 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLikelihood-based Differentiable Structure Learning
Oct 08, 2024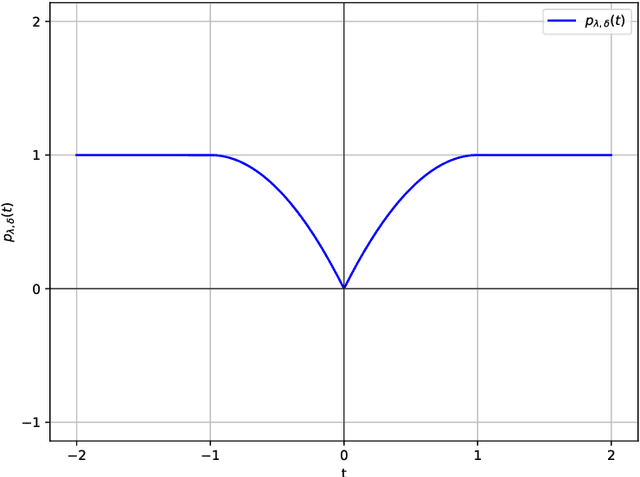
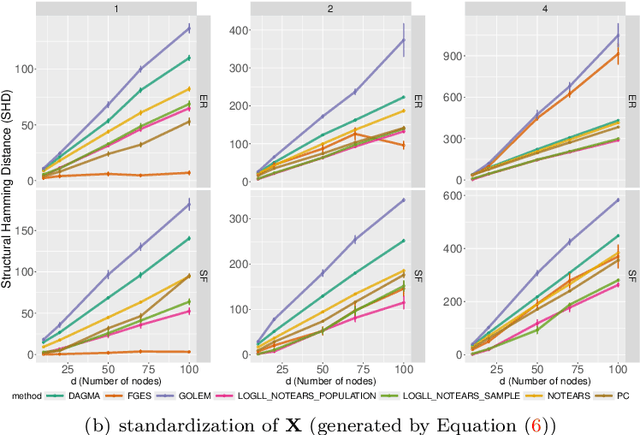
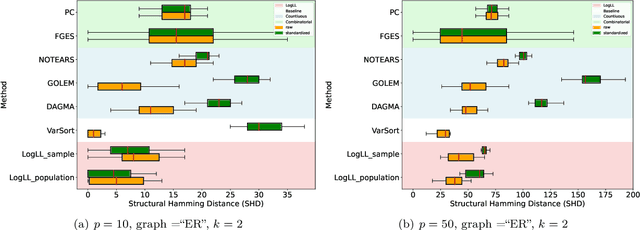
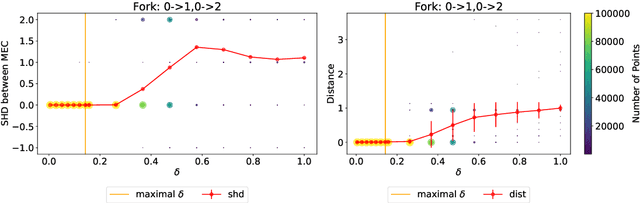
Existing approaches to differentiable structure learning of directed acyclic graphs (DAGs) rely on strong identifiability assumptions in order to guarantee that global minimizers of the acyclicity-constrained optimization problem identifies the true DAG. Moreover, it has been observed empirically that the optimizer may exploit undesirable artifacts in the loss function. We explain and remedy these issues by studying the behavior of differentiable acyclicity-constrained programs under general likelihoods with multiple global minimizers. By carefully regularizing the likelihood, it is possible to identify the sparsest model in the Markov equivalence class, even in the absence of an identifiable parametrization. We first study the Gaussian case in detail, showing how proper regularization of the likelihood defines a score that identifies the sparsest model. Assuming faithfulness, it also recovers the Markov equivalence class. These results are then generalized to general models and likelihoods, where the same claims hold. These theoretical results are validated empirically, showing how this can be done using standard gradient-based optimizers, thus paving the way for differentiable structure learning under general models and losses.
Global Optimality in Bivariate Gradient-based DAG Learning
Jun 30, 2023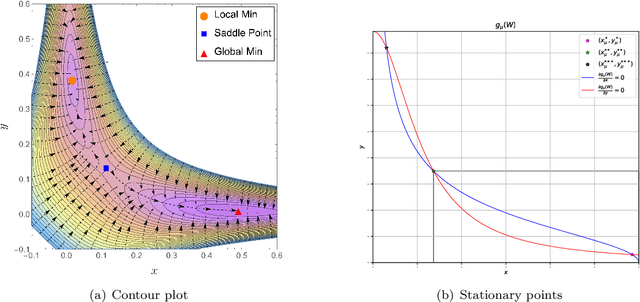
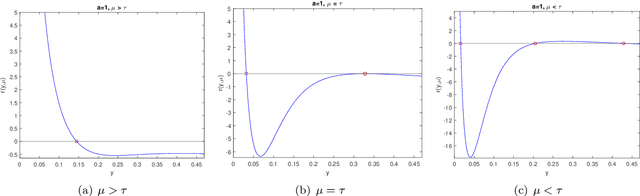
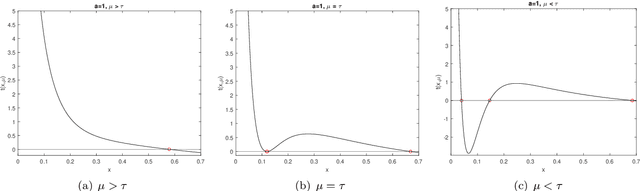
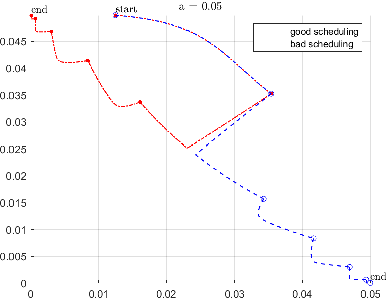
Recently, a new class of non-convex optimization problems motivated by the statistical problem of learning an acyclic directed graphical model from data has attracted significant interest. While existing work uses standard first-order optimization schemes to solve this problem, proving the global optimality of such approaches has proven elusive. The difficulty lies in the fact that unlike other non-convex problems in the literature, this problem is not "benign", and possesses multiple spurious solutions that standard approaches can easily get trapped in. In this paper, we prove that a simple path-following optimization scheme globally converges to the global minimum of the population loss in the bivariate setting.
Optimizing NOTEARS Objectives via Topological Swaps
May 26, 2023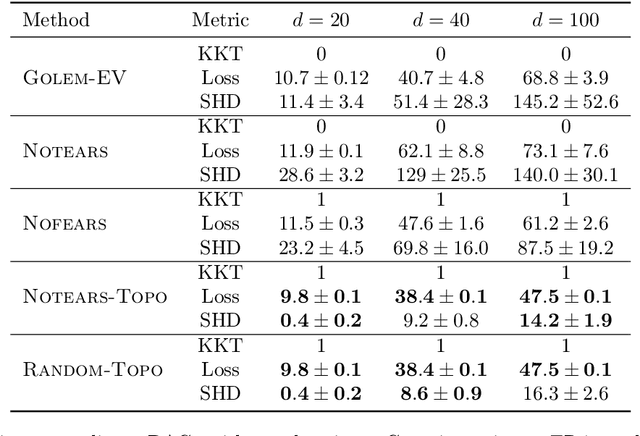

