 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausal Analysis of ASR Errors for Children: Quantifying the Impact of Physiological, Cognitive, and Extrinsic Factors
Feb 12, 2025The increasing use of children's automatic speech recognition (ASR) systems has spurred research efforts to improve the accuracy of models designed for children's speech in recent years. The current approach utilizes either open-source speech foundation models (SFMs) directly or fine-tuning them with children's speech data. These SFMs, whether open-source or fine-tuned for children, often exhibit higher word error rates (WERs) compared to adult speech. However, there is a lack of systemic analysis of the cause of this degraded performance of SFMs. Understanding and addressing the reasons behind this performance disparity is crucial for improving the accuracy of SFMs for children's speech. Our study addresses this gap by investigating the causes of accuracy degradation and the primary contributors to WER in children's speech. In the first part of the study, we conduct a comprehensive benchmarking study on two self-supervised SFMs (Wav2Vec2.0 and Hubert) and two weakly supervised SFMs (Whisper and MMS) across various age groups on two children speech corpora, establishing the raw data for the causal inference analysis in the second part. In the second part of the study, we analyze the impact of physiological factors (age, gender), cognitive factors (pronunciation ability), and external factors (vocabulary difficulty, background noise, and word count) on SFM accuracy in children's speech using causal inference. The results indicate that physiology (age) and particular external factor (number of words in audio) have the highest impact on accuracy, followed by background noise and pronunciation ability. Fine-tuning SFMs on children's speech reduces sensitivity to physiological and cognitive factors, while sensitivity to the number of words in audio persists. Keywords: Children's ASR, Speech Foundational Models, Causal Inference, Physiology, Cognition, Pronunciation
Deep Learning for Pathological Speech: A Survey
Jan 07, 2025
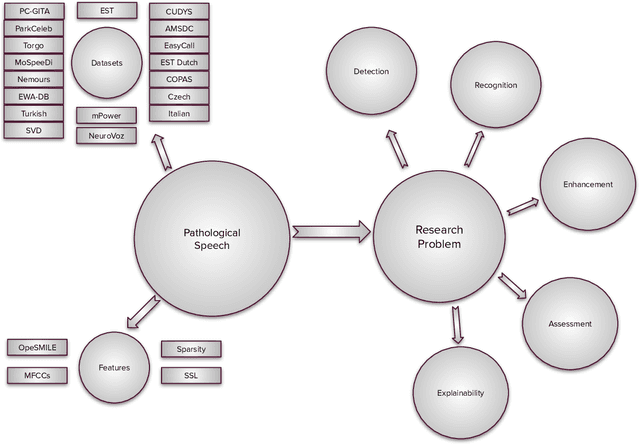

Advancements in spoken language technologies for neurodegenerative speech disorders are crucial for meeting both clinical and technological needs. This overview paper is vital for advancing the field, as it presents a comprehensive review of state-of-the-art methods in pathological speech detection, automatic speech recognition, pathological speech intelligibility enhancement, intelligibility and severity assessment, and data augmentation approaches for pathological speech. It also high-lights key challenges, such as ensuring robustness, privacy, and interpretability. The paper concludes by exploring promising future directions, including the adoption of multimodal approaches and the integration of graph neural networks and large language models to further advance speech technology for neurodegenerative speech disorders
ROAR: Reinforcing Original to Augmented Data Ratio Dynamics for Wav2Vec2.0 Based ASR
Jun 14, 2024



While automatic speech recognition (ASR) greatly benefits from data augmentation, the augmentation recipes themselves tend to be heuristic. In this paper, we address one of the heuristic approach associated with balancing the right amount of augmented data in ASR training by introducing a reinforcement learning (RL) based dynamic adjustment of original-to-augmented data ratio (OAR). Unlike the fixed OAR approach in conventional data augmentation, our proposed method employs a deep Q-network (DQN) as the RL mechanism to learn the optimal dynamics of OAR throughout the wav2vec2.0 based ASR training. We conduct experiments using the LibriSpeech dataset with varying amounts of training data, specifically, the 10Min, 1H, 10H, and 100H splits to evaluate the efficacy of the proposed method under different data conditions. Our proposed method, on average, achieves a relative improvement of 4.96% over the open-source wav2vec2.0 base model on standard LibriSpeech test sets.
* Accepted: Interspeech 2024
A Novel Windowing Technique for Efficient Computation of MFCC for Speaker Recognition
Jun 12, 2012



In this paper, we propose a novel family of windowing technique to compute Mel Frequency Cepstral Coefficient (MFCC) for automatic speaker recognition from speech. The proposed method is based on fundamental property of discrete time Fourier transform (DTFT) related to differentiation in frequency domain. Classical windowing scheme such as Hamming window is modified to obtain derivatives of discrete time Fourier transform coefficients. It has been mathematically shown that the slope and phase of power spectrum are inherently incorporated in newly computed cepstrum. Speaker recognition systems based on our proposed family of window functions are shown to attain substantial and consistent performance improvement over baseline single tapered Hamming window as well as recently proposed multitaper windowing technique.