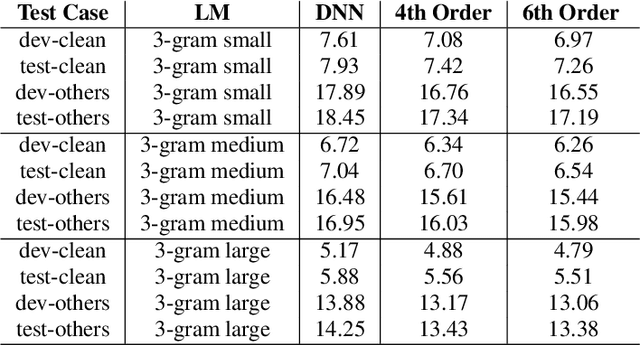
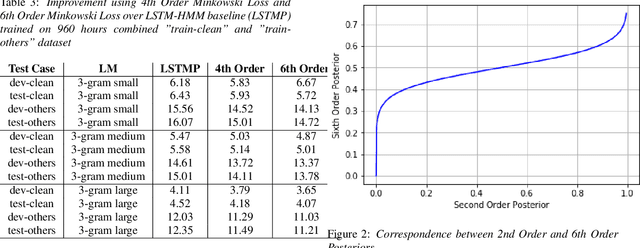
Conventional automatic speech recognition (ASR) system uses second-order minkowski loss during inference time which is suboptimal as it incorporates only first order statistics in posterior estimation [2]. In this paper we have proposed higher order minkowski loss (4th Order and 6th Order) during inference time, without any changes during training time. The main contribution of the paper is to show that higher order loss uses higher order statistics in posterior estimation, which improves the prediction ability of acoustic model in ASR system. We have shown mathematically that posterior probability obtained due to higher order loss is function of second order posterior and thus the method can be incorporated in standard ASR system in an easy manner. It is to be noted that all changes are proposed during test(inference) time, we do not make any change in any training pipeline. Multiple baseline systems namely, TDNN1, TDNN2, DNN and LSTM are developed to verify the improvement incurred due to higher order minkowski loss. All experiments are conducted on LibriSpeech dataset and performance metrics are word error rate (WER) on "dev-clean", "test-clean", "dev-other" and "test-other" datasets.