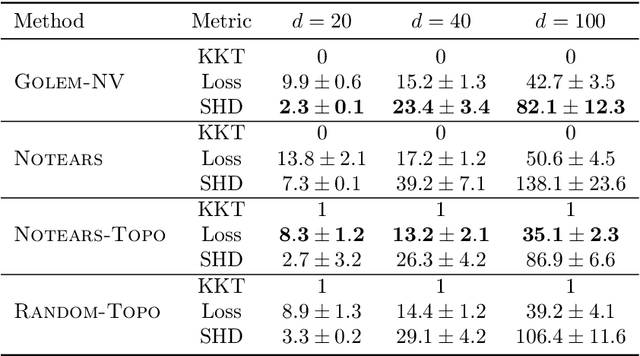

Recently, an intriguing class of non-convex optimization problems has emerged in the context of learning directed acyclic graphs (DAGs). These problems involve minimizing a given loss or score function, subject to a non-convex continuous constraint that penalizes the presence of cycles in a graph. In this work, we delve into the optimization challenges associated with this class of non-convex programs. To address these challenges, we propose a bi-level algorithm that leverages the non-convex constraint in a novel way. The outer level of the algorithm optimizes over topological orders by iteratively swapping pairs of nodes within the topological order of a DAG. A key innovation of our approach is the development of an effective method for generating a set of candidate swapping pairs for each iteration. At the inner level, given a topological order, we utilize off-the-shelf solvers that can handle linear constraints. The key advantage of our proposed algorithm is that it is guaranteed to find a local minimum or a KKT point under weaker conditions compared to previous work and finds solutions with lower scores. Extensive experiments demonstrate that our method outperforms state-of-the-art approaches in terms of achieving a better score. Additionally, our method can also be used as a post-processing algorithm to significantly improve the score of other algorithms. Code implementing the proposed method is available at https://github.com/duntrain/topo.
Simulation and Optimisation of Air Conditioning Systems using Machine Learning
Jun 27, 2020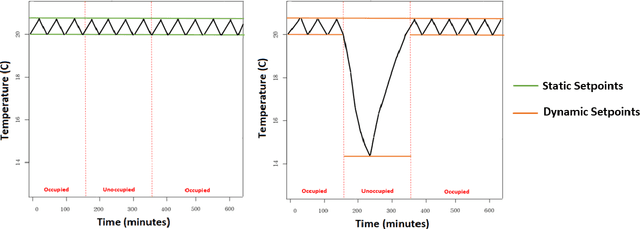
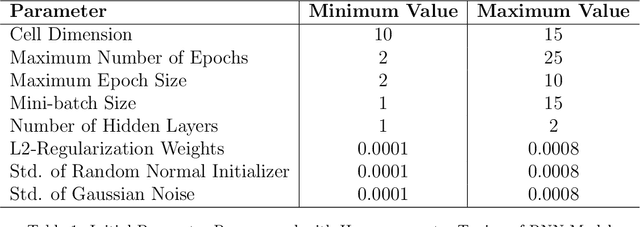


