 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompletely Unsupervised Phoneme Recognition By A Generative Adversarial Network Harmonized With Iteratively Refined Hidden Markov Models
Paper and Code
Apr 08, 2019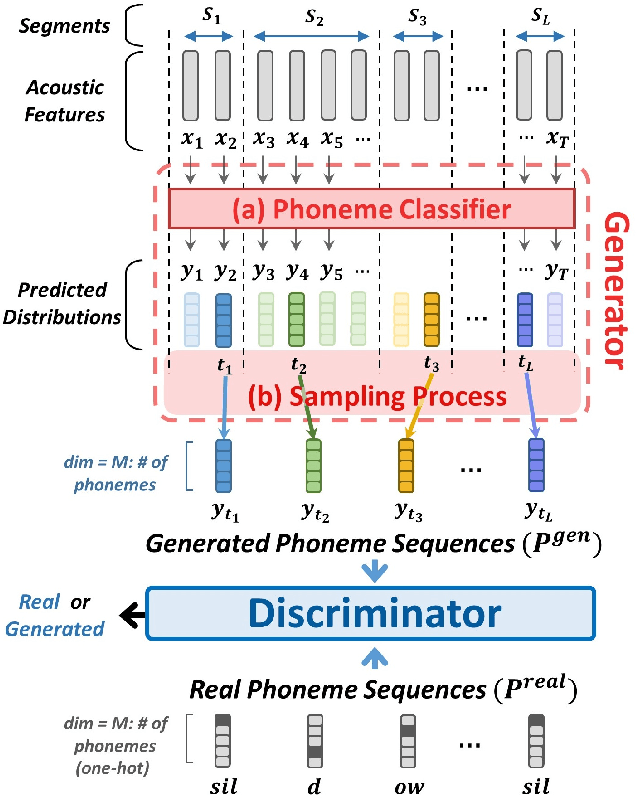
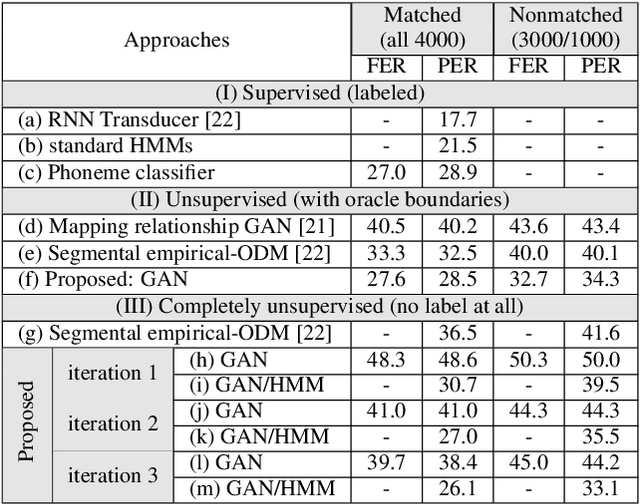
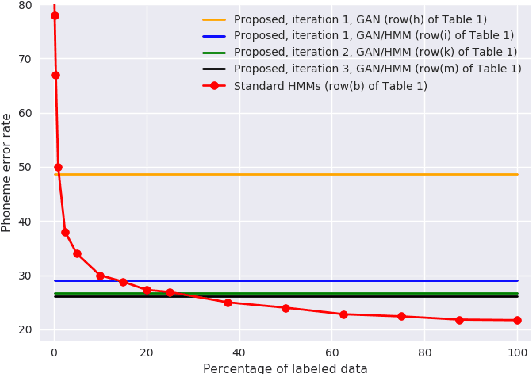
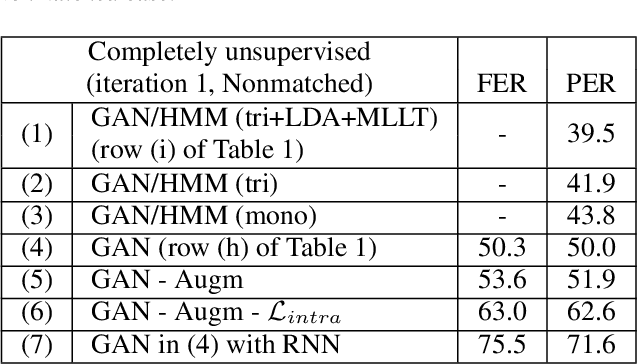
Producing a large annotated speech corpus for training ASR systems remains difficult for more than 95% of languages all over the world which are low-resourced, but collecting a relatively big unlabeled data set for such languages is more achievable. This is why some initial effort have been reported on completely unsupervised speech recognition learned from unlabeled data only, although with relatively high error rates. In this paper, we develop a Generative Adversarial Network (GAN) to achieve this purpose, in which a Generator and a Discriminator learn from each other iteratively to improve the performance. We further use a set of Hidden Markov Models (HMMs) iteratively refined from the machine generated labels to work in harmony with the GAN. The initial experiments on TIMIT data set achieve an phone error rate of 33.1%, which is 8.5% lower than the previous state-of-the-art.