In building management, usually static thermal setpoints are used to maintain the inside temperature of a building at a comfortable level irrespective of its occupancy. This strategy can cause a massive amount of energy wastage and therewith increase energy related expenses. This paper explores how to optimise the setpoints used in a particular room during its unoccupied periods using machine learning approaches. We introduce a deep-learning model based on Recurrent Neural Networks (RNN) that can predict the temperatures of a future period directly where a particular room is unoccupied and by using these predicted temperatures, we define the optimal thermal setpoints to be used inside the room during the unoccupied period. We show that RNNs are particularly suitable for this learning task as they enable us to learn across many relatively short series, which is necessary to focus on particular operation modes of the air conditioning (AC) system. We evaluate the prediction accuracy of our RNN model against a set of state-of-the-art models and are able to outperform those by a large margin. We furthermore analyse the usage of our RNN model in optimising the energy consumption of an AC system in a real-world scenario using the temperature data from a university lecture theatre. Based on the simulations, we show that our RNN model can lead to savings around 20% compared with the traditional temperature controlling model that does not use optimisation techniques.
Deep Multi-Task Augmented Feature Learning via Hierarchical Graph Neural Network
Feb 12, 2020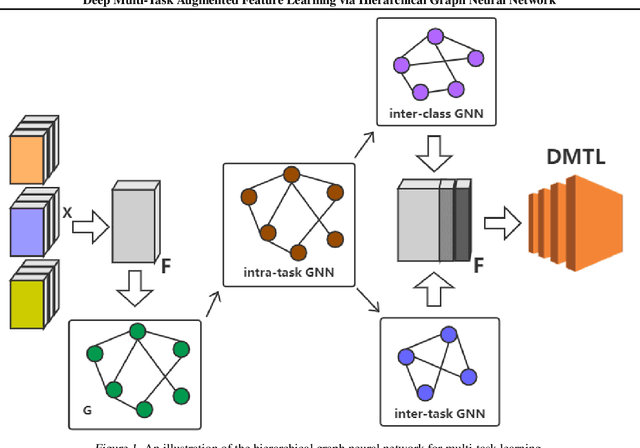

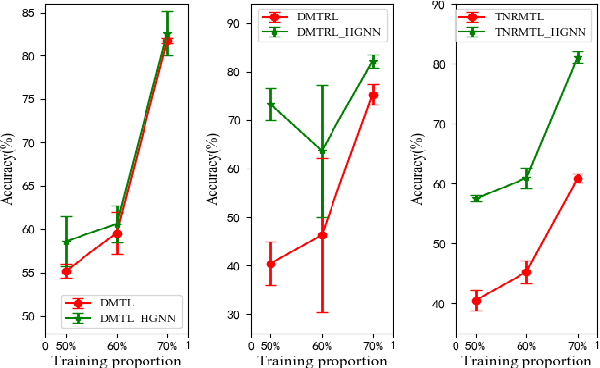

Deep multi-task learning attracts much attention in recent years as it achieves good performance in many applications. Feature learning is important to deep multi-task learning for sharing common information among tasks. In this paper, we propose a Hierarchical Graph Neural Network (HGNN) to learn augmented features for deep multi-task learning. The HGNN consists of two-level graph neural networks. In the low level, an intra-task graph neural network is responsible of learning a powerful representation for each data point in a task by aggregating its neighbors. Based on the learned representation, a task embedding can be generated for each task in a similar way to max pooling. In the second level, an inter-task graph neural network updates task embeddings of all the tasks based on the attention mechanism to model task relations. Then the task embedding of one task is used to augment the feature representation of data points in this task. Moreover, for classification tasks, an inter-class graph neural network is introduced to conduct similar operations on a finer granularity, i.e., the class level, to generate class embeddings for each class in all the tasks use class embeddings to augment the feature representation. The proposed feature augmentation strategy can be used in many deep multi-task learning models. we analyze the HGNN in terms of training and generalization losses. Experiments on real-world datastes show the significant performance improvement when using this strategy.